Decentralized distributed data processing system
A distributed data and processing system technology, applied in the field of big data processing, can solve problems such as data processing bottlenecks, high dependence, and low system reliability, and achieve high reliability effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
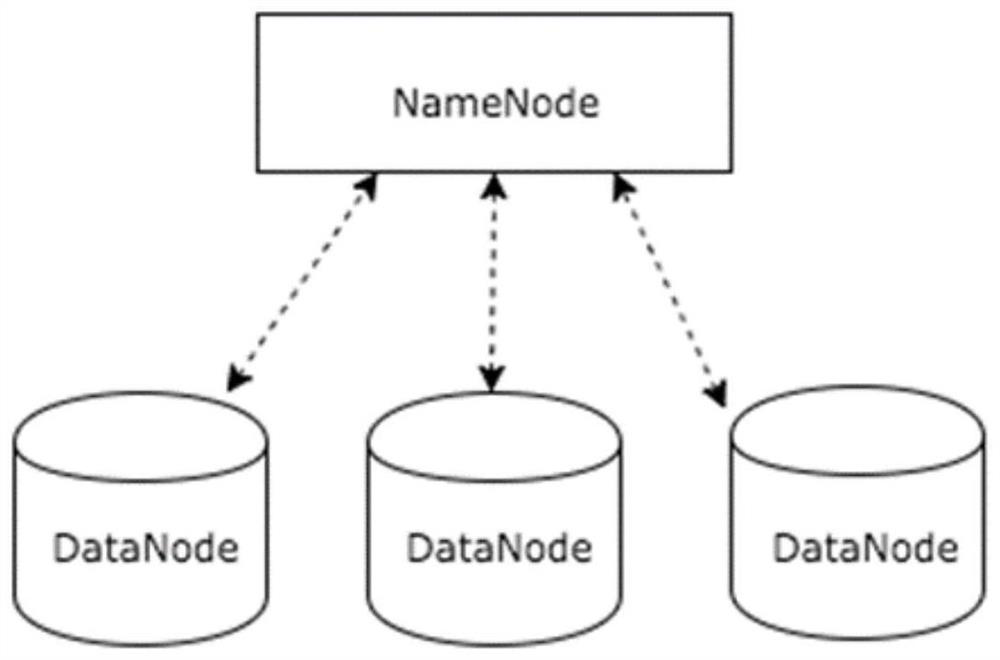
[0033] See figure 2 , Apache Hadoop is a distributed system with a master-slave architecture. A Hadoop computing cluster has a central node NameNode and hundreds of DataNodes. NameNode is a dedicated server that contains tree-like namespace information and file area information mapped to DataNode to find the physical location of file data. The application data is stored on other servers called DataNodes.
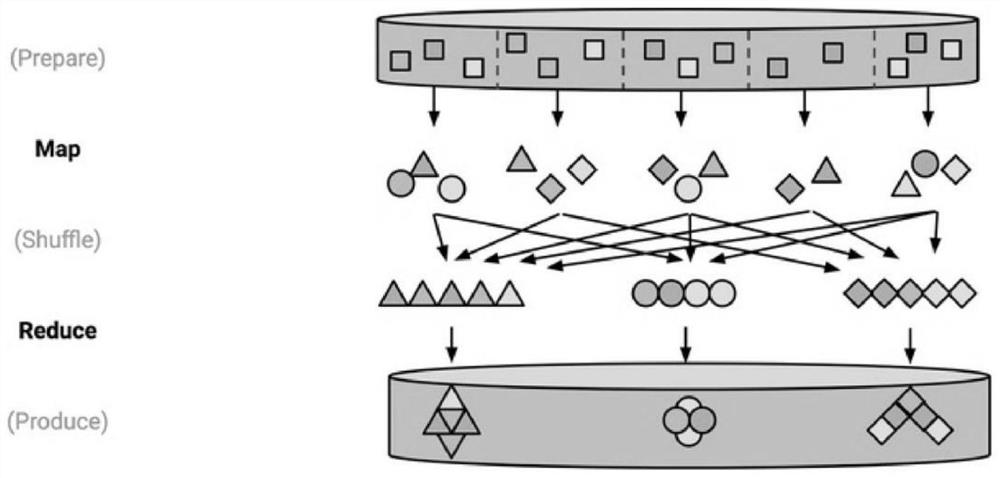
[0034] MapReduce is the programming model used by Hadoop to process large-scale data sets. The user defines a Map function to process key / value pairs of data, thereby generating a series of intermediate key-value pairs, and then uses a Reduce function to merge the same intermediate key-value pairs.
[0035] The Map function can call the distributed server to automatically partition the input data into m blocks. These blocks can be processed by distributed servers in parallel to obtain an intermediate key-value pair space. The Reduce function can use the partition hash f...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com