Rapid large-scale point-cloud data reading method based on memory pre-distribution and multi-point writing technology
A technology of memory pre-allocation and point cloud data, which is applied in the direction of memory address/allocation/relocation, concurrent instruction execution, machine execution device, etc. Improve user experience, increase reading speed, and improve the effect of reading speed
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

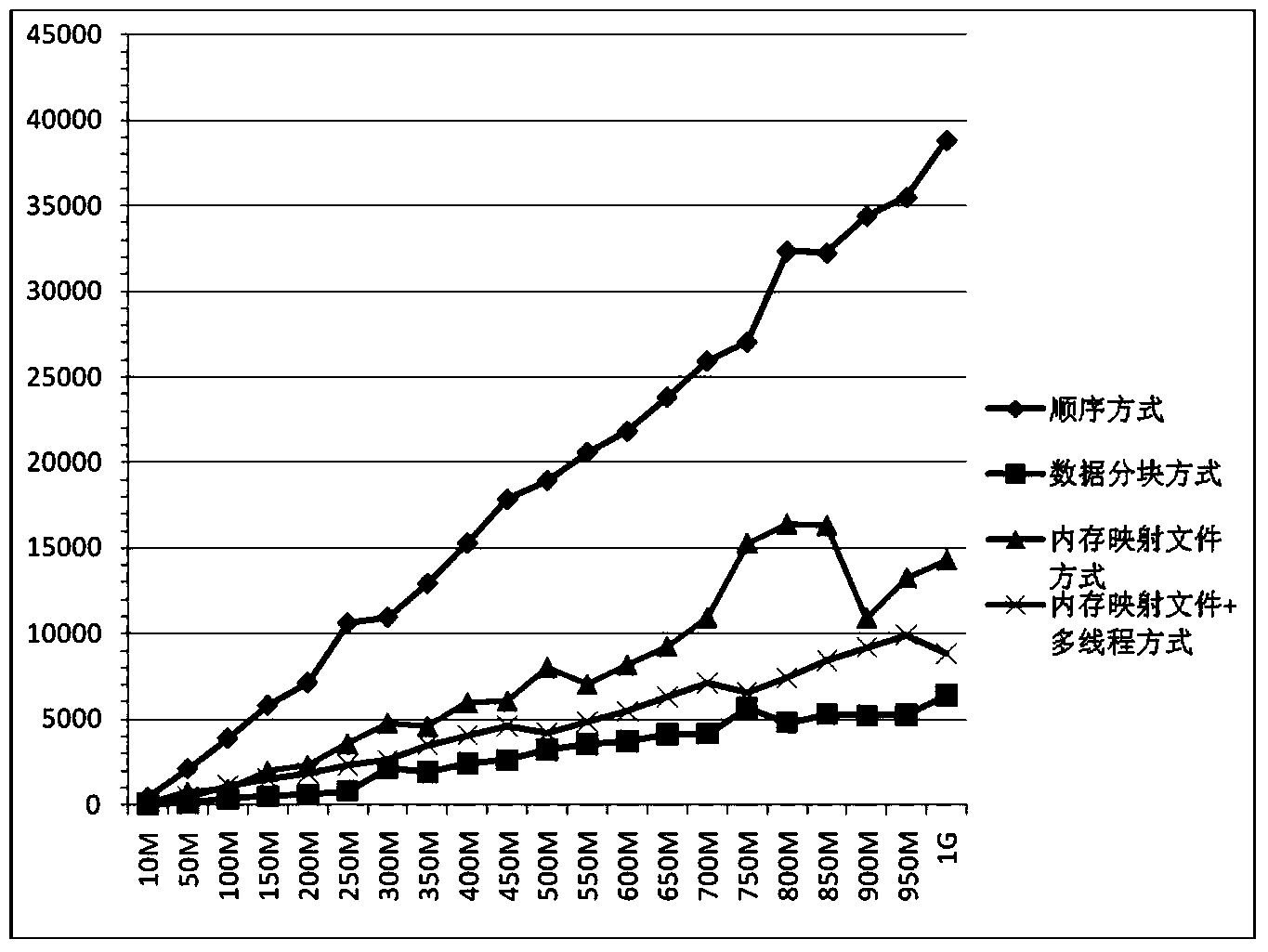

Examples
specific Embodiment approach 1
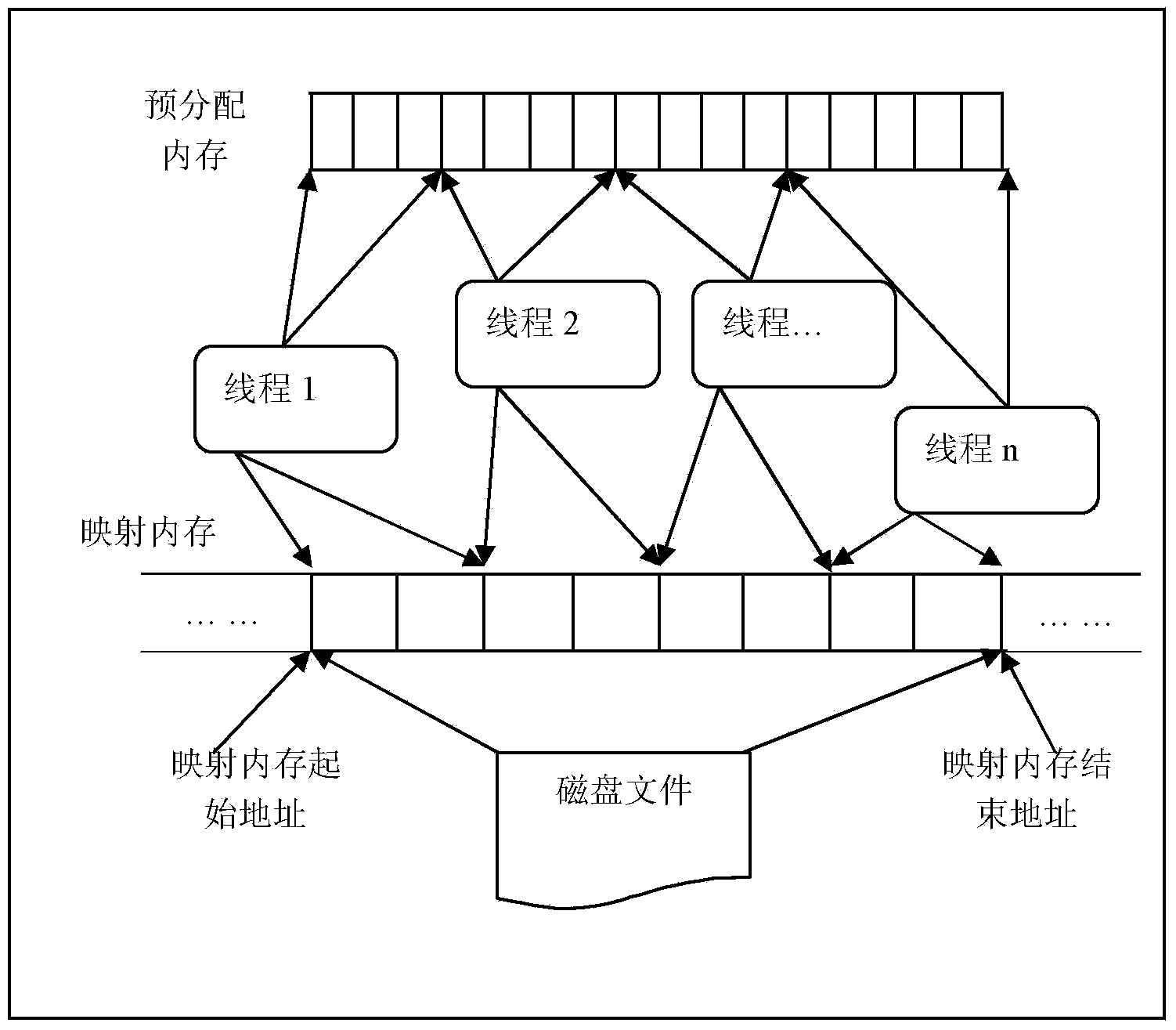
[0020] Specific implementation mode one: as figure 2 with 3 As shown, a method for quickly reading large-scale point cloud data based on memory pre-allocation and multi-point parallel writing technology described in this embodiment is characterized in that the method is:
[0021] Step A, memory pre-allocation process: first determine the number of points in the point cloud data file, so as to determine the memory size that all points in the point cloud data file need to occupy, and then pre-allocate memory of the corresponding size for the point cloud data;
[0022] Step B, multi-point writing process: through the memory-mapped file mechanism, map the point cloud data file to the mapped memory and create a thread pool with a specified number of threads. Each thread is responsible for parsing part of the point data information in the mapped memory, and The parsing results are written to the previously pre-allocated memory to achieve multi-point and write.
[0023] Step A is ...
specific Embodiment approach 2
[0024] Specific embodiment two: as shown in Figure 2, this embodiment is the specific implementation process of the large-scale point cloud data fast reading method based on memory pre-allocation and multi-point parallel writing technology described in specific embodiment one:
[0025] Step 1. Select the point cloud data file,
[0026] Step 2, determine the number of points in the point cloud data file, and determine the number of points in the point cloud data file by means of data block,
[0027] Step 3. Allocate memory of corresponding size: determine the memory size that all points in the point cloud data file need to occupy according to the number of points in the point cloud data file, and then pre-allocate memory of the corresponding size for the point cloud data;
[0028] Step 4: Map the point cloud data file into the mapped memory,
[0029] Step 5. Create a thread pool with a specified number of threads,
[0030] Step 6. Divide the mapped memory file into blocks, an...
specific Embodiment approach 3
[0033] Specific implementation mode three: in this implementation mode, the specific operation process of the data block mode described in step 2 is: allocate a memory buffer (such as 64KB) of a specified size, and use the file I / O function to read the memory buffer of this size File data, and find the number of newline characters ("\n") from the data to determine the number of points in the block data; if the last character in the block data is not a newline character, it indicates the last character of the block data A point data is incomplete, move the file pointer forward at this time, so that the pointer position points to the starting position of this point data; then re-use the file I / O function to read a new piece of file data, and repeat this process until the middle point of the file The data calculation is completed. Other compositions and connections are the same as those in Embodiment 1 or 2.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com