Two-stage single-instance data de-duplication backup method
A data backup and single-instance technology, which is applied in the direction of electric digital data processing, special data processing applications, redundant data error detection in computing, etc., can solve the problem of heavy client workload, waste of time and bandwidth, and reduce query Speed and other issues
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
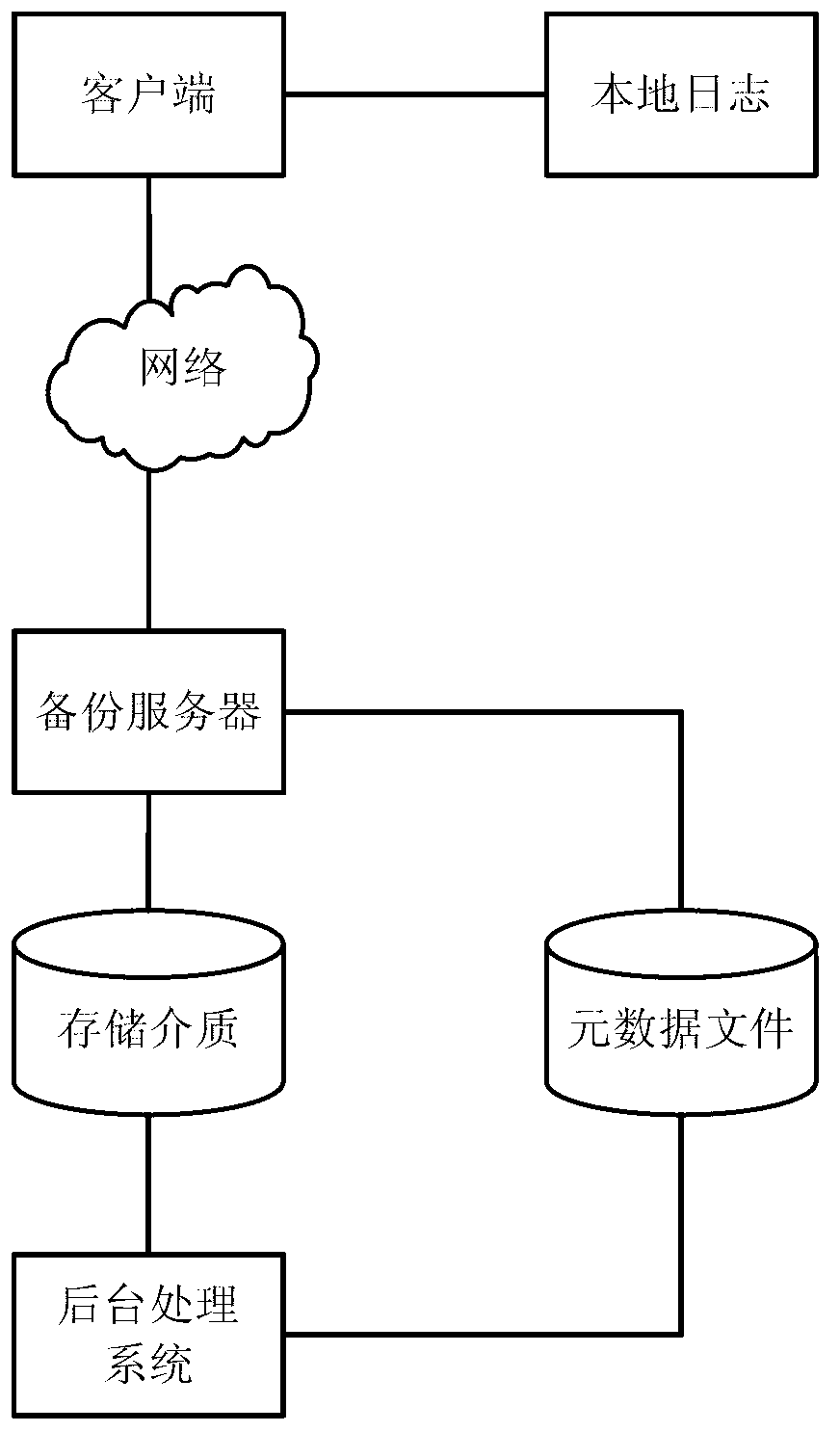
[0068] figure 1 Shown is the deployment implementation environment of this method. First, the deployment environment of this method is a C / S structure, including client and server. Local logs are saved on the client, and the logs record information and backups of files that users have saved. information about the task. The client interacts with the server through the network. The server side includes a backup server and a background processing system. The backup server saves the content of the backup file in a storage medium, and saves the metadata of the backup file into a metadata file. While the background processing system performs similar file classification and deduplication operations on files when the backup server is light or has no tasks, and deduplicates the files twice.
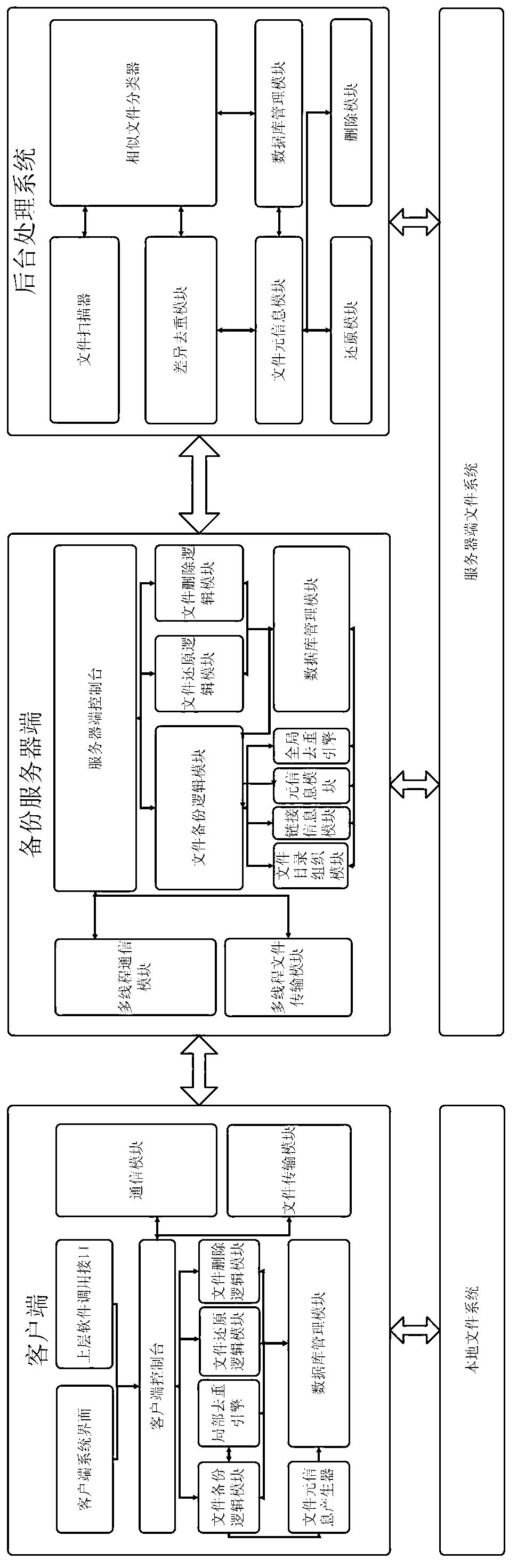
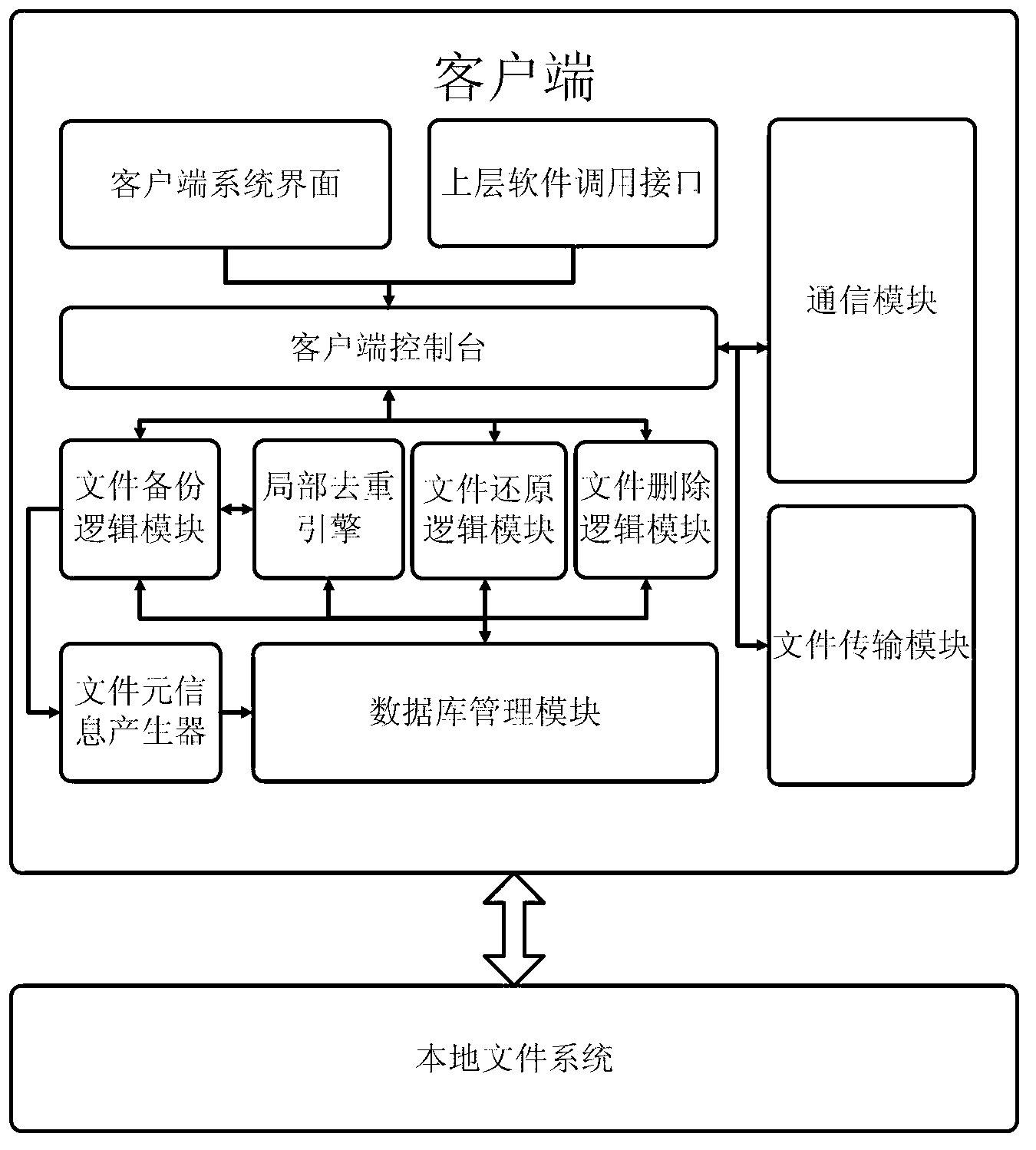
[0069] figure 2 Shown is the overall architecture diagram of this method, including three parts: client, backup server, and background processing system. The client processes local files. And...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com