Deep learning framework Caffe system and algorithm based on MIC cluster
A deep learning and clustering technology, applied in the field of high-performance computing, can solve the problems of limited cost, scalability and performance, and large time complexity of a single node, achieve load balancing, improve kernel computing efficiency, and improve performance.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
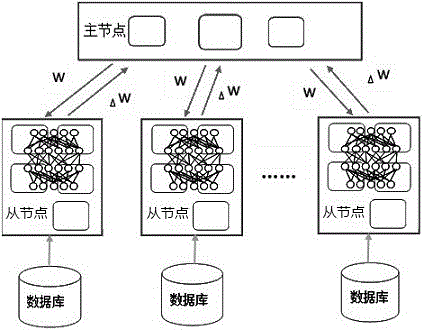
[0023] The Caffe algorithm system based on the deep learning framework of the MIC cluster includes multiple nodes in the MIC cluster, and the nodes include a master node and a slave node, and each node shares data and tasks through MPI communication. The master node is responsible for calculating and summarizing the information fed back by each node, and then distributing the updated parameters to each node. The slave node uses the new parameters to perform the next round of iterative calculation, and feeds back the execution result to the master node.
[0024] The Caffe algorithm, a deep learning framework based on the MIC cluster, runs on multiple nodes of the MIC cluster through MPI technology. The tasks and data are equally divided between each node through MPI communication, and sub-tasks and sub-data are executed in parallel between different nodes to perform ForwardBackward in Caffe. Calculation, the execution result is fed back to the master node, the master node calcu...
Embodiment 2
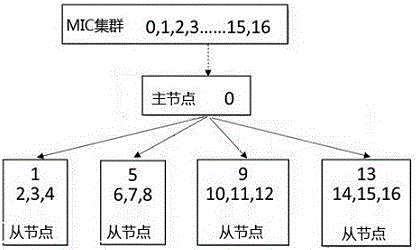
[0028] Taking 5 nodes as an example, the master-slave nodes and master-slave processes are allocated as follows figure 2 As shown, the MIC cluster includes nodes numbered 0-16, and the node numbered 0 is set as the master node, and the master node is connected to 4 slave nodes through threads. Each slave node contains 1 master process and 3 slave processes. Slave node 1 includes master process 1 and slave processes 2, 3, and 4. The slave node 2 includes a master process 5 and slave processes 6, 7, and 8. The slave node 3 includes a master process 9 and slave processes 10, 11, 12. The slave node 4 includes a master process 13 and slave processes 14, 15, 16.
[0029] In the case that the number of parallel threads for slave process calculation changes, the number n of slave processes will be increased or decreased accordingly to ensure the full utilization of the number of threads on each MIC node.
Embodiment 3
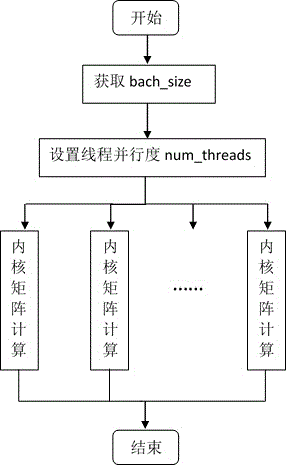
[0031] The difference from Embodiment 1 is that in the ForwardBackward calculation of the Caffe kernel part, complex operations such as matrices and equations are involved, and the calculation method of OpenMp multi-threaded concurrent execution is used to decompose the complex operations, and the multi-threaded parallel setting method is a parallel outer loop. The overhead of thread scheduling is reduced, and it turns out that the computational efficiency of the entire program is greatly improved through parallel matrix operations. The multi-threaded parallelism of the kernel is mainly based on the bach_size decomposition of convolution, pooling and other layers, that is, the parallel reading and processing of pictures, which reduces the time complexity of the program and improves performance. The flow chart of multi-threaded parallel implementation is as follows: image 3 shown.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com