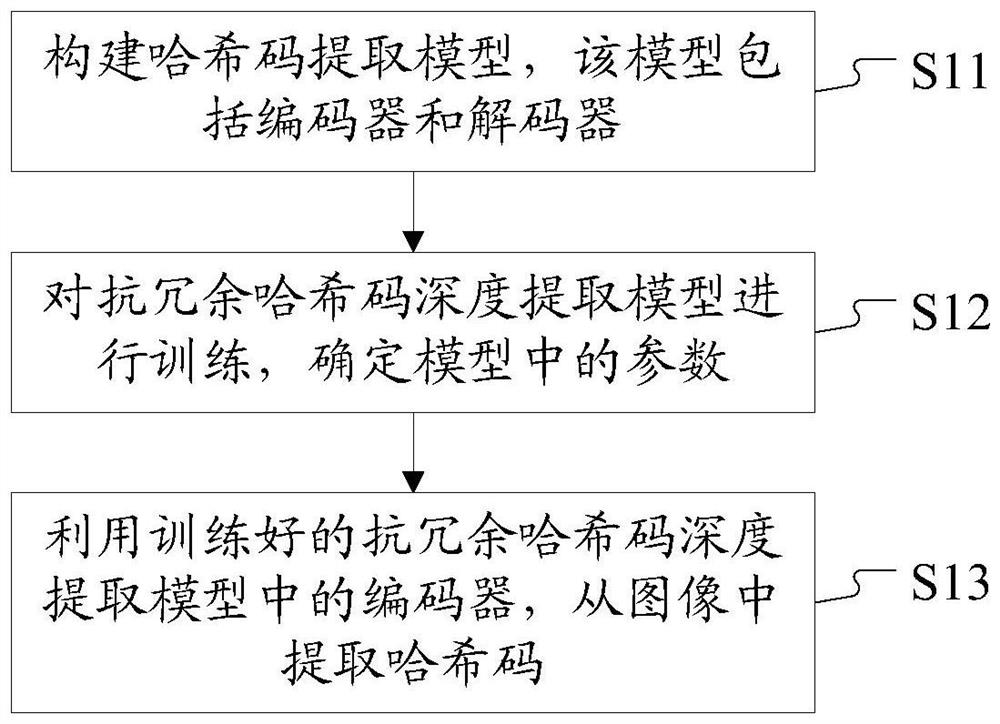
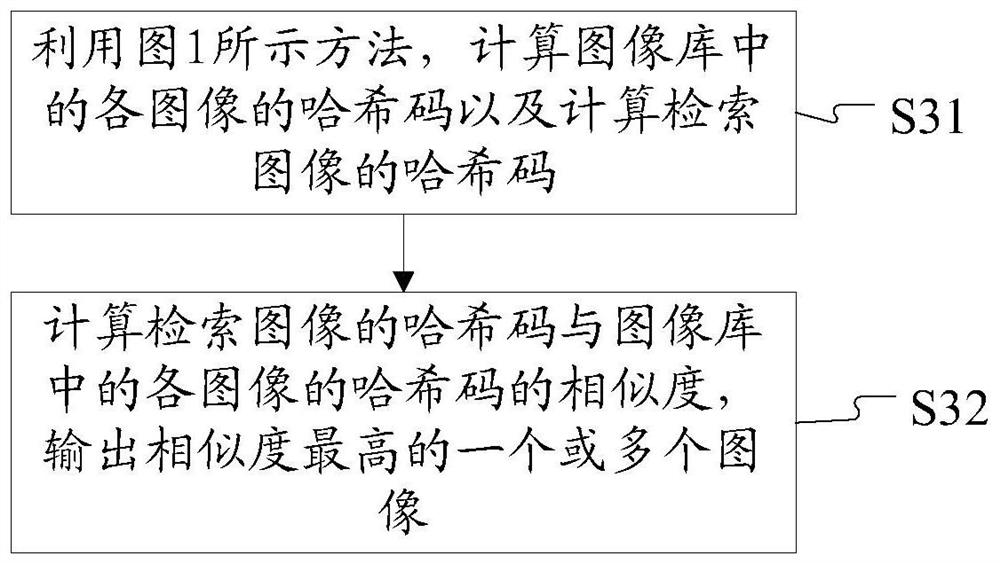
Method and device for extracting hash code from image and image retrieval method and device
An image-in-redundant hash code technology, applied in still image data retrieval, metadata still image retrieval, image coding, etc., can solve the problems of image retrieval accuracy decline, hidden layer unit collapse, insufficient coding space utilization, etc. , to achieve the effect of improving the accuracy and reducing the redundancy of coding spatial information
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
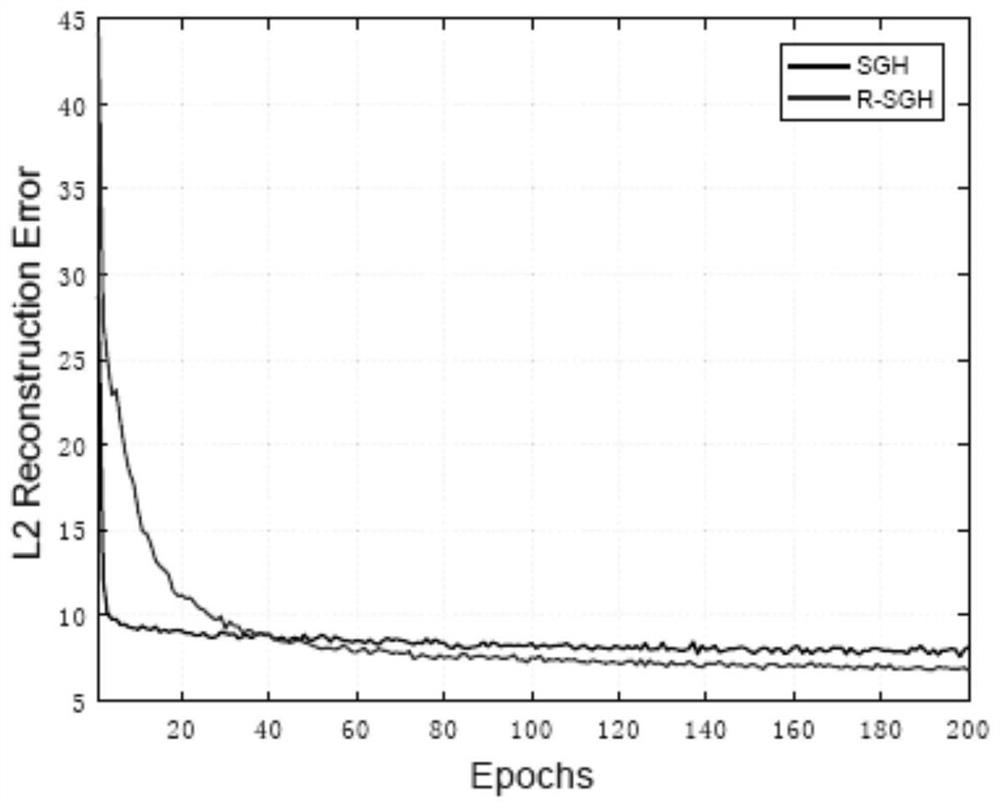
[0152] Embodiment 1, MNIST data and image reconstruction
[0153] Network parameter settings: the number of encoder and decoder layers M is set to 1, δ and η are 0.01, and the prior parameters ρ j is 0.5, the threshold parameter is set to 0.05, the encoder input data and decoder output data dimensions are 28*28=784, the hash code and the hidden layer data dimensions of the encoder and decoder are 64;
[0154] The training data set is the training set of MIST; the batch size of data samples used in each step of training is set to 32; the image reconstruction error of the model is evaluated at different numbers of training rounds, and the evaluation uses the MIST test set, which is extracted by the encoder. The code and decoder generate reconstructed data, and calculate the error between input and reconstructed data. The calculation method is as follows:
[0155]
[0156] Where N is the number of evaluation samples, D is the dimensionality of each sample data, x is the input...
Embodiment 2
[0158] Embodiment 2, CIFAR-10 image retrieval
[0159] Network parameter settings: the number of encoder and decoder layers M is set to 4, δ is 0.01, η is 0.01, the prior parameter ρj is 0.5, the threshold parameter is set to 0.05, the dimension of encoder input data and decoder output data is 512, The data dimensions of the hash code and the hidden layers of the encoder and decoder are 32, 64 and 128;
[0160] 100 sample data are randomly selected from each of the 10 types of data in the CIFAR-10 dataset, a total of 1000 sample data are used as the retrieval input during testing, and the rest of the data are training samples and image databases. For each step of training, the batch size of data samples is set to 32, and the number of training rounds is 200.
[0161] Use the mAP index to evaluate the image retrieval ability. The mAP results of the three models with hash code dimensions of 32, 64 and 128 are shown in Table 1. Table 1 shows the mAP (%) test results of SGH and R...
Embodiment 3
[0165] Embodiment 3, Caltech-256 image retrieval
[0166] Network parameter settings: the number of encoder and decoder layers M is set to 4, δ is 0.01, η is 0.01, and the prior parameter ρ j is 0.5, the threshold parameter is set to 0.05, the encoder input data and decoder output data dimensions are 512, the hash code and the hidden layer data dimensions of the encoder and decoder are 32, 64 and 128;
[0167] 1000 sample data are randomly selected from the Caltech-256 dataset as the retrieval input during testing, and the rest of the data are training samples and image libraries. For each step of training, the batch size of data samples is set to 32, and the number of training rounds is 200.
[0168]Use the mAP index to evaluate the image retrieval ability. The mAP results of the three models with hash code dimensions of 32, 64 and 128 are shown in Table 2. Table 2 shows the mAP (%) test results of SGH and R-SGH in the Caltech-256 data set :
[0169] Table 2 SGH and R-SGH ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com