TOPK-based multi-channel sound source effective signal screening system and TOPK-based multi-channel sound source effective signal screening method
An effective signal and screening method technology, applied in the field of communication, can solve problems such as inability to separate and screen out effective signals
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
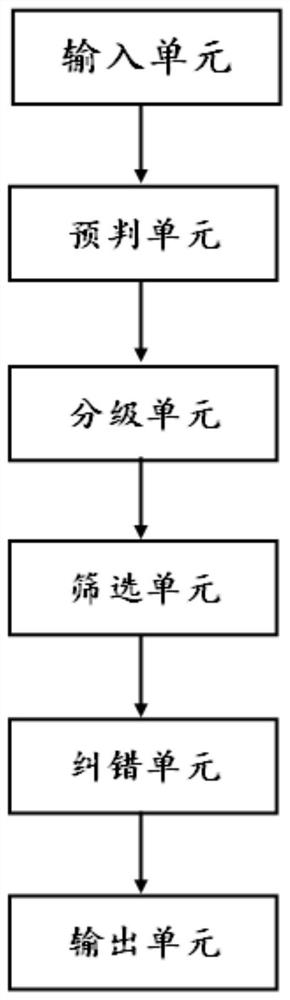
[0042] The embodiment is basically as attached figure 1 Shown: includes:
[0043] The input unit is used to input the mixed sound formed by N channels of voice and N channels of background sound;
[0044] The pre-judgment unit is used to use the VAD algorithm to predict each voice one by one: if the voice is normal, the VAD value is 1; if the voice output state is uncertain, the VAD value is 0; if there is no voice output, the VAD value is -1;
[0045] The grading unit is used to divide the voice signal with a VAD value of 1 into grades 1 to 10 by using the AMDF algorithm, and assign values;
[0046] The screening unit is used to receive N channels of voice signals, and filter out M channels of the strongest signals for the N channels of buffered signals at each time according to the set buffer amount;
[0047] The error correction unit is used to make use of the signal correlation and use the FEC algorithm to supplement the front-end voice signal lost due to the time delay of...
Embodiment 2
[0064] The only difference from Embodiment 1 is that in S5, the error correction unit first performs pre-processing on the strongest signals of M channels, including pre-emphasis processing, windowing processing and endpoint detection, and then performs sound processing on the strongest signals of M channels one by one. Fingerprint recognition, retain the strongest signal that matches the preset voiceprint characteristics, and delete the strongest signal that does not match the preset voiceprint characteristics, thereby removing noise.
[0065] Finally, wavelet decomposes the strongest signals of M channels one by one to obtain the wavelet signal sequence, and obtains the effective speech signal according to the wavelet signal sequence. Specifically, for the M strongest signals, wavelet decomposition is performed on the audio frame signals one by one, so as to obtain multiple wavelet decomposition signals corresponding to each audio frame signal, each wavelet decomposition sign...
Embodiment 3
[0067] The only difference from Embodiment 2 is that, before classifying the multi-channel sound sources, the multi-channel speech is firstly complemented. Specifically, the text corpus related to classroom live teaching is pre-stored on the server. When the network signal is not good, the voice signal may be intermittent, and part of the voice signal is missing. At this time, it is necessary to correct the missing voice The signal is complemented.
[0068] First of all, when the network signal is not good, extract the speech signal of the front and back parts of the intermittent speech signal, and convert it into text, and use the semantic recognition algorithm combined with the text corpus to make corresponding text for the missing speech signal content filling. That is, fill in the text content corresponding to the missing speech signal according to the semantic understanding, and convert the text content into a speech signal, so as to realize the completion of the discont...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com