System and method for generation of unseen composite data objects
a composite data and image technology, applied in the field of image and video generation using generative models, can solve the problems of difficult to generate high resolution images and models such as wgan and lsgan, their ability to adapt (e.g., generalize) to unseen scene compositions has not received as much attention, and the training cost can thus be reduced. , the effect of avoiding the combinatorial explosion
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
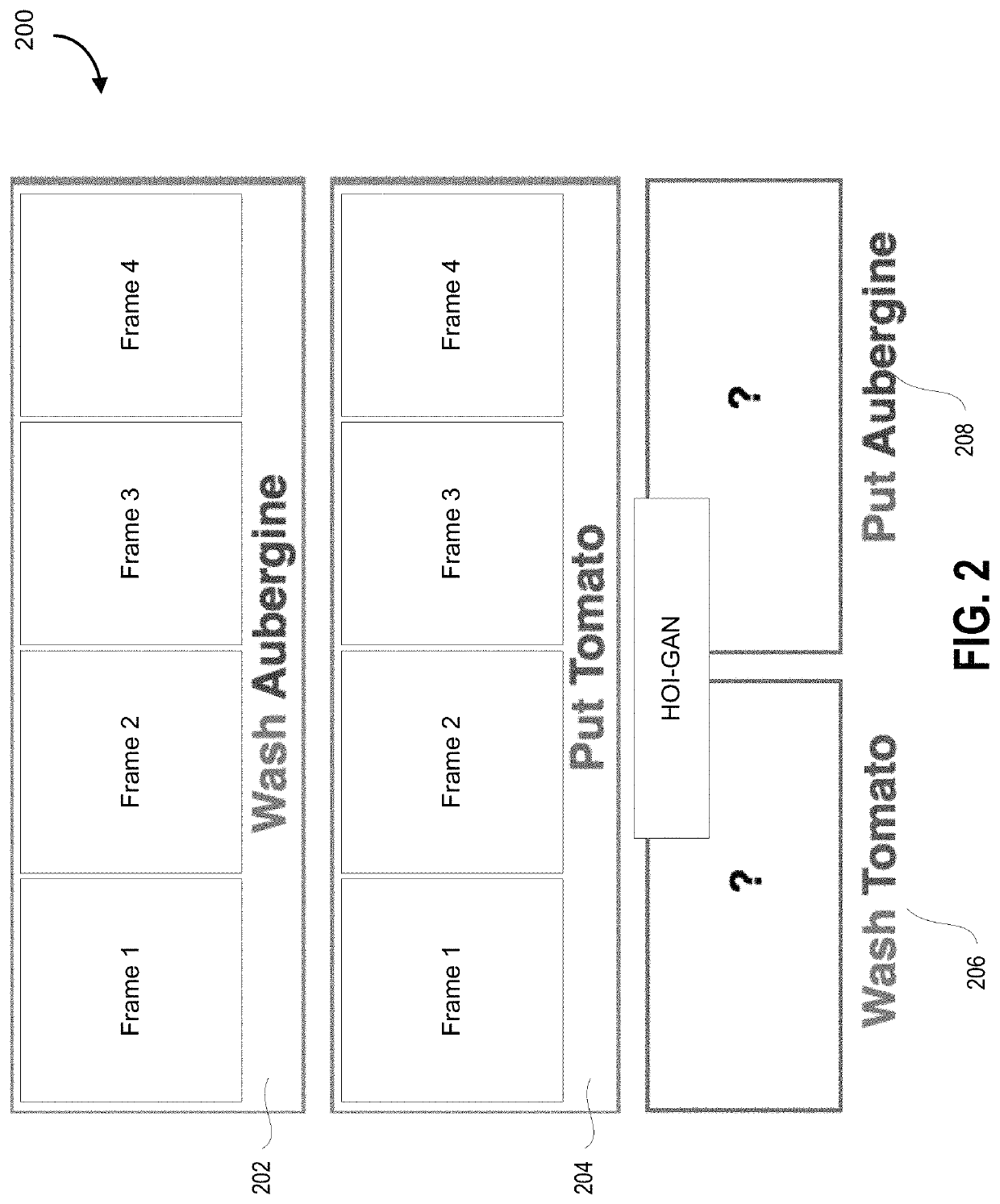
[0082]Despite the promising success of generative models in the field of image and video generation, the capability of video generation models is limited to constrained settings. Task-oriented generation of realistic videos is a natural next challenge for video generation models. Human activity videos are a good example of realistic videos and serve as a proxy to evaluate action recognition models.
[0083]Current action recognition models are limited to the predetermined categories in the dataset. Thus, it is valuable to be able to generate video corresponding to unseen categories and thereby enhancing the generalizability of action recognition models even with limited data collection. Embodiments described herein are not limited to videos, and rather extend to other types of composites generated based on unseen combinations of categories.
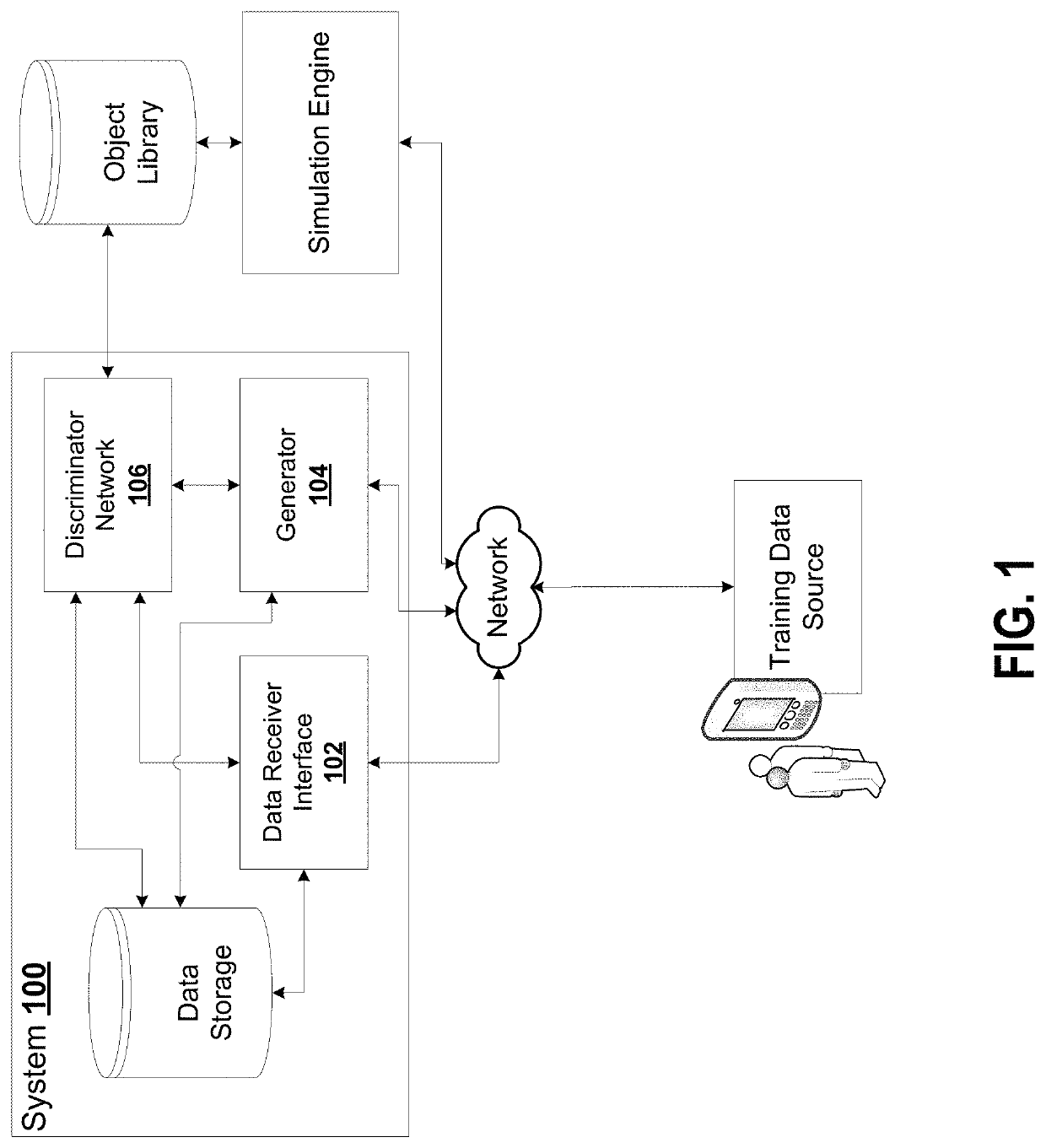
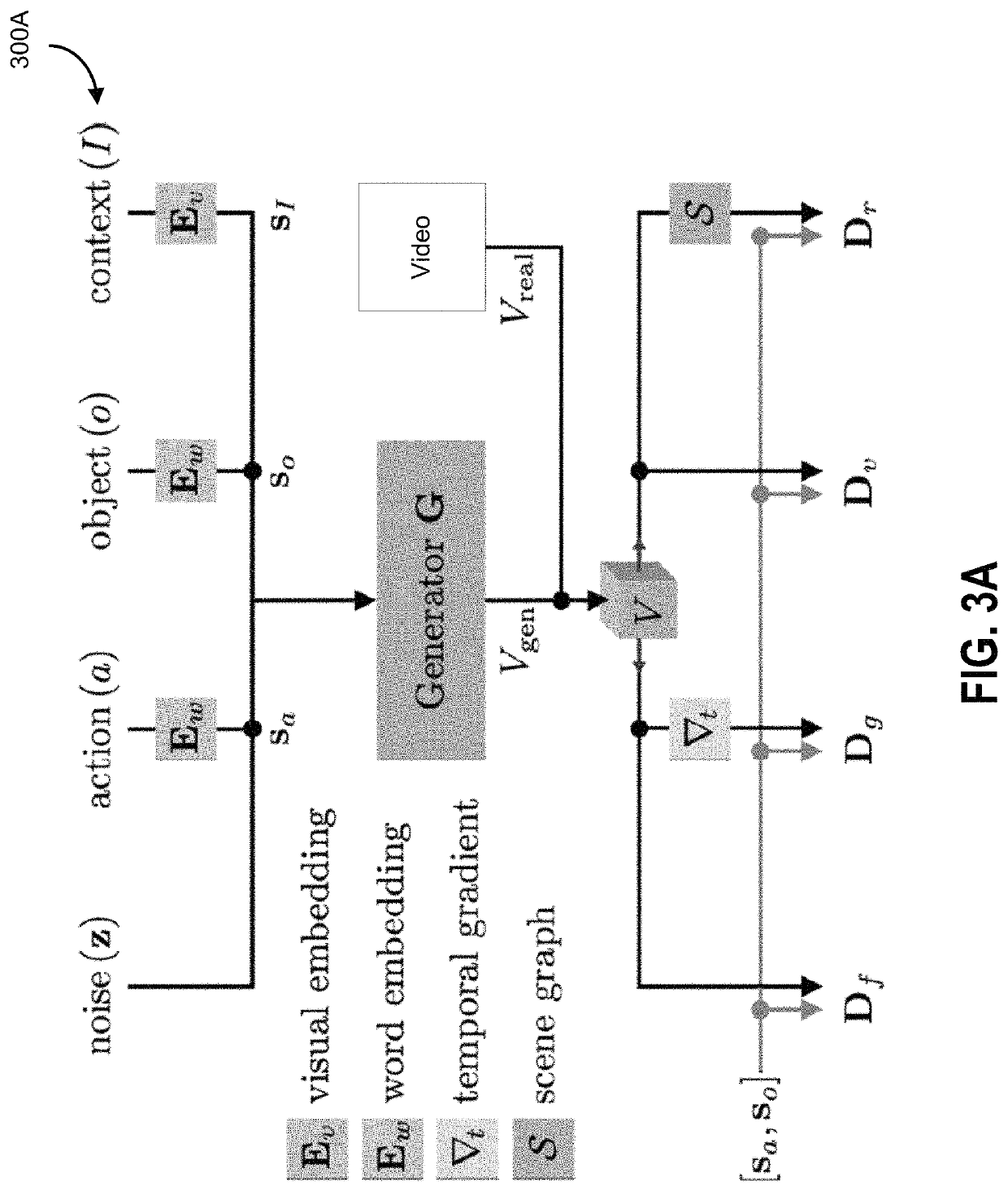
[0084]FIG. 1 is an example generative adversarial network system, according to some embodiments. The generative adversarial network system 100 is ad...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com