Mutual information based parallel feature selection method for document classification
A feature selection method and document classification technology, applied in text database clustering/classification, special data processing applications, unstructured text data retrieval, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

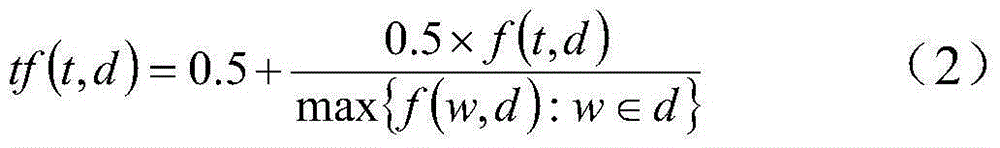
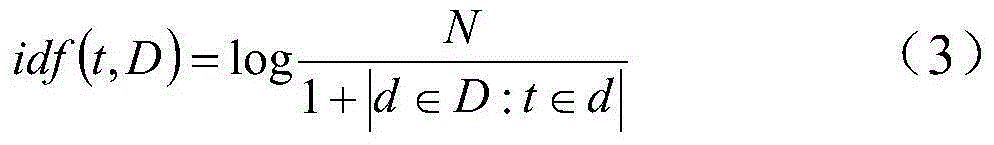
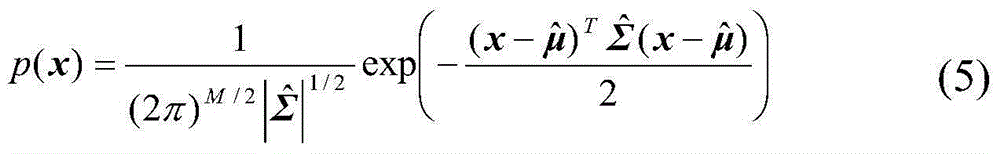
Examples
example 1
[0099] 37,926 Chinese webpages were collected from the Internet, and those with less than 50 words were filtered out, leaving 17,752 webpages for classification analysis. These pages are divided into 2 categories according to the content, namely food and sports. Food webpages are represented by 0, sports webpages are represented by 1, and all documents are divided manually. First, calculate the TF-IDF value of each word in each document according to formula (13). In all documents, if the TF-IDF value of a word is less than 0.02, then the word is a low-frequency word and is ignored. By calculation, the dictionary contains 2728 words, and the documents are classified according to these 2728 words. Based on the feature selection method proposed in this paper, the combination of feature variables with the largest amount of information for text classification is selected. The process is as follows.
[0100] The 2728 words are analyzed by the feature selection method proposed in th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com