


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Streamlined convolution computing architecture design method and residual network acceleration system
A technology of computing architecture and design method, applied in the direction of neural architecture, neural learning method, biological neural network model, etc., can solve the problems of high hardware resource utilization, unrealizable, and inability to fully utilize parallelism, etc., to reduce memory access delay , enhance parallelism, and avoid the effect of multiple accesses to external memory
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
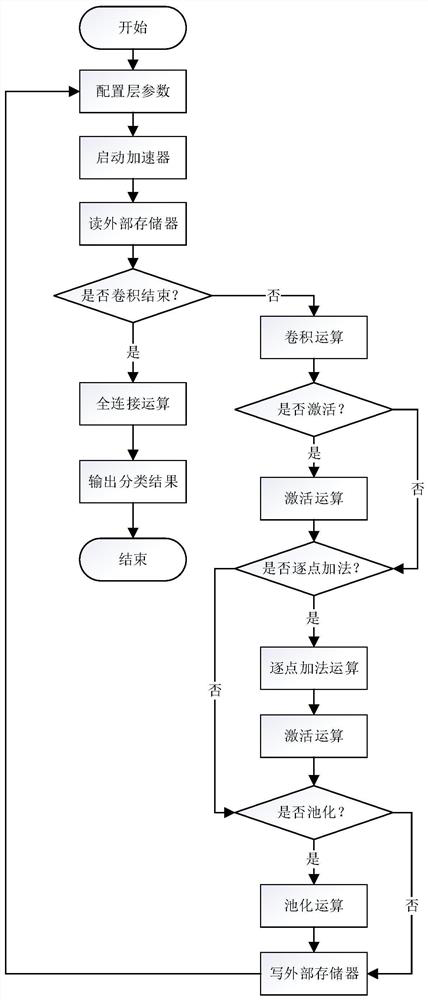
[0036] Such as image 3 As shown, a design method of a pipelined convolution computing architecture includes the following steps:
[0037] S1: The hardware acceleration architecture is divided into an on-chip buffer, a convolution processing array, and a point-by-point addition module;
[0038] S2: The main route of the hardware acceleration architecture is composed of three serially arranged convolution processing arrays, and two pipeline buffers are inserted between them to realize the interlayer pipeline of the three-layer convolution of the main route. The pipeline buffer is set in the on-chip buffer;
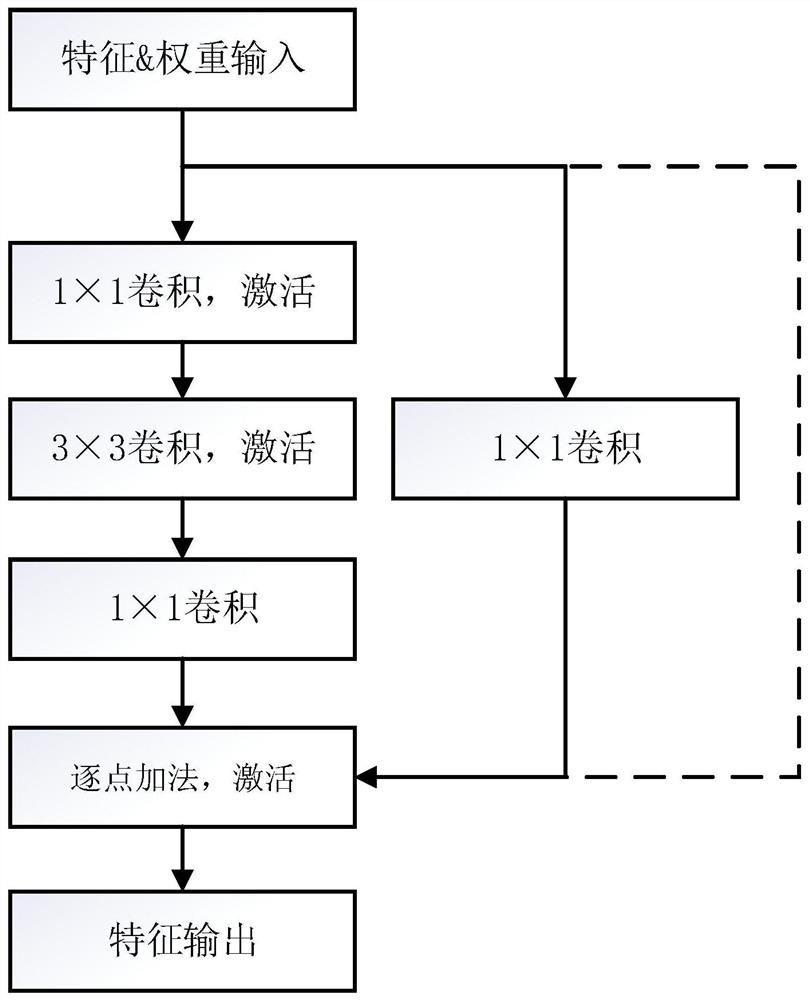
[0039] S3: Set the fourth convolution processing array for parallel processing of the convolutional layer with a kernel size of 1×1 for the branch of the residual building block, and change its working mode by configuring the registers in the fourth convolution processing array to make it available For calculating the convolutional layer or fully connected layer at the he...
Embodiment 2
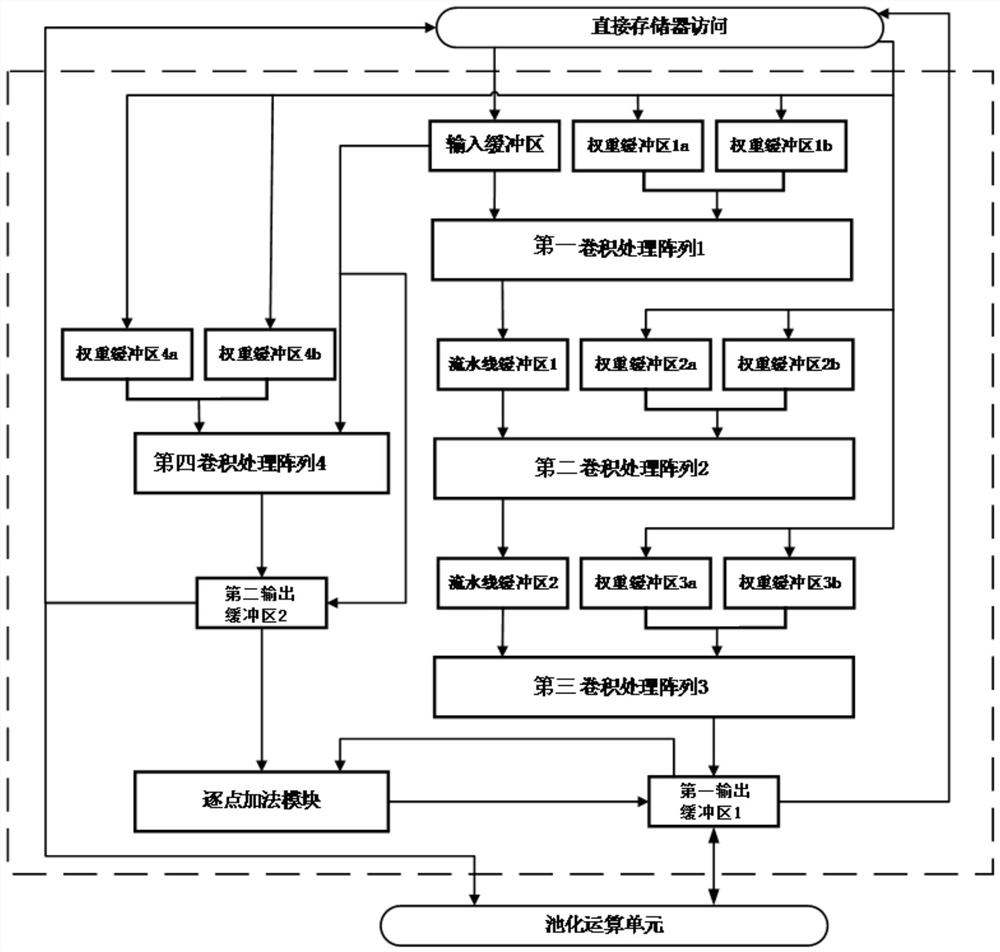
[0045] Such as Figure 5 As shown, a residual network accelerator system is designed using the pipelined convolution computing architecture design method, including: a direct memory access module, a pipelined convolution computing architecture module, a pooling operation unit, and a global control logic unit;
[0046] The direct memory access module sends the read data command to the off-chip memory, thereby transferring the data in the off-chip memory to the on-chip input buffer; sends the write data command to the off-chip memory, and calculates the final result obtained by the current residual building block The output feature writes data from the output buffer back to external memory;
[0047] The pooling operation unit is used to perform the average pooling operation or the maximum pooling operation; when the pooling operation needs to be performed, the pooling operation unit will read the feature data from the output buffer of the pipeline convolution computing architect...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com