Multi-modal pre-training method based on image-text linear combination
A linear combination and pre-training technology, applied in neural learning methods, character and pattern recognition, biological neural network models, etc., to improve processing speed, performance, and accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
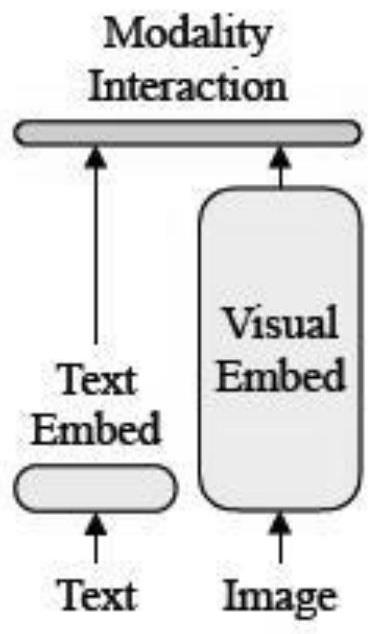
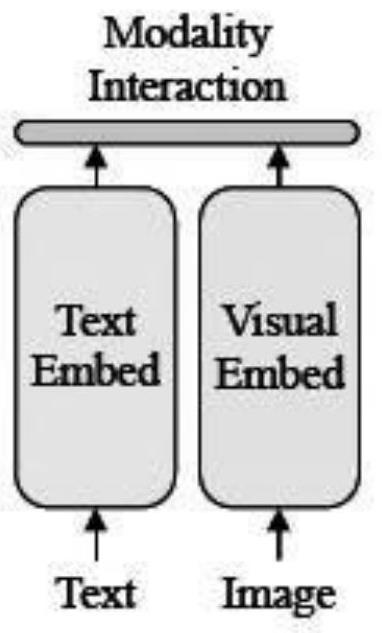
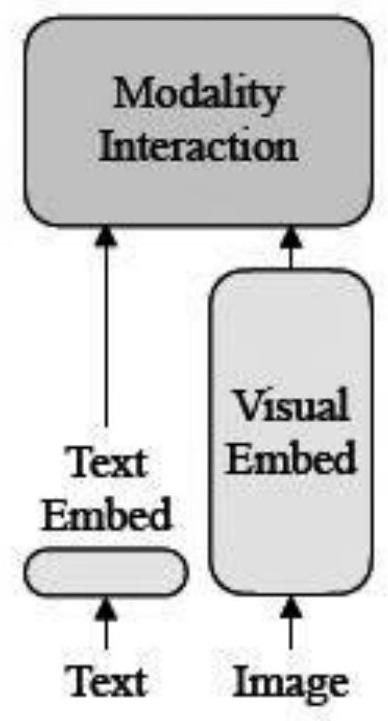
[0091] Facing the application scenario of image search text, the number of super-parameter images, the number of image-related descriptions (number of text annotations / sentences), image weight, and text weight respectively use a=1; b=3; ξ=μ=1 The strategy can obtain a better recall rate. Such as Figure 5 A diagram of the entire pre-trained model structure. The following is a detailed description with examples:
[0092] S1-S2.1: Image-Text Pair (Image-Text Pair), such as Figure 6 and Figure 7 After the feature extraction operation, splicing is performed to obtain the feature sequence Y:
[0093] Y=[V type +v;T type +t] = [0.87, 0.15, ..., 0.857]
[0094] S2.2: Input the feature sequence Y to the Transformer Encoder interaction layer to calculate the attention value through the attention mechanism, and finally obtain the final feature sequence Y through the nonlinear activation function tanh() p .
[0095]
[0096] Y p =tanh(Attention(Q,K,V))=[0.108, 0.732, -0.852,...
Embodiment 2
[0112] Facing the application scenario of text search for pictures, the input strategy of a=2; b=3; ξ=μ=1 can obtain a better recall rate. The following is a detailed description with examples:
[0113] S1-S2.1: Image-Text Pair (Image-Text Pair), such as Figure 6 and Figure 7 After the feature extraction operation, splicing is performed to obtain the feature sequence Y:
[0114] Y=[V type +v;T type +t] = [0.27, 0.59, ..., 0.437]
[0115] S2.2: Input the feature sequence Y to the Transformer Encoder interaction layer to calculate the attention value through the attention mechanism, and finally obtain the final feature sequence Y through the nonlinear activation function tanh() p .
[0116]
[0117] Y p =tanh(Attention(Q,K,V))=[0.271, -0.842, -0.312, . . . , 0.662].
[0118] S3: After obtaining the feature sequence of two modal interactions, different downstream tasks can be connected. In this embodiment 2, as mentioned above in the application scenario of text sea...
Embodiment 3
[0132] In the image-text multimodal classification task, in the face of the application scenario of VQA, the input strategy of a=1; b=2; ξ=μ=1 can obtain better accuracy. The following is a detailed description with examples:
[0133] S1-S2.1: Image-Text Pair (Image-Text Pair), such as Figure 6 and Figure 7 After the feature extraction operation, splicing is performed to obtain the feature sequence Y:
[0134] Y=[V type +v;T type +t] = [0.821, -0.159, ..., -0.825]
[0135] S2.2: Input the feature sequence Y to the Transformer Encoder interaction layer to calculate the attention value through the attention mechanism, and finally obtain the final feature sequence Y through the nonlinear activation function tanh() p .
[0136]
[0137] Y p =tanh(Attention(Q,K,V))=[0.172, -0.451, -0.312, . . . , -0.662].
[0138] S3: In Embodiment 3, it is mentioned above that facing the application scenario of VQA, the strategy of a=1; b=2; ξ=μ=1 can obtain a better accuracy rate. V...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com