Column calculation optimization method based on Spark SQL
An optimization method and execution plan technology, applied in the field of SparkSQL-based column calculation optimization, to achieve the effect of reducing overhead, accelerating calculation speed, and reducing calculation time.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

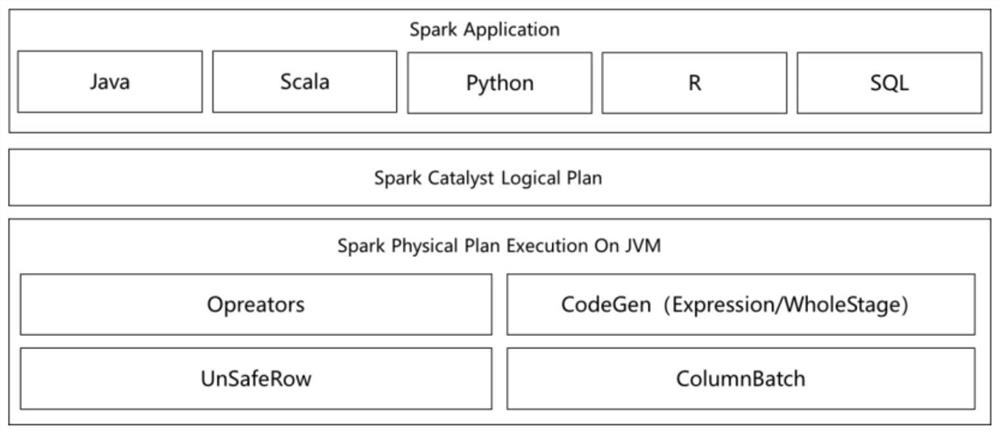
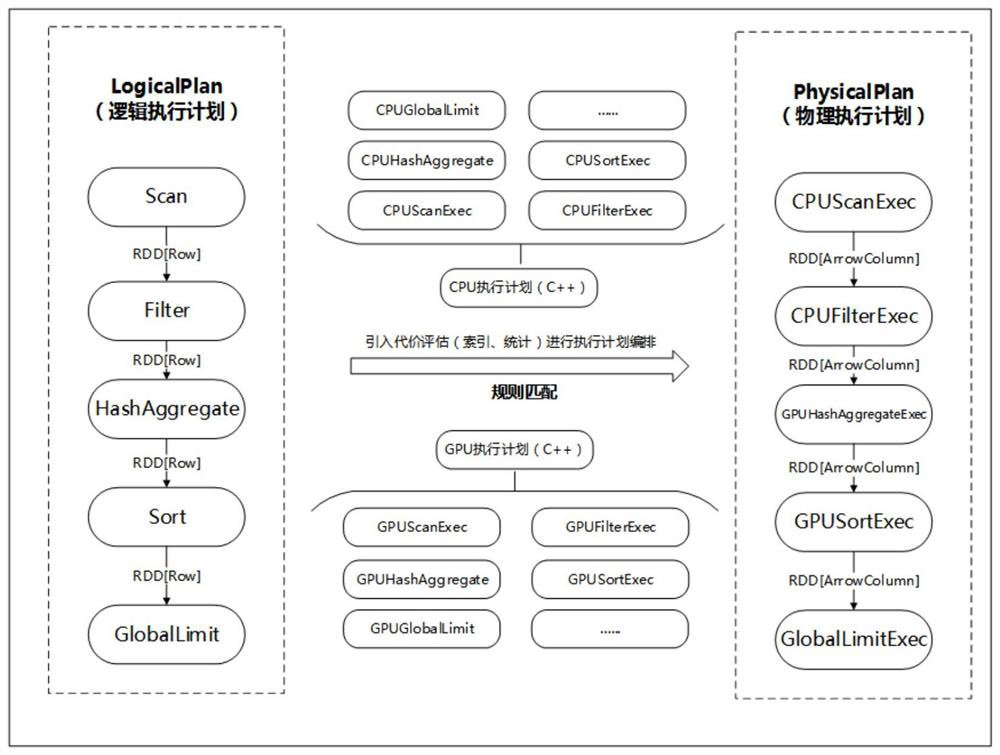
Examples
Embodiment
[0041] EXAMPLES: A column calculation optimization method based on Spark SQL, including the following steps:
[0042] S1, unified memory management, providing an Arrow unified data management mechanism, after file data is loaded from disk to memory Arrow structure, can be implemented by multiple plug-in access and calculation, calculating Shuffle, etc., is also based on arrow implementation. Use arrow as a carrier of RDD memory, implement memory data between multitasking, multi-plug-in;
[0043] S2, heterogeneous calculation resource unified scheduling, expand the optimizer and plugin in Spark SQL, implement data-based heterogeneous resource scheduling mechanism, including the steps:
[0044] S2-1, based on the schedule optimization mechanism of the field data characteristics: For numerical calculation priority schedule to CPU, feature vector data, long string computing GPU;
[0045] S2-2, the scheduling optimization of combined calculation characteristics: Task for a large amount...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com