Speech emotion recognition method and device based on meta-multi-task learning
A speech emotion recognition and multi-task learning technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problem of insufficient accuracy of speech emotion recognition
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
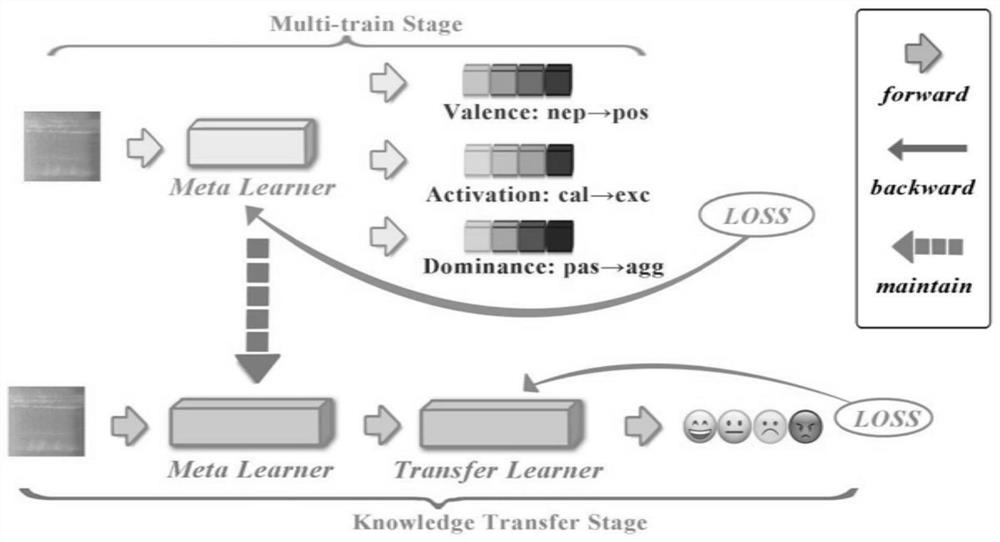
[0058] This embodiment provides a speech emotion recognition method based on meta-multi-task learning. Such as figure 1 As shown, the speech emotion recognition method based on meta-multi-task learning mainly includes the following two key stages:
[0059] 1) By combining meta-learning and multi-task learning, the correlation between auxiliary tasks is learned, corresponding to Multi-trainStage.
[0060] 2) Learning the ability to transfer knowledge from auxiliary tasks to main tasks, corresponding to KnowledgeTransferStage.
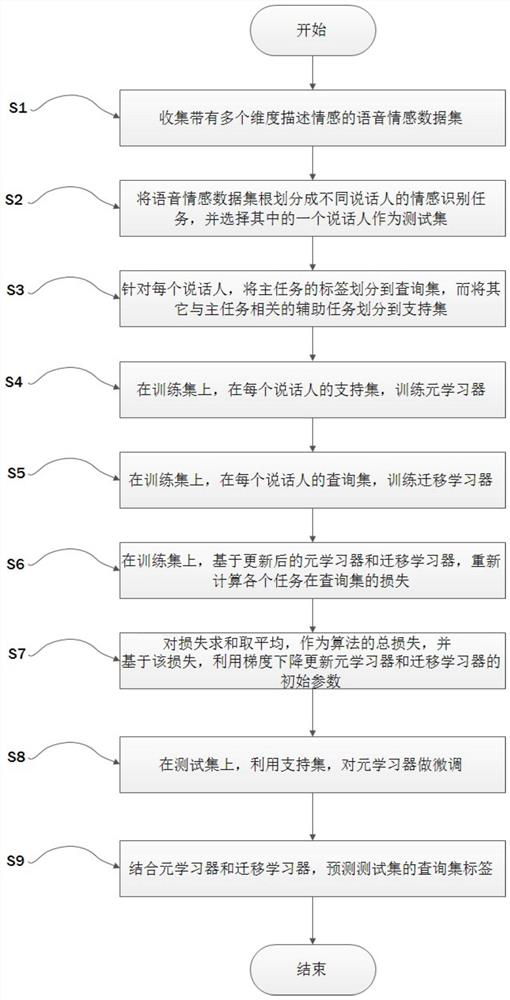
[0061] Such as figure 2 As shown, the speech emotion recognition method based on meta-multi-task learning specifically includes the following steps:
[0062] 1) Dataset collection: You can choose IEMOCAP, a dataset that describes emotions from the emotional dimensional space and the discrete dimensional space. Generally speaking, speech emotion can be represented by continuous emotion space, such as Valence-Arousal space, or by discrete emotion spac...
Embodiment 2
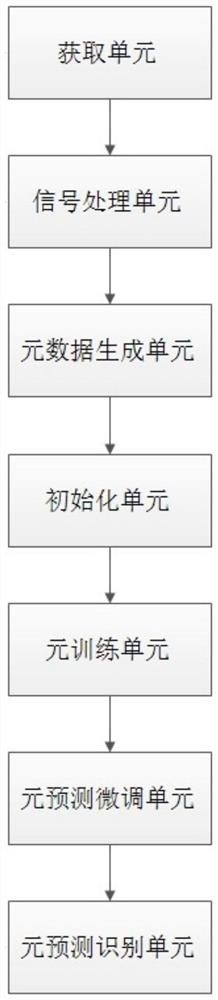
[0080] This embodiment provides a device for speech emotion recognition based on meta-multi-task learning, the device can implement the method described in Embodiment 1, such as image 3 As shown, the device includes:
[0081] 1) The acquisition unit is specifically configured as:
[0082] For the voice data set obtained, the discrete space emotion label is selected as the data corresponding to happiness, anger, sadness and neutrality. In addition to the discrete emotion space label, each section of voice is also marked with the label of the dimension emotion space. The dimension emotion space of the present embodiment, Select the Valence-Activation-Dominance space.
[0083] 2) The data processing unit is specifically configured as:
[0084] Slice the voice data in advance, so that the length of each voice slice is approximately equal and does not exceed 3 seconds, and then use Fourier transform, filter and other acoustic processing methods to extract the spectrogram from th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com