Mass data clustering analysis method and device
A technology of cluster analysis and massive data, applied in the field of data analysis, can solve problems such as inability to identify, achieve the effect of ensuring load balancing and improving computing efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0059] A massive data clustering analysis method, comprising the following steps:
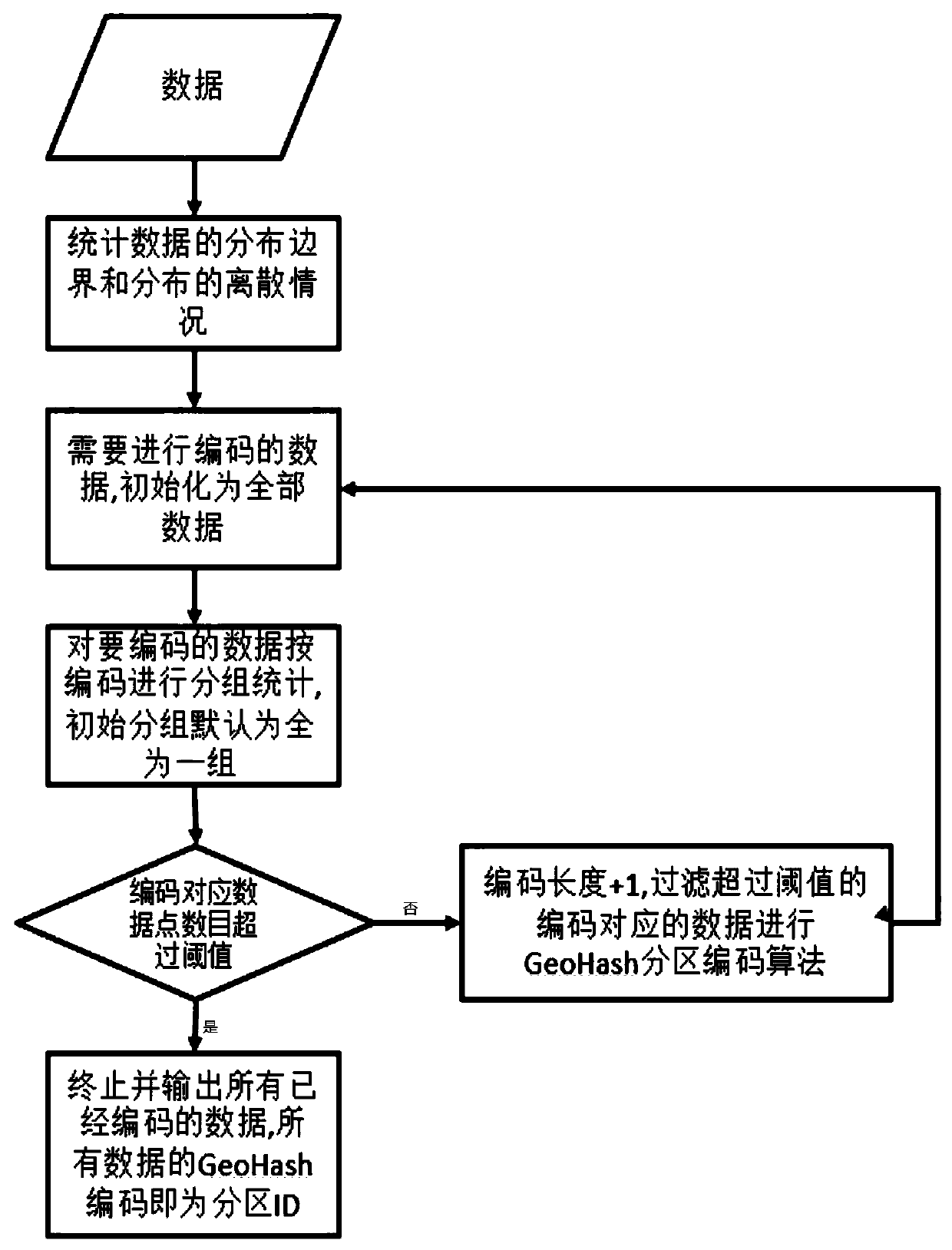
[0060] S1. The GeoHash encoding algorithm based on overlapping partitions processes the original data, and determines the partition corresponding to each data in the original data;
[0061] S2. In each partition, cluster the data in the partition in parallel, and save the cluster ID;
[0062] S3. After merging the partition results, a global cluster ID can be obtained.
[0063] The purpose of the present invention is to realize a DBSCAN algorithm based on parallel computing and solve the problem that the traditional density clustering algorithm cannot analyze massive data. The invention proposes an efficient overlapping partition and cluster merging strategy, which can quickly split data and merge clusters, and this method fully considers load balancing, and can realize efficient operations under a distributed framework, thus supporting massive data Clustering efficiently solves the problem t...
Embodiment 2
[0065] This embodiment is further based on Embodiment 1, and further, the GeoHash encoding based on overlapping partitions is named OverLap-GeoHash algorithm. During the execution of the entire algorithm, the DBSCAN algorithm has the highest time complexity and space complexity. According to the barrel principle, in order to ensure the efficiency of parallel clustering, it is necessary to divide the data into regions as much as possible.
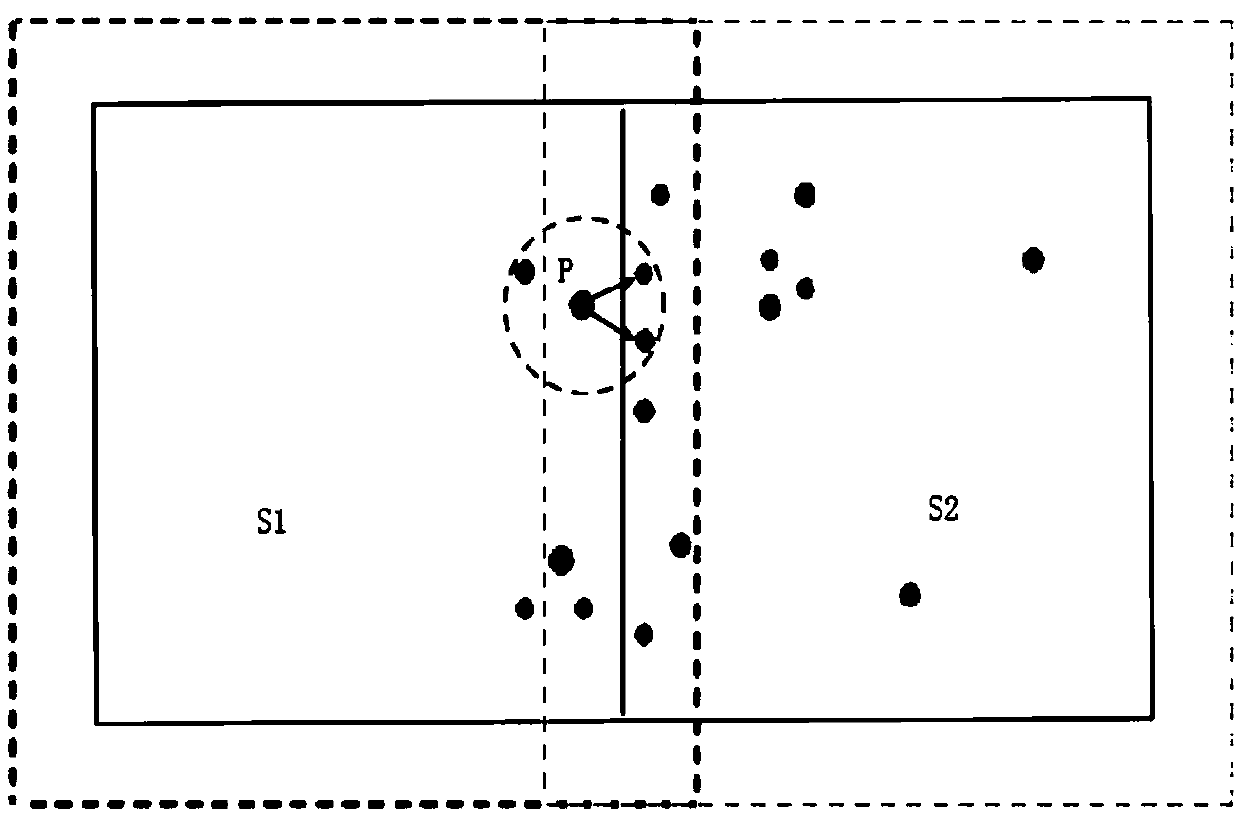
[0066] The GeoHash algorithm is a spatial encoding algorithm, which is often used for two-dimensional latitude and longitude data, and can map the latitude and longitude data into one-dimensional values or strings. In this paper, it is extended to multi-dimensional data, and some improvements are made in combination with the overlapping partition strategy. The data can be mapped into a one-dimensional value, which is the ID code of the partition. If the point to be coded is an overlapping point, it will be mapped It is multiple values, and...
Embodiment 3
[0076] This implementation is further on the basis of embodiment 2, the GeoHash encoding algorithm in the step S1 processes the original data, and the method for determining the partition corresponding to each data in the original data includes the following steps:
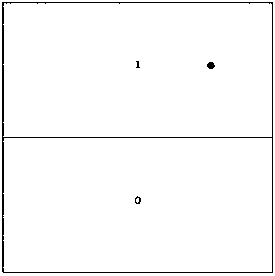
[0077] S101, initialize the Hash value to binary number 0, the number of iterations is 0, the number of iterations is given N, the upper bound and the lower bound of each dimension;
[0078] S102. For any data D, the selected dimension is the number of iterations and modulo the number of dimensions. When the value of data D in this dimension is not greater than the midpoint between the upper and lower bounds of the dimension, the Hash value is shifted to the left by one bit, and then Update the upper bound of the dimension to the midpoint of the original dimension, and add 1 to the number of iterations; when the value of data D in this dimension is greater than the midpoint between the upper and lower bounds of the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com