Cache auxiliary task cooperative unloading and resource allocation method based on meta reinforcement learning
A resource allocation and reinforcement learning technology, applied in the field of edge computing technology and reinforcement learning, can solve the problems of unguaranteed user experience and high load, and achieve the effects of fast computing offloading decisions, reducing energy consumption and delay, and improving computing performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0046] Embodiment 1 model establishment
[0047] The invention establishes a cache-assisted task cooperation unloading and resource allocation model in a mobile cooperative application scenario. The steps of model building are as follows:
[0048] 1 Edge environment: Group edge servers into cooperative clusters according to the geographical distribution of base stations. In a cooperative cluster, the edge nodes use the set express. Each edge server has cache and computing resources, Q m and C m Respectively represent the cache space capacity and maximum computing power of the edge node m. In order to better reuse the original data and calculation results in the calculation, a cache is added in each edge server. Based on the cache efficiency, the computing tasks executed on the edge server are cached and the cache status is obtained. If subsequent computing tasks need to use / get the same data, there is no need to repeat the transmission / computation.
[0049] 2 Computin...
Embodiment 2
[0088] Embodiment 2 algorithm design
[0089] In order to solve the above-mentioned Markov decision process, the present invention designs a seq2seq network fitting strategy function and value function based on a recurrent neural network. The network includes two parts of an encoder and a decoder, both of which are realized by a multilayer recurrent neural network. The network adopts a shared parameter network architecture, that is, the policy function and the value function share all network structures and parameters except the output layer (the policy function uses a softmax output layer; the value function uses a fully connected output layer). Embedding tasks into sequence T G =(task 1 , task 2 ,..., task |V| ) and offload scheduling decision history sequence A G =(a 1 , a 2 ,...,a i-1 ) into the network. The encoder sequentially inputs the task embedding sequence T G , outputting the features of the final hidden layer DAG. The decoder initializes its hidden layer...
Embodiment 3
[0117] Embodiment 3 algorithm flow
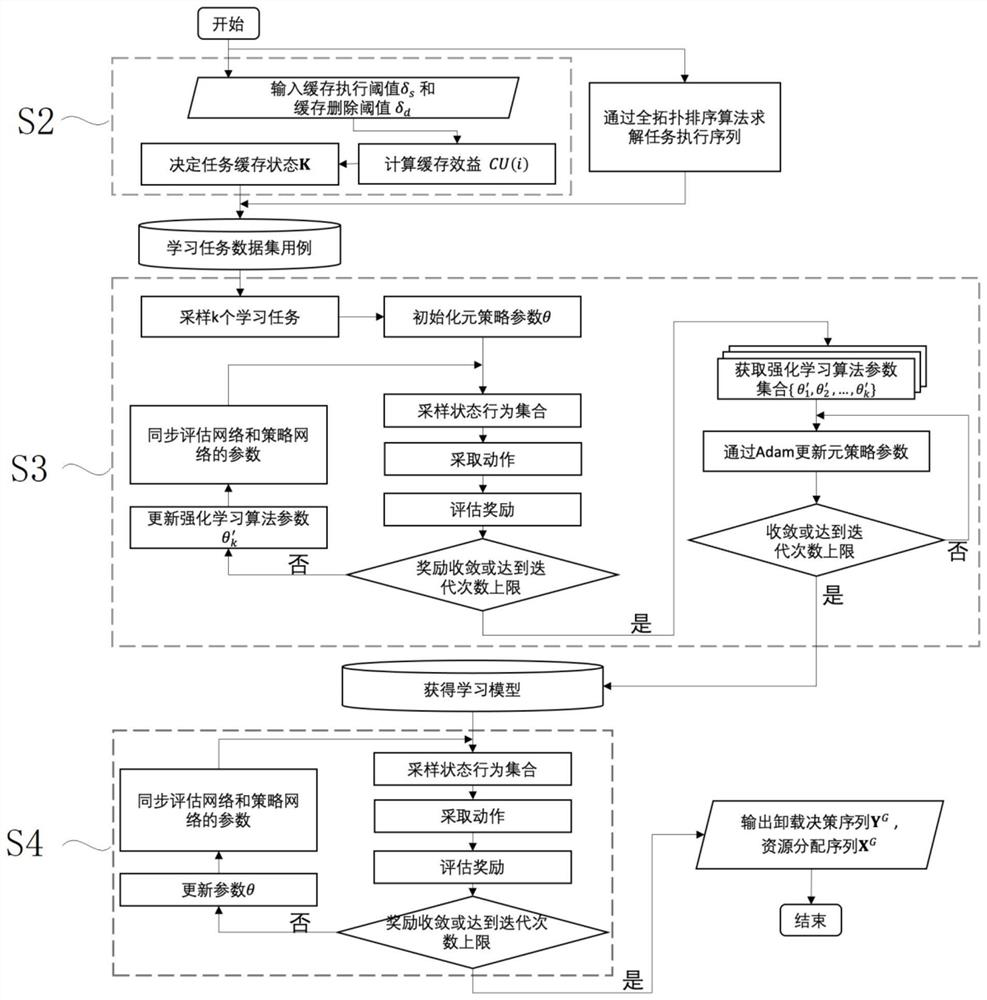
[0118] The present invention proposes a cache-assisted computing offloading method based on meta-reinforcement learning, which is divided into three stages: obtaining the cache state of the request task, obtaining the learning model (algorithm 2) and solving the unloading decision (algorithm 1). The overall idea is as figure 1 shown.
[0119] (1) Get task cache status
[0120] Step 1: Enter the cache execution threshold δ s and the cache removal threshold δ d . The field value determines whether to cache the task.
[0121] Step 2: Calculate the cache benefit CU(i). The smaller the storage space occupied, the greater the network income, and the higher the number of requests, the greater the value of the content cache utility.
[0122] Step 3: Determine the task cache state K. When the cache gain is greater than the execution threshold δ s When , cache it on the node of mobile edge computing; when the cache gain is less than delete δ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com