


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Word segmentation method based on Bi-LSTM
A word segmentation method and data technology, applied in neural learning methods, special data processing applications, instruments, etc., can solve the problems of few network layers, inability to recognize unregistered words, low efficiency, etc., and achieve the effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


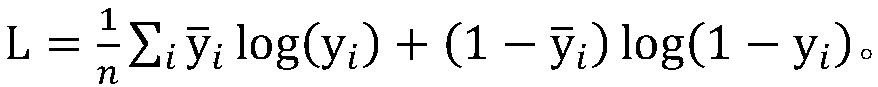
Examples
Embodiment Construction
[0042] In order to make the above-mentioned features and advantages of the present invention more comprehensible, the following specific embodiments are described in detail in conjunction with the accompanying drawings.
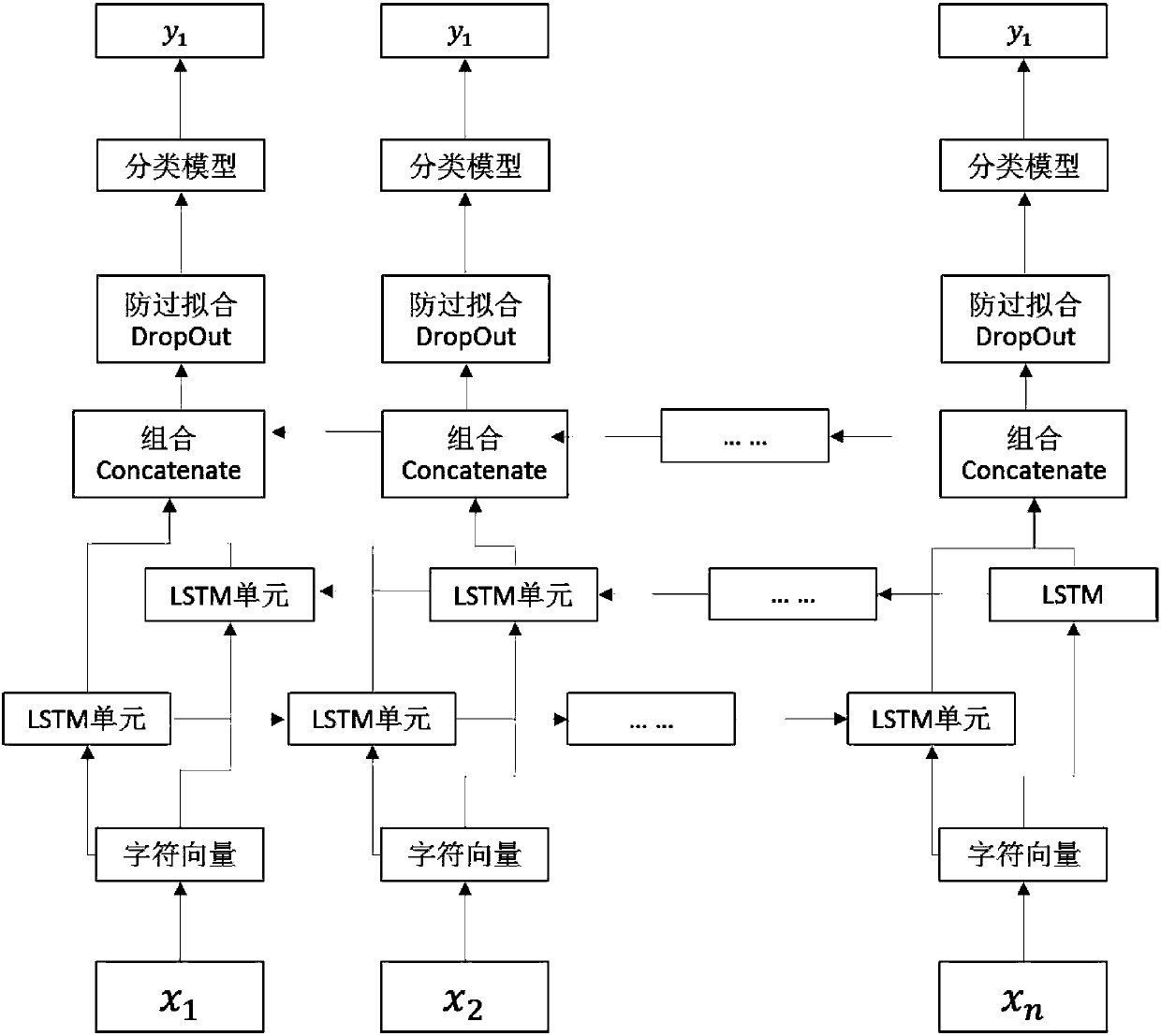
[0043] The method process of the present invention is as figure 1 shown, which includes:
[0044] (1) Training stage:
[0045]Step 1: If there are multiple word-segmented corpus data, integrate them into one training corpus data OrgData, and its format is that each word segmentation result occupies one line; then convert the training corpus data Original into character-level corpus data. Specifically: according to the marking method of BMES (Begin, Middle, End, Single), the characters of the original training corpus data are segmented and marked as New_Data. Let the label corresponding to a certain word be Label, then the character at the beginning of the word is marked as LabelB, the character at the middle of the word is marked as Label M, and the charact...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com