An emotion analysis method based on word vector and part of speech
A technology of sentiment analysis and word vectors, applied in semantic analysis, special data processing applications, instruments, etc., can solve the problems of not fully considering the influence of word parts of speech and semantic information on the results of sentiment analysis, so as to improve time performance and improve experimental results. effect of effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
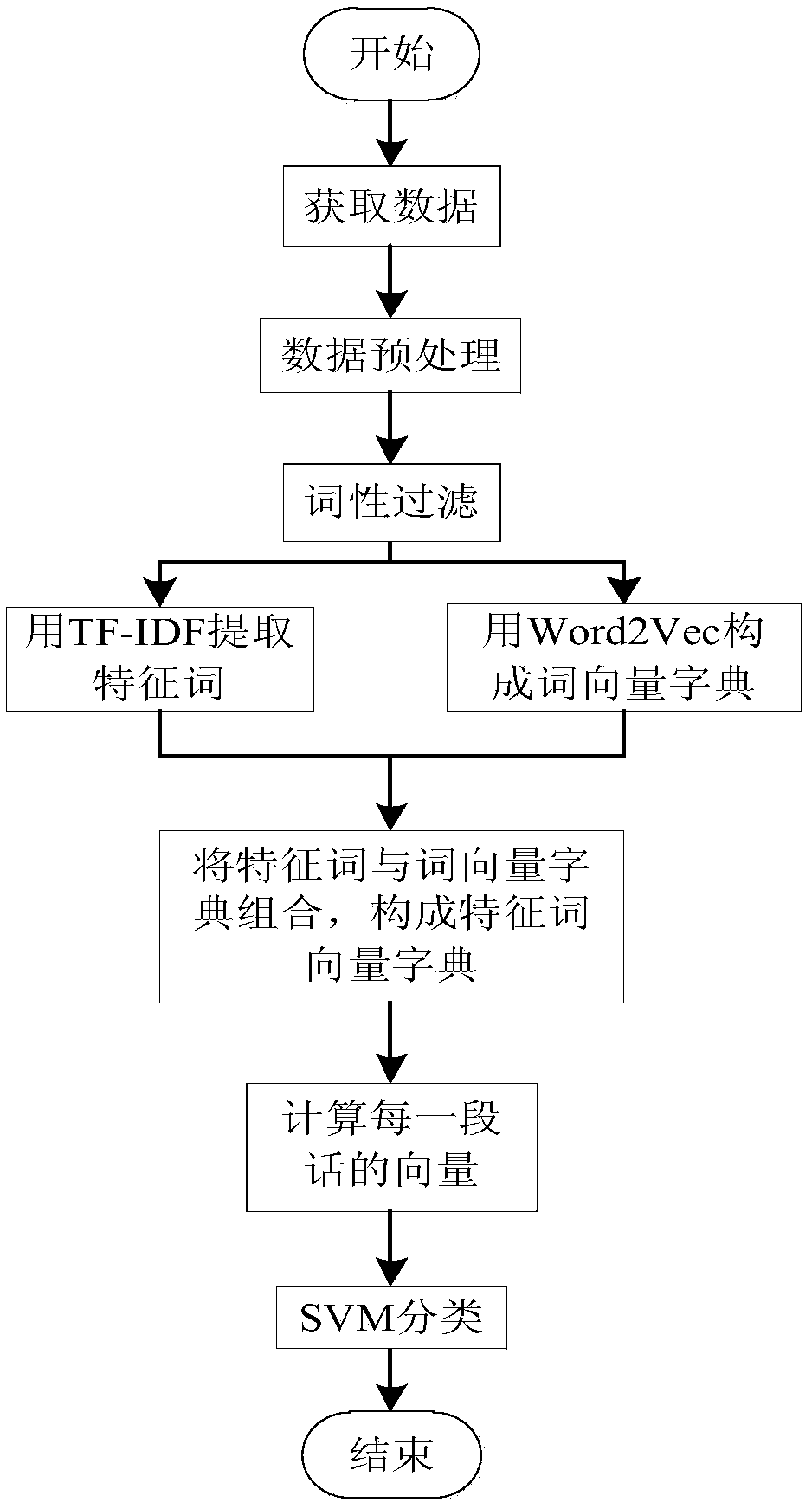
[0025] see figure 1 , the embodiment of the present invention provides a kind of sentiment analysis method based on word vector and part of speech, this method comprises the following steps:
[0026] 101: Organize the original corpus;
[0027] This step 101 specifically includes: taking the existing original microblog corpus, and matching the Chinese corpus information in the microblog corpus with the corpus label information.
[0028] 102: data preprocessing;
[0029] Remove special symbols that have no positive effect on or interfere with sentiment analysis in Weibo text, such as URLs, @marks, forwarding marks " / / " and content marking information "#content#", etc.
[0030] 103: Process the preprocessed text according to the part of speech of the word, filter out the required adjectives, verbs, and negative words, and form the original feature set.
[0031] 104: Calculate the TF-IDF value of the word, and use the TF-IDF value of the word to extract the feature word;
[00...
Embodiment 2
[0051] The scheme in embodiment 1 is further introduced below in conjunction with specific examples and mathematical formulas, see the following description for details:
[0052] 201: First, the original microblog corpus needs to be obtained, and then the original microblog corpus is sorted out, and the corpus information Data in the original microblog corpus is matched with the corpus label information Senti_Label, and each piece of corpus information corresponds to a label information. If the corpus information is positive, it is marked as 1; otherwise, it is marked as 0.
[0053] 202: Perform data preprocessing of the original microblog corpus;
[0054]From the original Weibo corpus, special symbols such as repeated Weibo, @, URL and #, and English content are sequentially removed. Then, BostonNLP is used to segment the Weibo text, and the part of speech is marked to remove meaningless stop words. Finally, the Each word in the word segmentation result is marked with a corr...
Embodiment 3
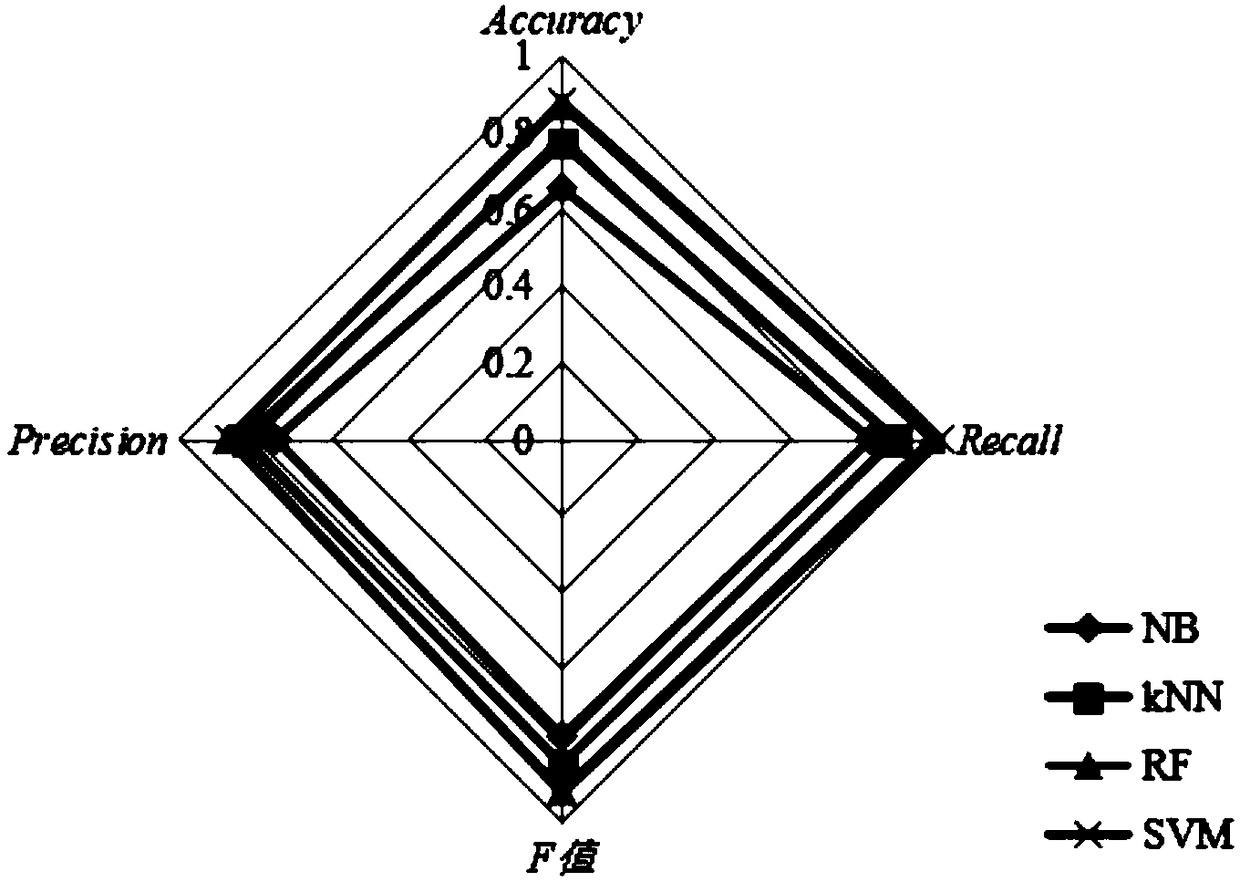
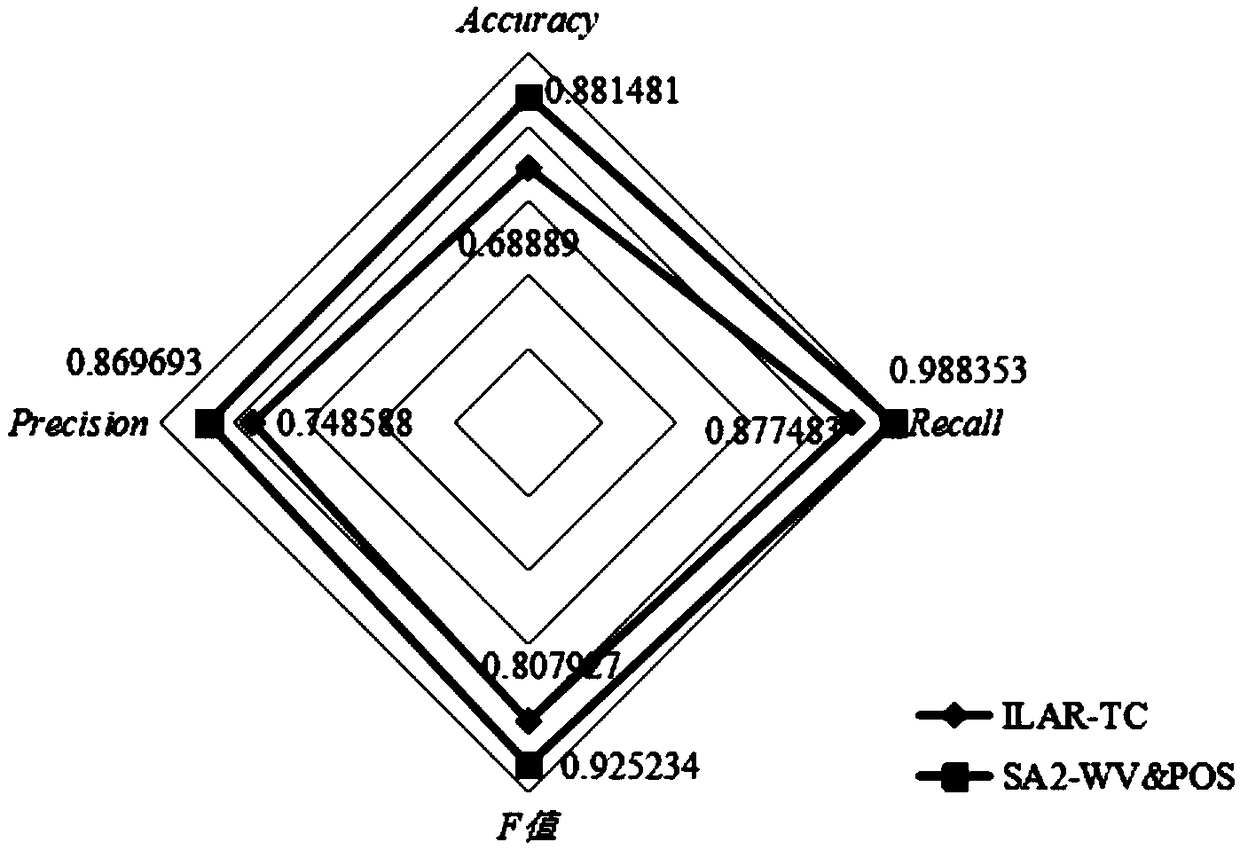
[0071] Combined with the specific experimental data, figure 2 and image 3 The scheme in embodiment 1 and 2 is carried out feasibility verification, see the following description for details:
[0072] Firstly, the effects of Naive Bayesian classifier, nearest neighbor classifier, support vector machine classifier and random forest classifier on the experimental results were verified through experiments respectively, and by using the accuracy rate (Accuracy), recall rate (RecallRate), F Value (F-measure) and precision (Precision) are used as evaluation criteria to evaluate the experimental results, such as figure 2 As shown, the experimental results prove that the support vector machine classifier has a better result in sentiment classification on the microblog dataset.
[0073] exist figure 2 In it, it can be seen that the Accuracy, Recal, F value, and Precision of SVM are higher than those of Bayesian classifier, nearest neighbor classifier and random forest classifier....
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com