Winograd convolution implementation method based on vector instruction acceleration calculation
An implementation method and vector technology, applied in the field of operation support systems, can solve problems such as the inability to meet the continuous requirements of memory read and write at the same time, and achieve the effects of avoiding suboptimality, improving computing performance, and improving computing performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0037] Specific embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings. It should be understood that the specific embodiments described here are only used to illustrate and explain the present invention, and are not intended to limit the present invention.
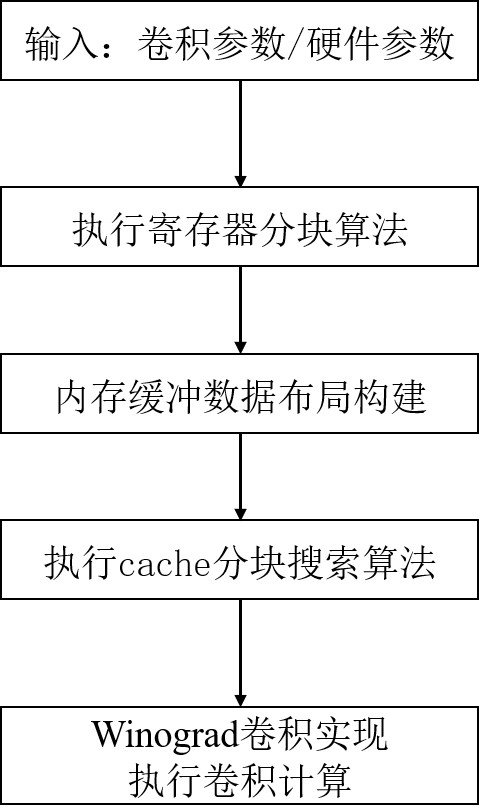
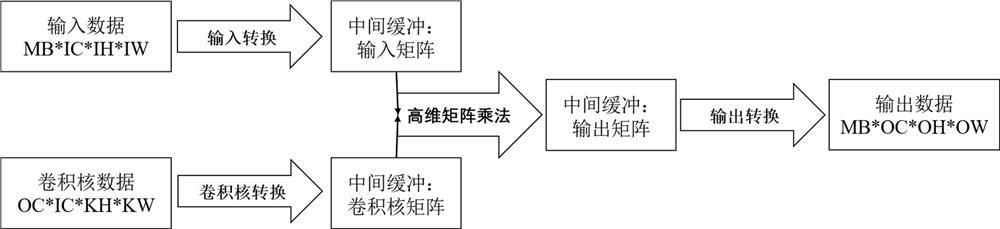
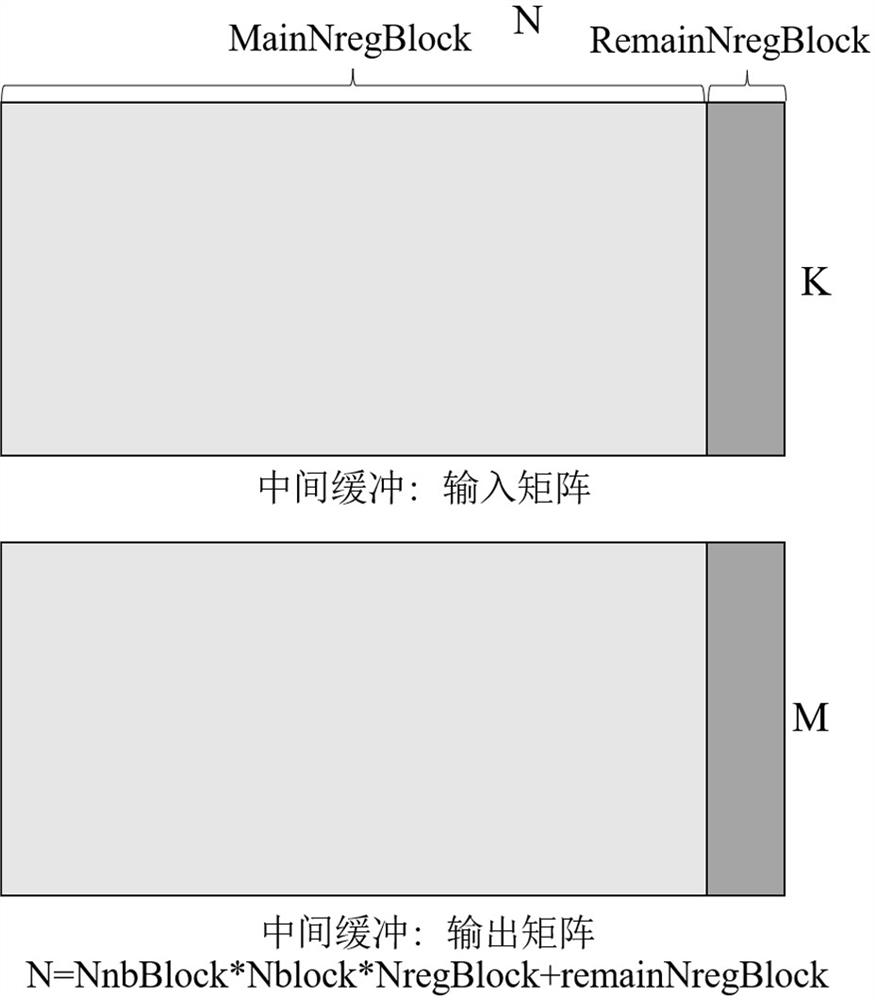
[0038] The invention proposes a Winograd convolution realization method on a CPU platform. Through in-depth research, it is found that there are many defects in the existing Winograd convolution implementation on the CPU. The present invention is based on the micro-architecture characteristics of the CPU, including vector registers and vector operation units, multi-core parallelism, multi-level cache, etc., to perform Winograd convolution. Fine-grained optimizations. The method proposed by the present invention can not only be used as a technical means for the server to use the existing CPU (without purchasing expensive GPU) to accelerate deep learning computin...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com