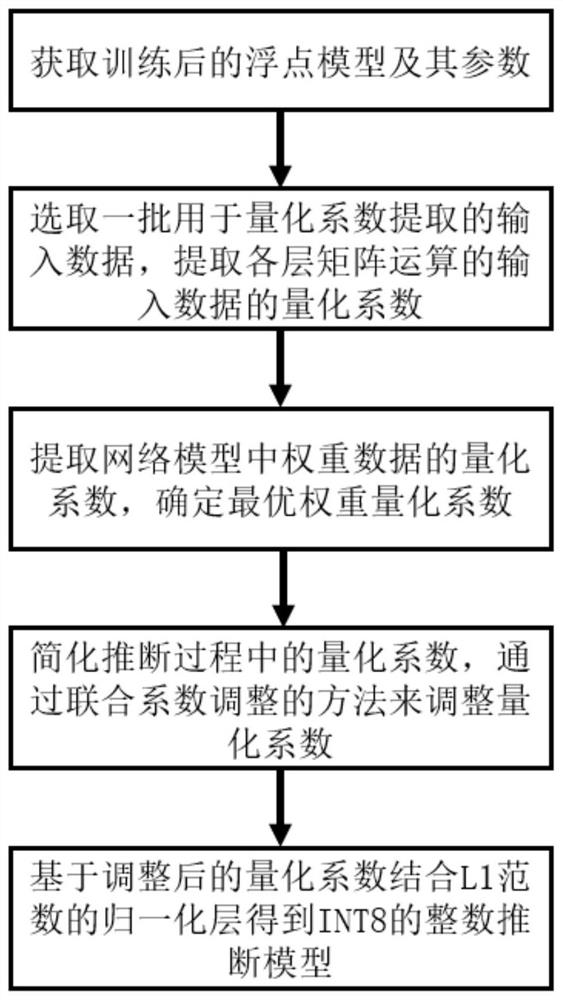
INT8 offline quantization and integer inference method based on Transform model
A technology of quantizing coefficients and integers, applied in biological neural network models, electrical digital data processing, digital data processing components, etc. Edge device operation and other issues, to achieve the effect of improving computing speed, reducing computing power and storage requirements, and reducing precision loss
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
[0065] Such as figure 1 As shown, a kind of Transformer model-based INT8 off-line quantization and integer inference method of the present embodiment comprises the following steps:
[0066] S1, convert the L2 norm of the normalization layer in the original Transformer floating-point model to L1 norm; then perform model training on the Transformer floating-point model, and obtain the trained floating-point model and its parameters.
[0067] The normalization layer is calculated according to the following formula:
[0068]
[0069] Among them, x is the input data, μ represents the average value of the row where the input data is located, α and β are trainable parameters in the floating point model, n represents the size of the row,
[0070] S2. Carry out forward inference through a small amount of data, obtain the quantization coefficients of the input data of the matrix operation of each layer in the floating-point model, and extract them as general floating-point data. ...
Embodiment 2
[0114] A kind of INT8 off-line quantization and integer inference method based on Transformer model of the present embodiment, in step S43, self-attention layer integer inference method is: as figure 2 As shown, the query vector q, key vector k, and value vector v of the INT8 type obtained by input quantization are used for linear layer calculation and attention calculation with the quantized weight data, and the quantization operation between matrix operations is completed through the shift operation. The calculated integer result is residually connected with the query vector and input to the normalization layer of L1 norm for output.
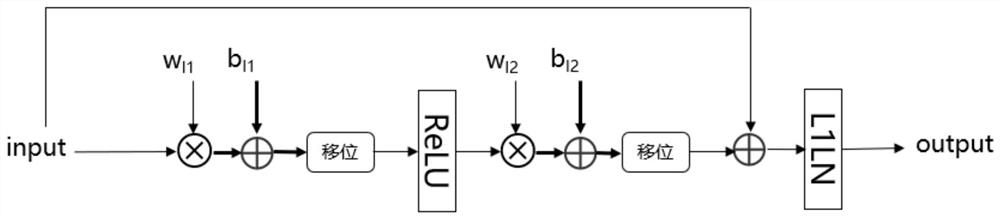
[0115] The integer inference method of the feed-forward neural network calculation layer is as follows: image 3 As shown, the quantized input data and the quantized weight data of the first linear layer are directly calculated in the linear layer, and the INT8 type calculation result is obtained by shifting, and the ReLU function is calculat...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com