


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Address fine tuning acceleration system
An acceleration system and address technology, applied in the field of address fine-tuning acceleration system, can solve the problems of lengthening the instruction pipeline length, and achieve the effects of avoiding inconsistent errors, saving bandwidth, and reducing dynamic power consumption
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

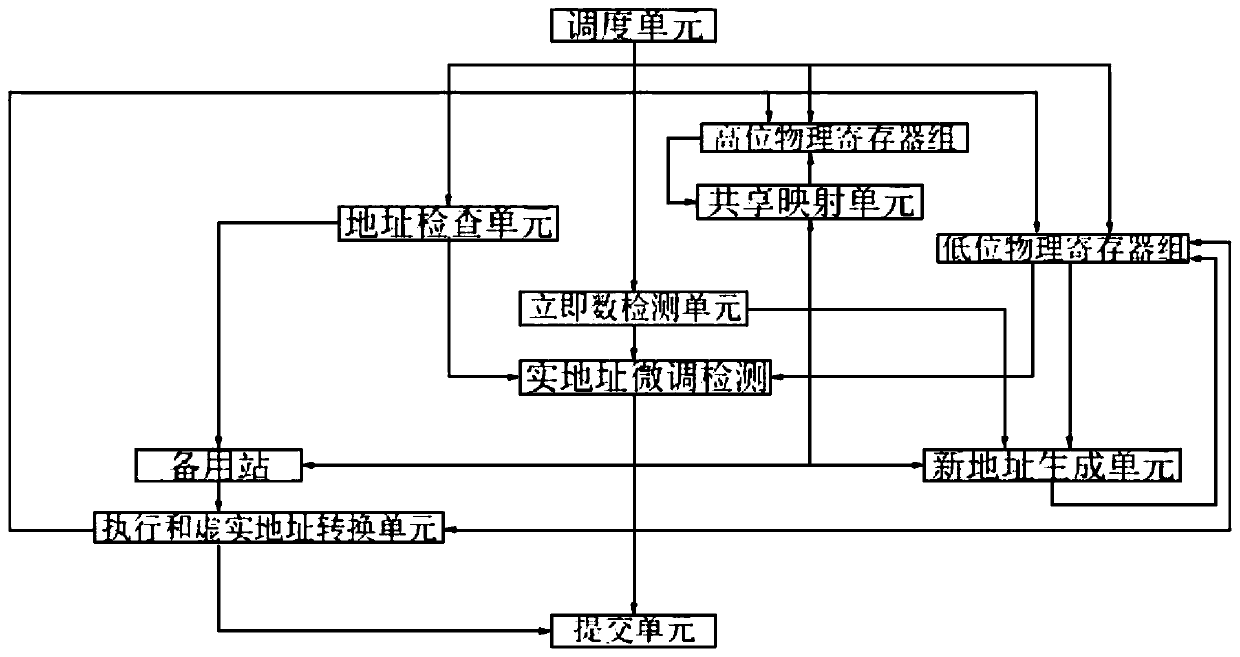
Examples
Embodiment 1
[0018] Every time the address generation instruction is written back, it is checked by the way whether the address is impossible to cross pages within a certain range, and two bits are used to indicate whether it will cross two adjacent pages. The range selection can be adjusted according to the frequency of fine-tuning the immediate data, if there is no bit corresponding to the risk of page crossing. After each address fine-tuning instruction reads the base address from the register group, if the immediate value is less than the safety distance, and the address conversion of the base address register is completed, the conversion result is directly read and assigned to its own address register, and the register group is selected to read at this time. The low-order address and the immediate value are operated, and the result is written back to the low-order address register. Another optional optimization method is to separate the high bits, page attributes, and low bits of the ...
Embodiment 2
[0020] In order to meet the need to open a separate submission channel for accelerated fine-tuning instructions, the retire unit can quickly see the completion of this instruction. So far, the requirements for this type of instruction pipeline trimming have been completed. Similarly, a separate write-back channel can also be opened, and the result can be sent to the memory access module. If a separate write-back channel is opened, then this type of instruction does not need to be pushed into the reservation station, and the instruction is completed ahead of schedule at the previous level, saving The bandwidth and capacity of station transmissions are reserved. If you consider the complexity brought by the additional write-back channel to the memory access module (more logic for address dependency detection), you can push this type of acceleration instruction into the reserved station, execute normally and convert the address, and give The write-back path of the memory access m...
Embodiment 3
[0022]Open up a separate submission and write-back path, so for the sequential fine-tuning and continuous memory access sequence, the effect is that only the initial address generation instruction needs general calculation and access to DTLB once, and all subsequent memory accesses without the risk of cross-page are all unnecessary Accessing DTLB again greatly saves pipeline power consumption and achieves the ultimate power consumption ratio optimization. Pay attention to a problem here. If the compiler guarantees that every time when changing the virtual and real address mapping or page attributes, when accessing a certain address in the page that has changed the mapping, there will be an address generation instruction in advance to update the mapping and page attributes. , then no special processing is required, and the mapping information and attributes of the same page can be safely used for each address fine-tuning instruction. But if it is not guaranteed, it means that i...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com