Two-stage online sampling method based on mapreduce model
A stage and model technology, applied in the field of data online sampling, can solve problems such as the influence of unbiased estimation algorithm and the accuracy of estimation results, so as to ensure unbiasedness and effectiveness, eliminate bias influence, and ensure randomness Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
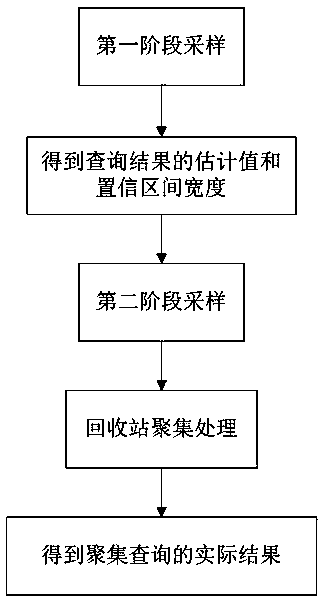
[0027] Such as figure 1 Shown the present invention is based on the two-stage online sampling method of MapReduce model, comprises:
[0028] A. The first stage of sampling: when the MapReduce model receives the input data of the upstream data node and initializes it, set up a group sampler before online processing on the map side, divide each data block into a group, and use the data block as the sample unit Take a sample. The cluster sampler maintains a data block random queue for each data table, and a data block random queue contains data blocks corresponding to multiple data tables, and each data block random queue corresponds to a mapper (mapper). The order of all data blocks in the data block random queue is randomized, and a mapper is designated by the map side each time it is scheduled. When requesting to receive input data from the upstream data node, the mapper iteratively selects from the corresponding In the data block random queue, return the data block at the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com