Distributed parallel high-speed read-write system and method based on IPFS
A read-write system and distributed technology, applied in file systems, special data processing applications, instruments, etc., can solve problems such as write operation blocking, system availability impact, and system availability cannot be satisfied
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
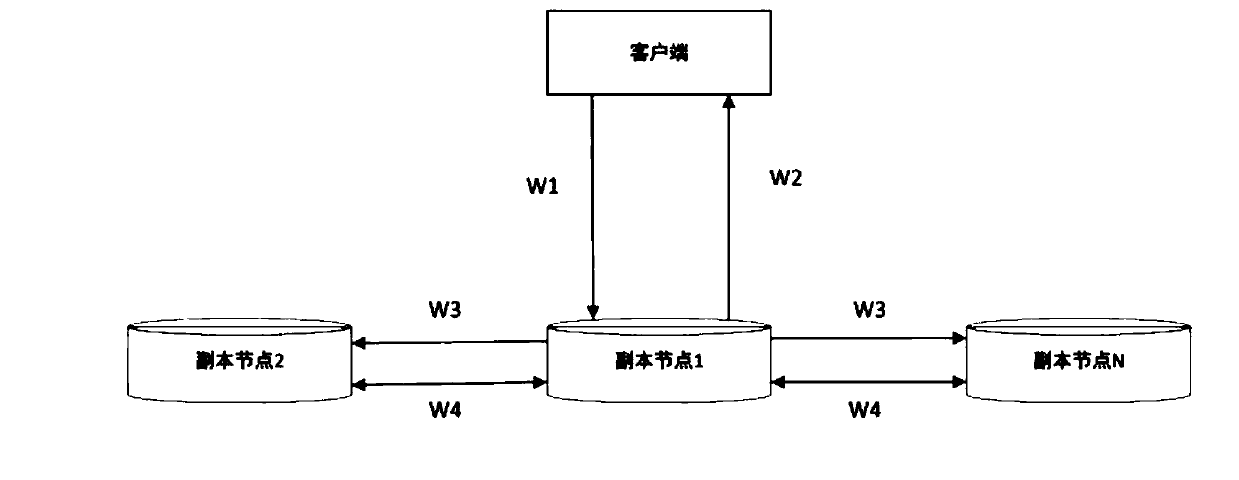
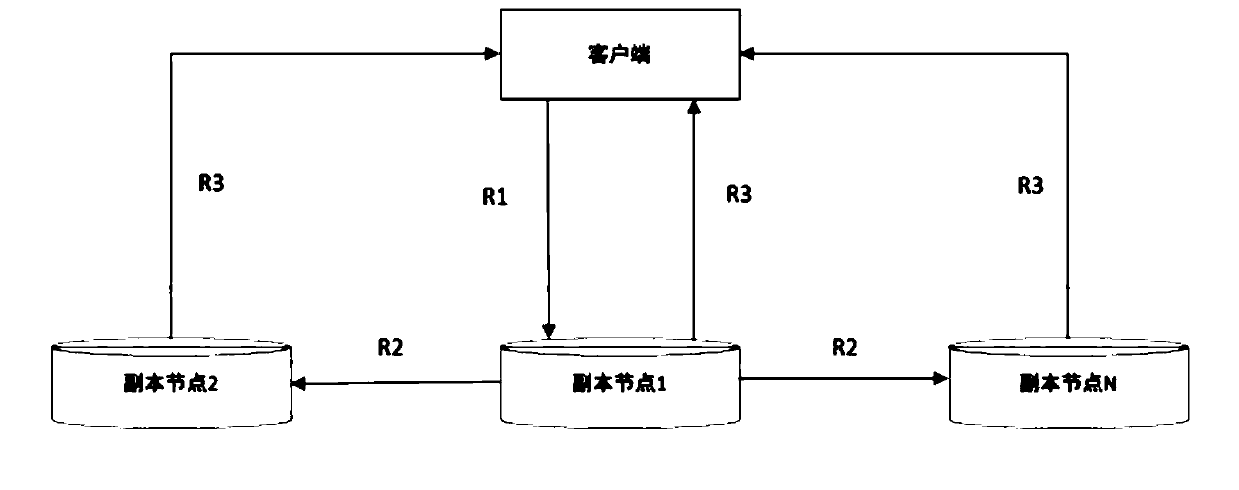
[0027] Such as figure 1 and figure 2 As shown, a distributed parallel high-speed reading and writing system based on IPFS includes: a client, a service control terminal, and several peer-to-peer distributed copy nodes; the service control terminal calculates each copy node according to the operating parameters of each copy node The recommended value of the node, according to the calculated recommended value, establishes the connection between the corresponding replica node with the highest recommended value and the client; after the client establishes a connection with the replica node, the data reading process and the data writing process are completed; The service control terminal calculates the recommended value of each replica node according to the operating parameters of each replica node, and according to the calculated recommended value, establishes the connection method between the replica node with the highest recommended value and the client to perform the following...
Embodiment 2
[0031] On the basis of the previous embodiment, after the client establishes a connection with the replica node, the process of writing data is completed and the following steps are performed: when the client sends data to the node, the node performs fixed-size slice processing on the received data , and generate a unique Hash value for each data block, and at the same time connect these data blocks with the data structure of Merkle directed acyclic graph, and generate a root Hash as the Hash identifier of the file; generate a data block Hash The root Hash algorithm is generated according to the actual content of the file data, and different files will generate different Hash values; after any node completes the writing of the file, it will return to the client, prompting that the data is written successfully; When , multiple nodes will write the task synchronously, and the nodes performing the writing task will slice the file and store it in the local data warehouse with the s...
Embodiment 3
[0036] On the basis of the previous embodiment, after the client establishes a connection with the replica node, the process of reading data is completed and the following steps are performed: the client initiates a read request through the data Hash value, and any node in the distributed storage system Can respond, when the response node has the required data, it will send the data to the client in units of data blocks of the file; when the response node executes the reading task, it will generate a list at the same time and broadcast it to the whole network; The form of the content hash list displays all the read task lists sent by the responding node client. After the node storing the data in the system receives the broadcast, it will directly transmit data with the client; The broadcast task is carried out at the same time, so in the process of the user reading the data, the nodes responding to the reading task gradually increase until the N value is reached, that is, all t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com