Spark Streaming receiver dynamic configuration method and device in big data platform
A big data platform and dynamic configuration technology, applied in the field of big data processing, to achieve the effect of improving resource utilization
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

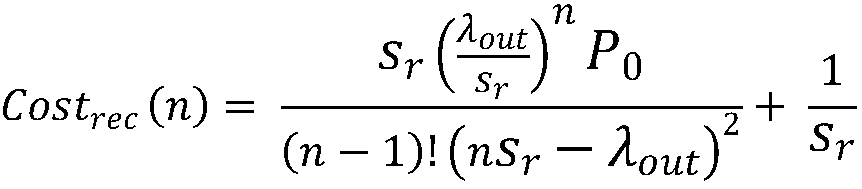
Examples
Embodiment 1
[0057] The purpose of Embodiment 1 is to provide a method for dynamically configuring Spark Streaming receivers in a big data platform.
[0058] In order to achieve the above object, the present invention adopts the following technical scheme:
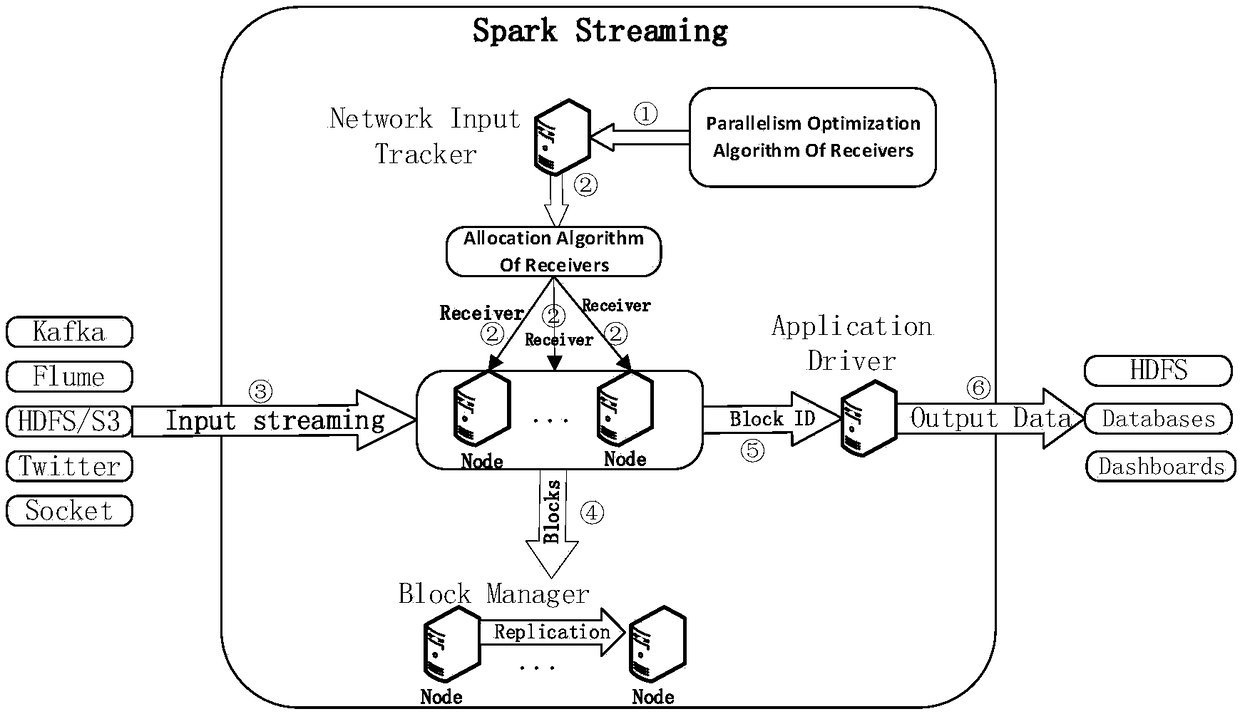
[0059] like Figure 1-2 As shown, a method for dynamically configuring Spark Streaming receivers in a big data platform, the specific steps include:
[0060] A. Determine the Spark application, runtime, and input dataset;
[0061] B. Improve the execution framework of spark streaming, and then propose a dynamic configuration strategy for the receiver receiver; the parallelism of the receiver receiver is configured based on manual experience. The execution framework of streaming is improved, and a dynamic receiver configuration strategy is proposed.
[0062] The execution framework for improving spark streaming in step B includes 4 steps:
[0063] B1. Change the number of receivers set by the original manual experience value to gene...
Embodiment 2
[0112] The purpose of this Example 3 is to conduct experimental verification based on the method in Example 1.
[0113] The experimental environment uses Spark1.6+hadoop2.2, and the program is wordCount, which is compiled by Maven and deployed to the experimental cluster. In this embodiment, 11 virtual machines (VMs) are deployed on a real Spark cluster. Each virtual machine has 8 2GHz cores, 8GB RAM and 500GB hard disk. One virtual machine is used as ResourceManager and NameNode, and the remaining 10 virtual machines As a worker, each worker is configured with 16 virtual memory, 7GB memory (1GB is required for the background process) and a 500GB hard disk. This embodiment has realized independent resource management and scheduling. In order to ensure the reliability of data, this embodiment adopts HDFS (Hadoop Distributed File System) to obtain permanent results at the bottom of Spark. HDFS block size is set to 64MB and replication level is set to 3. Red Hat 6.3 server vers...
Embodiment 3
[0130] The purpose of Embodiment 3 is to provide a computer-readable storage medium.
[0131] In order to achieve the above object, the present invention adopts the following technical scheme:
[0132] A computer-readable storage medium, in which a plurality of instructions are stored, and the instructions are adapted to be loaded by a processor of a terminal device and perform the following processing:
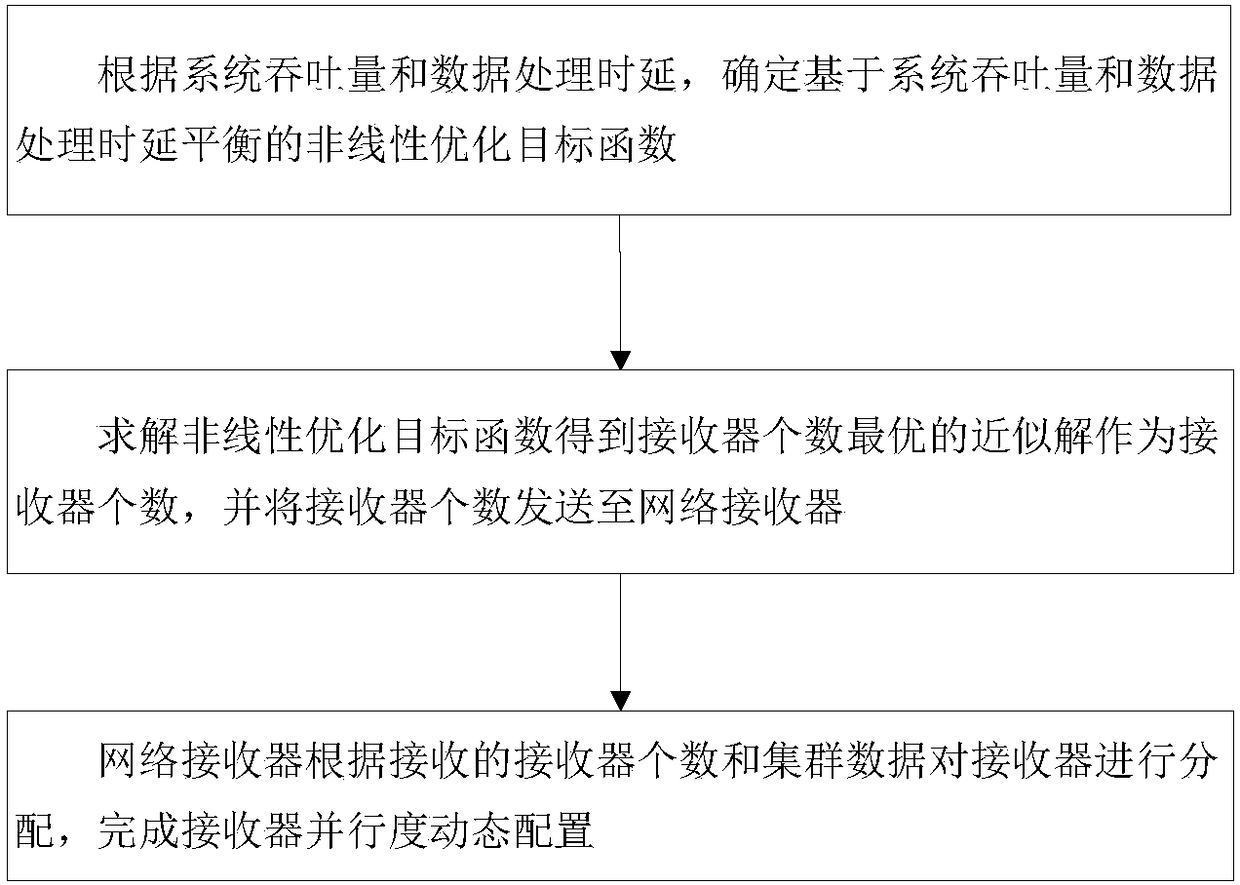
[0133] According to the system throughput and data processing delay, determine the nonlinear optimization objective function based on the balance between system throughput and data processing delay;
[0134] Solve the nonlinear optimization objective function to obtain the approximate solution with the optimal number of receivers as the number of receivers, and send the number of receivers to the network receivers;
[0135] The network receiver allocates receivers according to the number of received receivers and cluster conditions, and completes the dynamic configuration of...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com