Sound source separation algorithm of end-to-end time domain multi-scale convolutional neural network
A convolutional neural network and multi-scale technology, applied in the field of sound source separation algorithms, can solve problems such as limiting applicability and increasing the minimum delay of the model, and achieve the goals of improving separation accuracy, processing speed, strong generalization ability and accuracy Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
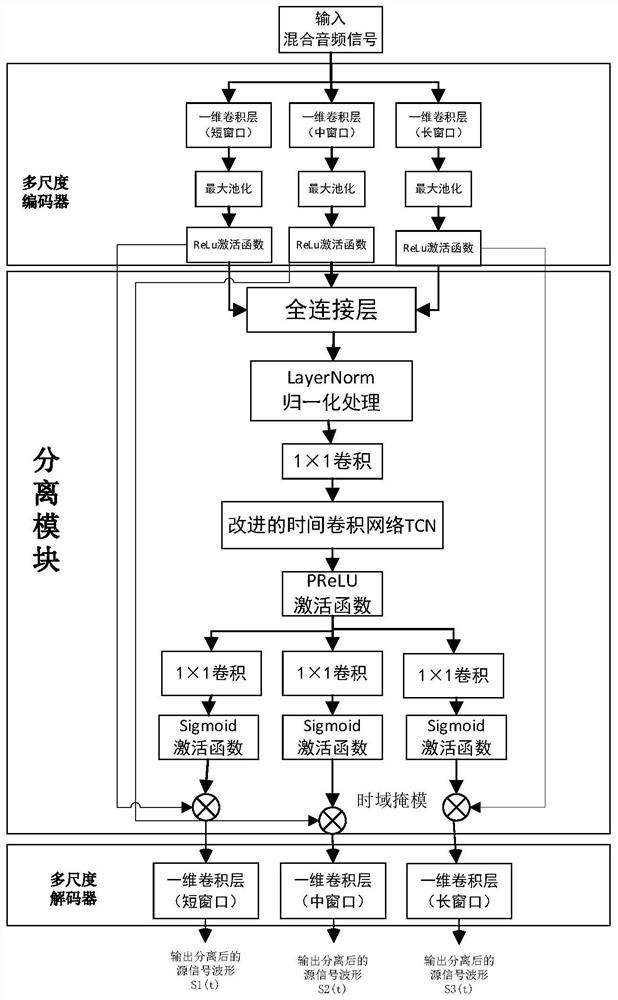
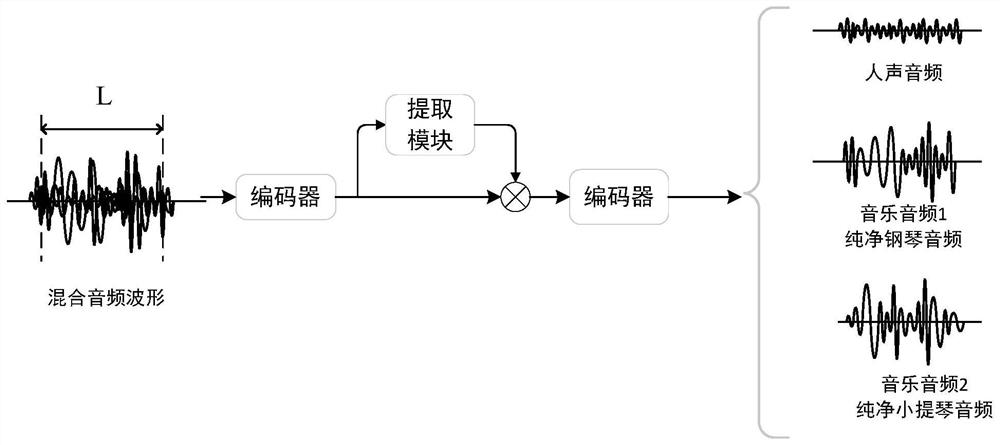
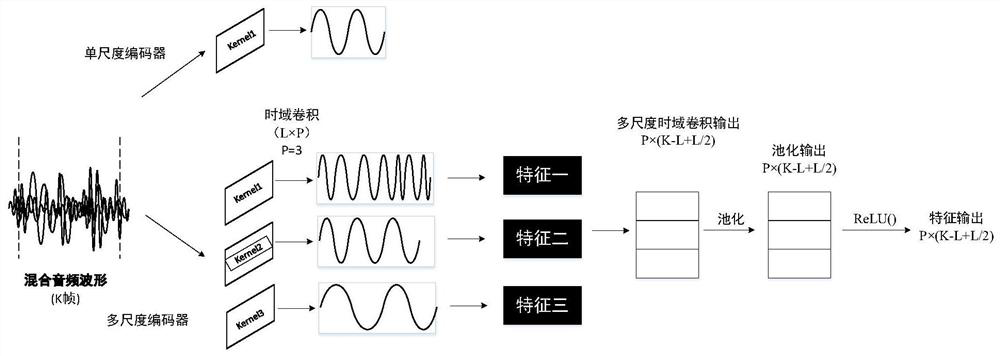
[0026] The end-to-end time-domain multi-scale convolutional neural network sound source separation algorithm method, the model is built with the technical background of convolutional neural network, gated linear unit, causal dilated convolution, residual module and depth separable convolutional network, the specific The flow chart of the sound source separation technology solution is shown in the accompanying drawings figure 1 .
[0027] The present invention will choose two kinds of musical instrument audio frequency and human voice audio data set as experimental object, select open source piano audio frequency (MAPS) data set, violin data set (Bash10), and human voice audio data set (MIR-1K) because the model has relatively Strong generalization ability, not only for the separation of sound sources of a specified musical instrument, so the data set can be replaced with the target data set that needs to be separated. The selected Piano Audio (MAPS) dataset contains piano aud...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com