Rapid batch detection method for A2 type beta casein content in milk
A technology for protein content and batch detection, which is applied in the direction of measuring devices, instruments, scientific instruments, etc., can solve the problems of long analysis time and high cost, and achieve the effects of improving detection efficiency, low-cost detection, and improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

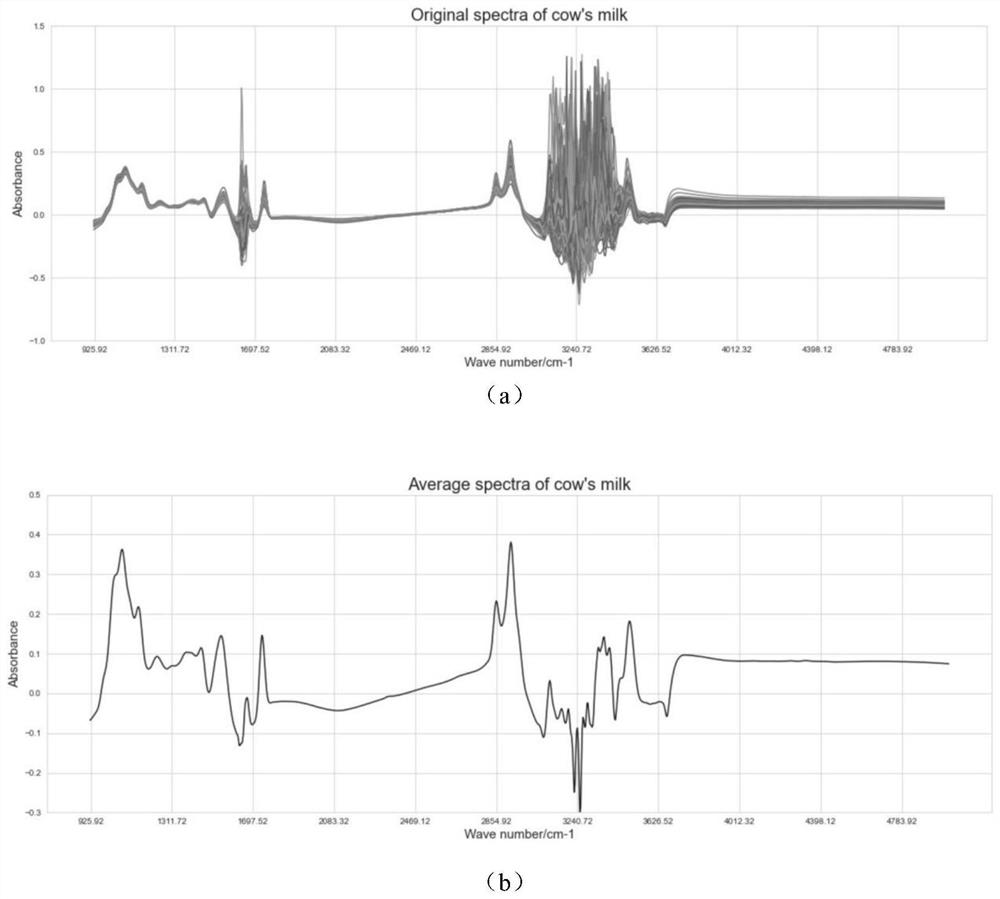
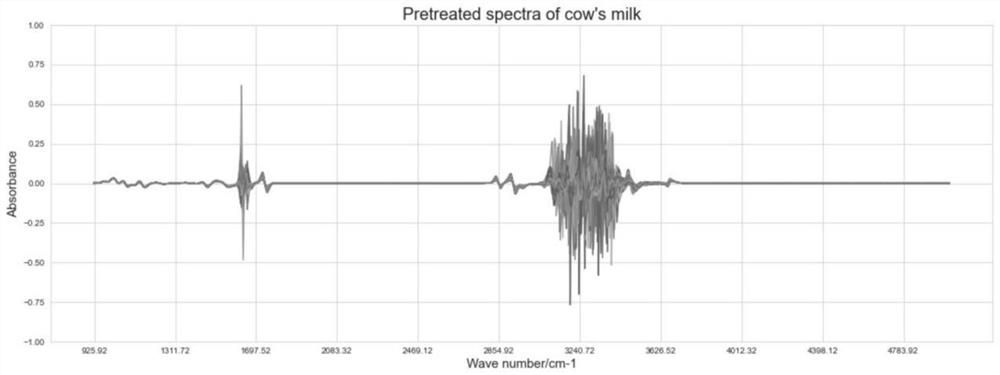
Examples
Embodiment 1
[0046] Choice of prediction model algorithm for A2-type beta casein:
[0047] The purpose of this application is to establish a quantitative determination model of A2-type beta casein in milk, so the modeling algorithm is a regression algorithm. There are many types of regression algorithms. This embodiment mainly uses Ridge regression (Ridge) and partial least squares regression (PLSR). [9] The algorithm builds and compares models for the following reasons:
[0048] Ridge regression is a type of linear regression. Only when the algorithm establishes the regression equation, the ridge regression adds the restriction of regularization, so as to achieve the effect of solving overfitting. There are two kinds of regularization, namely l1 regularization and l2 regularization. The advantages of l2 regularization compared to l1 regularization are: (1) cross-validation can be performed (2) stochastic gradient descent is realized. Ridge regression is a linear regression model after ...
Embodiment 2
[0051] Screening of the number of mid-infrared spectroscopy measurements and their usage:
[0052] In this embodiment, each sample corresponds to one piece of MIR spectral data. Substitute the full spectrum band for modeling, compare and analyze the accuracy of the model, and use diff1 (first-order difference) for preprocessing to determine the accuracy of the algorithm. The results are as follows:
[0053] Algorithm comparison results:
[0054]
[0055] After comparing the results of the two algorithms, PLSR has a better effect on the test set, and the over-fitting situation is weaker than that of the Ridge algorithm, so the PLSR algorithm is finally selected for modeling.
Embodiment 3
[0057] Establishment of a method for the detection of A2-type β-casein content in milk by mid-infrared spectroscopy:
[0058] 1. Division of the modeling dataset
[0059]
[0060] In the division of the modeling data set in this embodiment, 70% is the training set and 30% is the test set. The ratio of the training set to the test set is 7:3, and the training set is also called the cross-validation set. In the process of training the model, 10-fold cross-validation is performed.
[0061] 2. Screening of preprocessing methods for modeling MIR data
[0062] Effective feature screening is the basic operation of spectral data processing, the purpose is to eliminate noise and lay a solid foundation for feature extraction. There are three types of effective feature screening: feature extraction, feature preprocessing and feature dimensionality reduction. This embodiment mainly adopts five processing methods, such as SG (convolution smoothing), MSC (multiple scattering correctio...
PUM
| Property | Measurement | Unit |
|---|---|---|
| recovery rate | aaaaa | aaaaa |
Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com