Data cleaning method and device in soil big data analysis
A data cleaning and big data technology, applied in the field of data analysis, can solve the problems of outliers in the data and the reduction of the accuracy of data analysis, and achieve the effects of high accuracy, improved accuracy, and improved efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
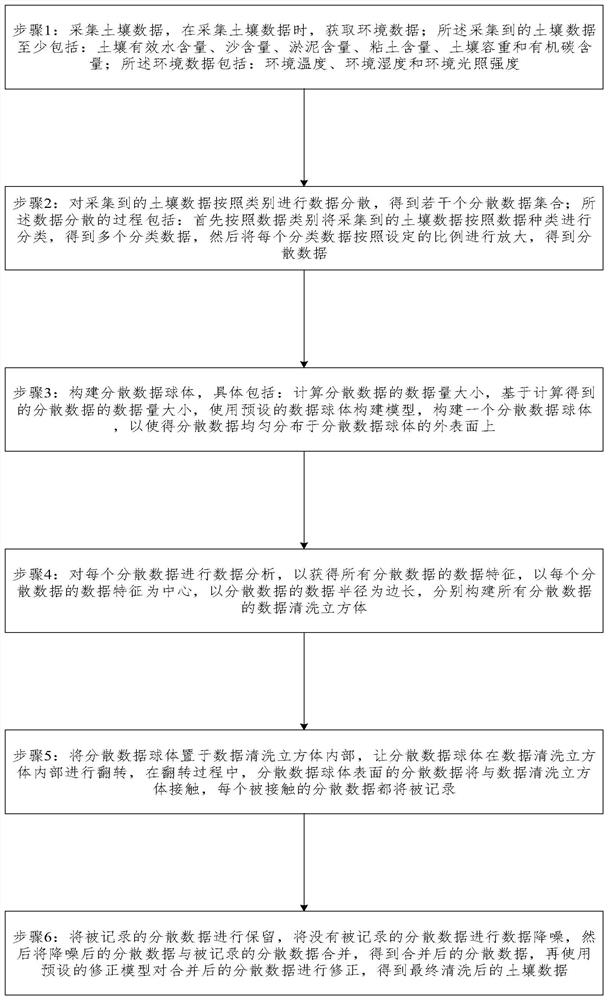
[0030] Such as figure 1 As shown, the data cleaning method in soil big data analysis, the method performs the following steps:
[0031] Step 1: collect soil data, and obtain environmental data when collecting soil data; the collected soil data at least include: soil effective water content, sand content, silt content, clay content, soil bulk density and organic carbon content; Environmental data include: ambient temperature, ambient humidity and ambient light intensity;
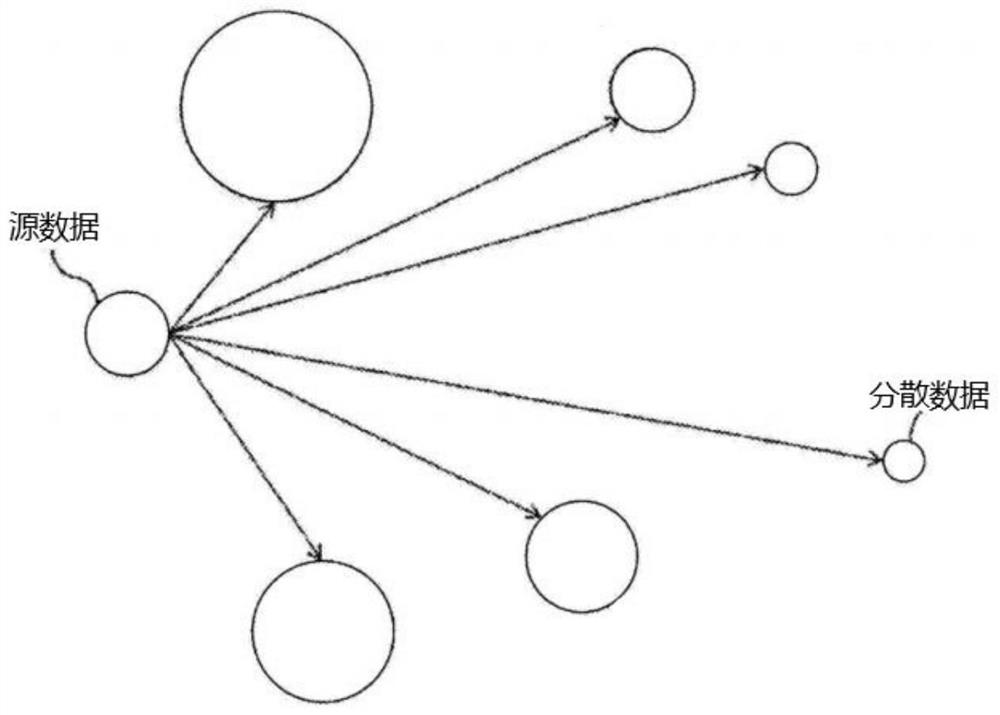
[0032] Step 2: Perform data dispersal on the collected soil data according to categories to obtain several scattered data sets; the process of data dispersal includes: firstly classify the collected soil data according to data types according to data categories to obtain multiple classifications data, and then enlarge each classification data according to the set ratio to obtain scattered data;
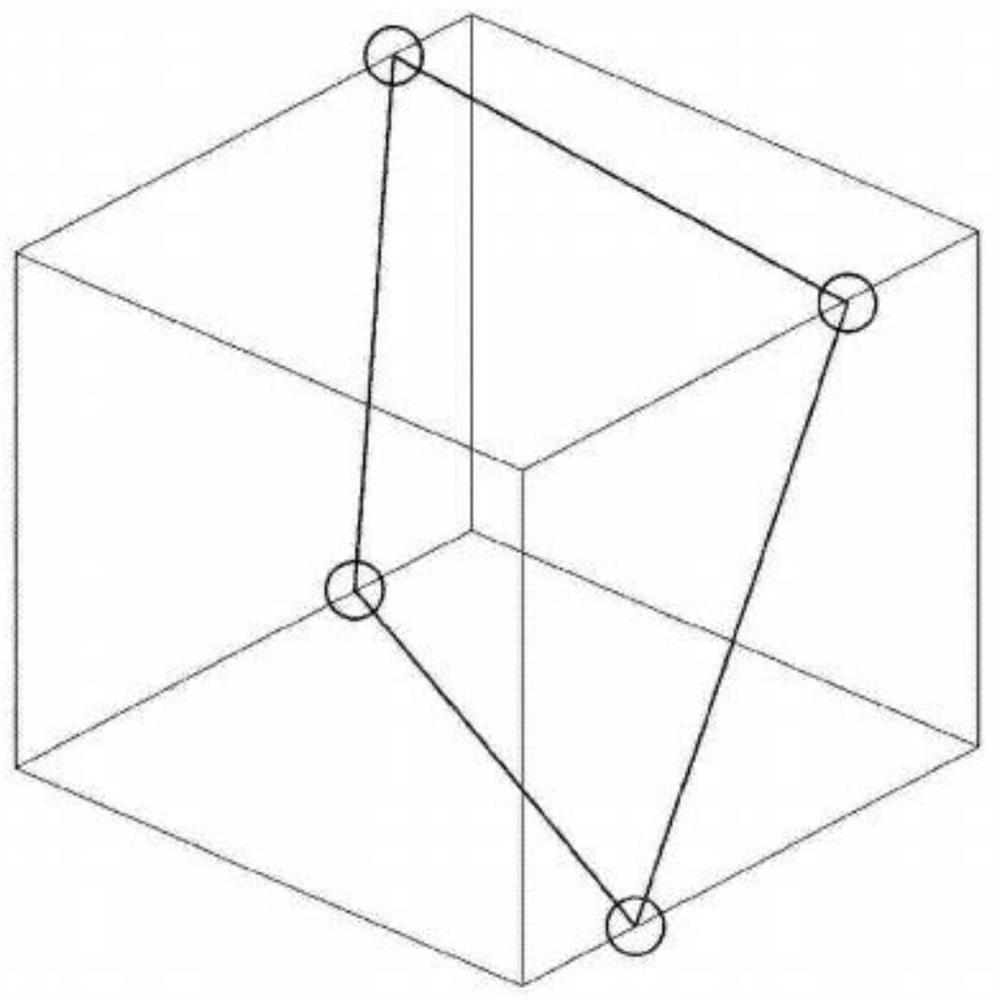
[0033] Step 3: Build a decentralized data sphere based on the data structure and data volume of each dispersed d...
Embodiment 2
[0040] On the basis of the previous embodiment, the range of the ratio set in the step 2 is: 3 to 8; the value range depends on the type of classified data; when the classified data is soil effective water content, the set The value of the ratio is 3; when the classified data is sand content, the set ratio is 4; when the classified data is silt content, the set ratio is 5; when the classified data is clay content, the set The value of the ratio is 6; when the classification data is soil bulk density, the set value of the ratio is 7; the value of the organic carbon content is 8.
Embodiment 3
[0042] On the basis of the previous embodiment, the method for constructing a scatter data sphere in step 3 specifically includes: calculating the data volume of the scatter data, using the calculated data volume of the scatter data as the radius of the scatter data sphere, using a preset The data sphere construction model is constructed, and a scattered data sphere is constructed so that the scattered data is evenly distributed on the outer surface of the scattered data sphere.
[0043] Specifically, the consistency check (consistency check) is to check whether the data meets the requirements according to the reasonable value range and interrelationship of each variable, and to find data that exceeds the normal range, is logically irrational, or is contradictory. For example, a variable measured with a scale of 1-7 has a value of 0, and a negative number of weight should be considered as exceeding the normal range. Computer software such as SPSS, SAS, and Excel can automatica...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com