Depth model compression method for edge device multi-layer shared codebook vector quantization
A codebook vector, edge device technology, applied in neural learning methods, biological neural network models, neural architectures, etc., can solve the problem of increasing the running time of vector quantization models, and achieve the goal of maintaining accuracy, reducing quantization loss, and reducing model size. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
[0044] The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings. Obviously, the described embodiments are only some, but not all, embodiments of the present invention.
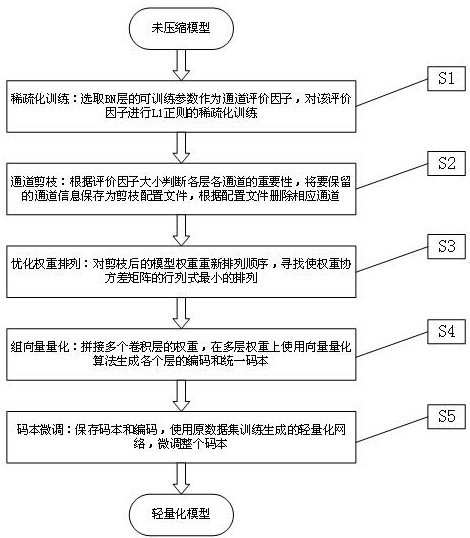
[0045] This embodiment discloses a deep model compression method for multi-layer shared codebook vector quantization for edge devices, such as figure 1 shown. For ease of understanding, this example uses the Pytorch deep learning framework to build and train a six-class neural network model with resnet18 as the backbone network. The original model size is 42.77MB, and its six-class accuracy rate is 98.96%. Compressing this network model involves the following 5 steps:
[0046] S1, sparse training: by figure 2 The sparse training shown is a part of channel pruning, and the trainable parameter γ of the BN layer in the network model is selected as the channel evaluation factor, where the output formula of the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com