


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Video target detection method based on multi-layer feature fusion
A technology of target detection and feature fusion, applied in instruments, biological neural network models, character and pattern recognition, etc., can solve the problems of high computing resources, large amount of network parameters, and high model complexity, and achieve enhanced foreground features, Strong robustness, the effect of suppressing background features
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
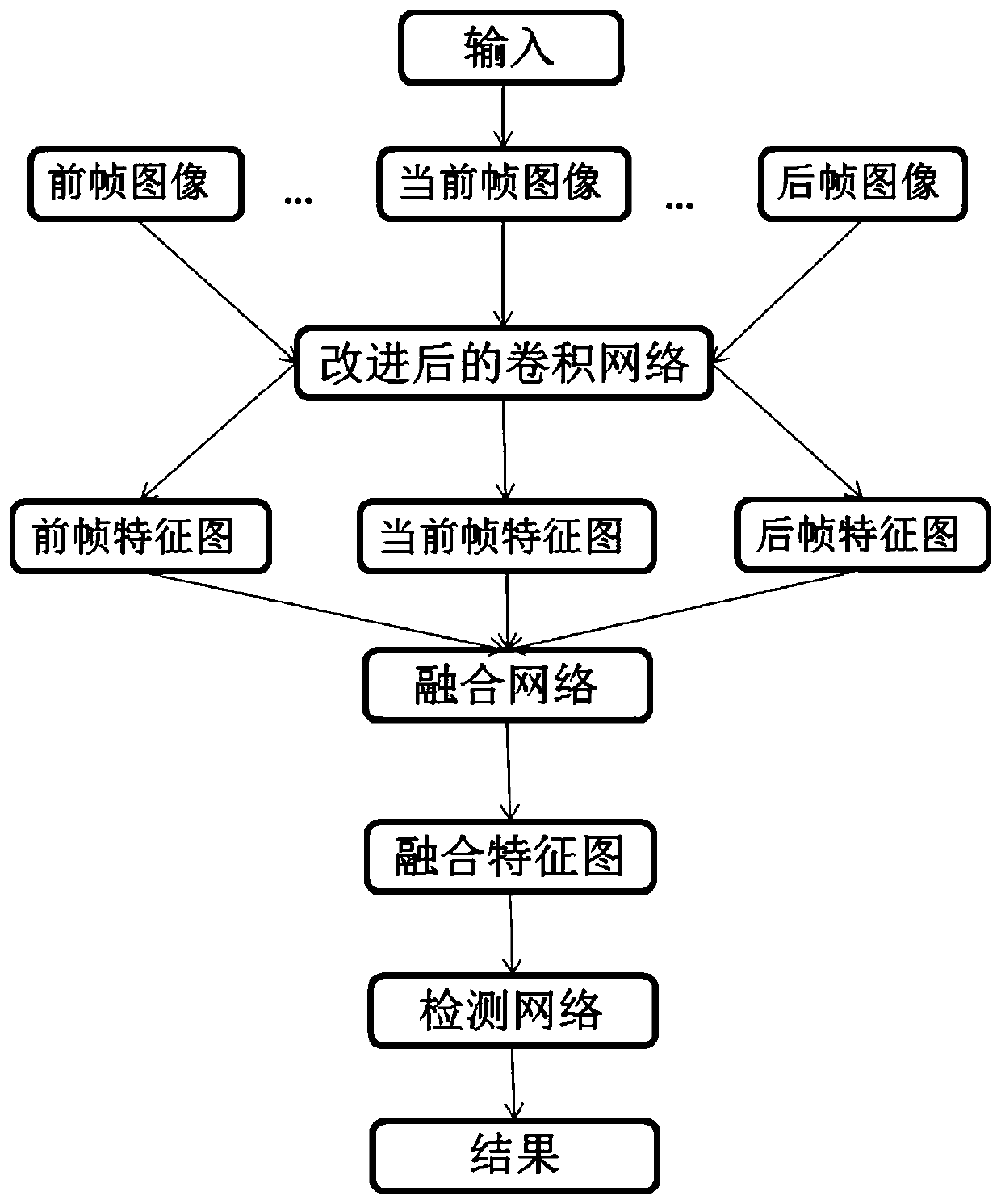
[0031] With the popularity of camera equipment and the development of multimedia technology, the amount of video information in life is increasing day by day. How to understand and apply video content and find useful information from a large number of videos has become a hot research direction. Among them, video object detection as the basis of other tasks is an important research direction. Compared with image target detection, the input of video target detection is a certain video, and the video provides more inter-frame timing information and redundant information. At the same time, the target in the video is prone to occlusion, deformation, blurring and other problems, directly using the image The object detection method performs object detection on video, which is not only ineffective, but also slow. Most of the current video target detection methods use a two-stage detection model, and comprehensively utilize video information by introducing optical flow networks or trac...
Embodiment 2
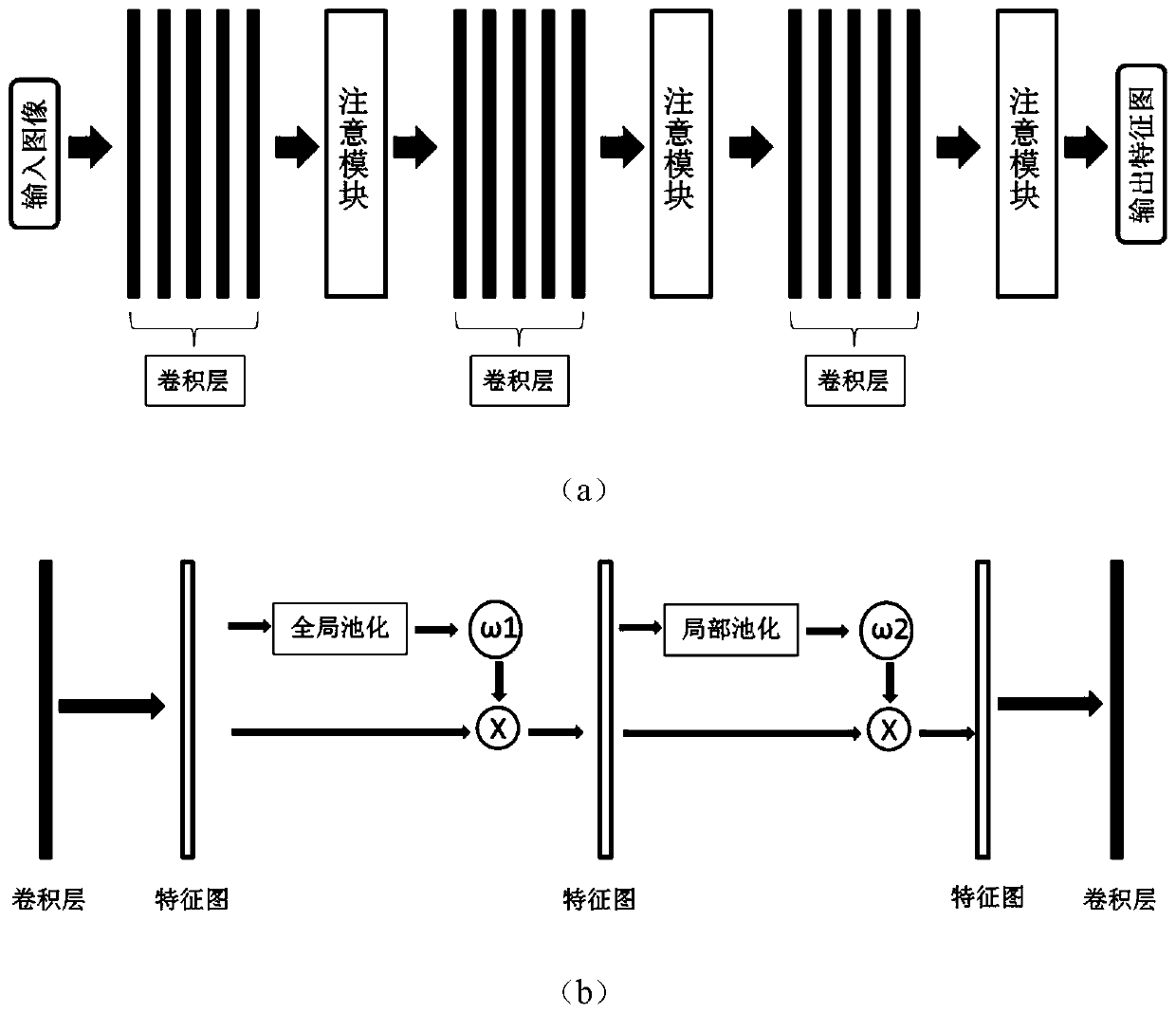
[0042] The video target detection method based on multi-layer feature fusion is the same as Example 1. In step (1), the current frame, previous frame and rear frame images are input into the improved convolutional neural network to extract the feature map F t , F t- , F t+ , including the following steps:
[0043] (1a) Input the image into the improved convolutional neural network, add a shallow attention mechanism module after the convolutional layer at one-third of the depth of the network, optimize the shallow feature map extracted by the convolutional layer, and use it as Input to the next convolutional layer. The feature map extracted by the convolutional layer at one-third of the depth position contains the texture and position information of the target, and the texture and position information are selectively enhanced by using the attention mechanism module.
[0044] (1b) Add a middle-layer attention mechanism module after the convolutional layer at the two-thirds de...
Embodiment 3
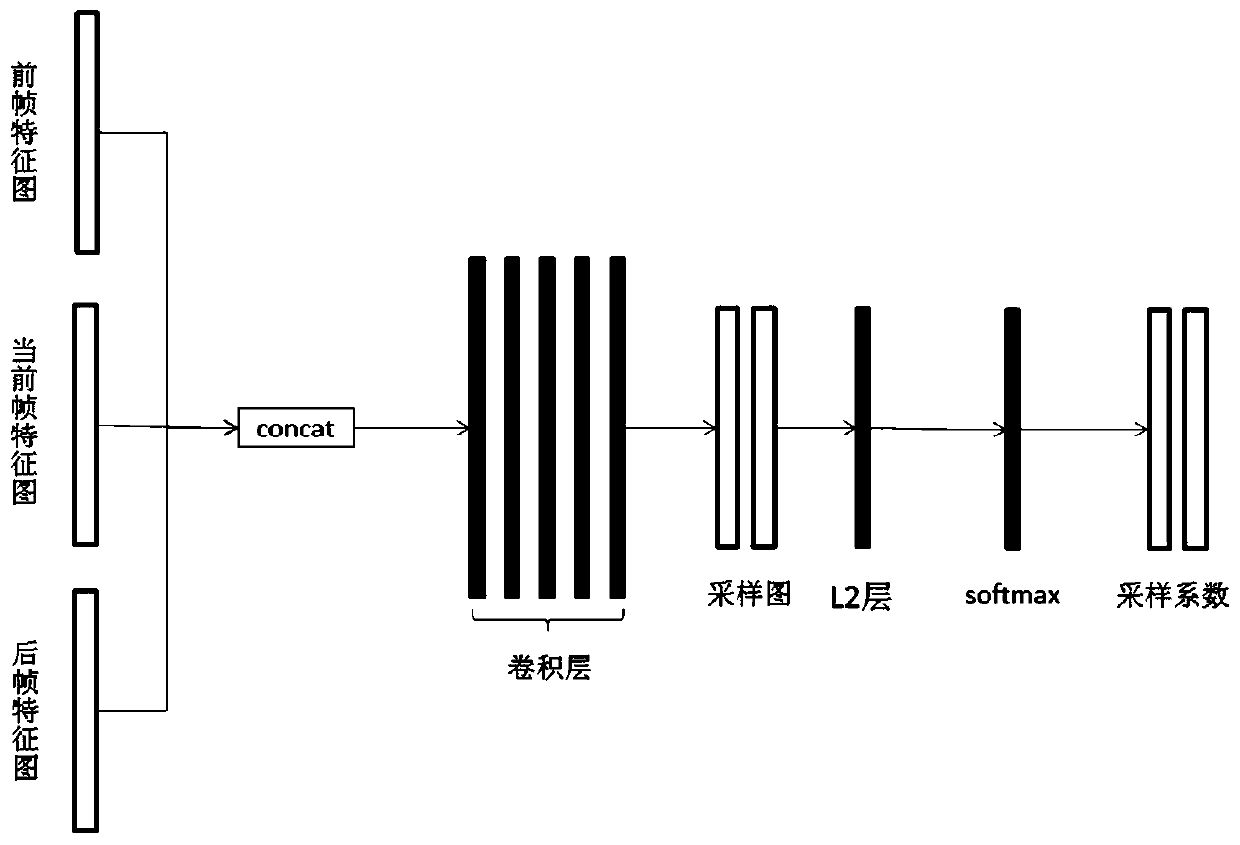
[0048] The video target detection method based on multi-layer feature fusion is the same as example 1-2. The fusion network mentioned in step (1) fuses the feature map information of the previous frame and the rear frame into the feature map of the current frame. The process includes:
[0049] (a) First connect the feature maps of the current frame, the previous frame and the subsequent frame according to the first dimension, and input them to the sampling network layer to obtain the sampling map H of the feature maps of the previous frame and the subsequent frame t- , H t+ , as the input when calculating the sampling coefficient. The sampling network layer of the present invention includes 5 layers of convolutional layers, and the size of the convolution kernel of each layer of convolutional layers is 5*5, 3*3, 1*1, 3*3, 5*5, and the size of the 5 layers of convolutional layers The structure is similar to the pyramid structure, and the sampling information of different resol...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com