Formant-based speech synthesizer employing demi-syllable concatenation with independent cross fade in the filter parameter and source domains
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
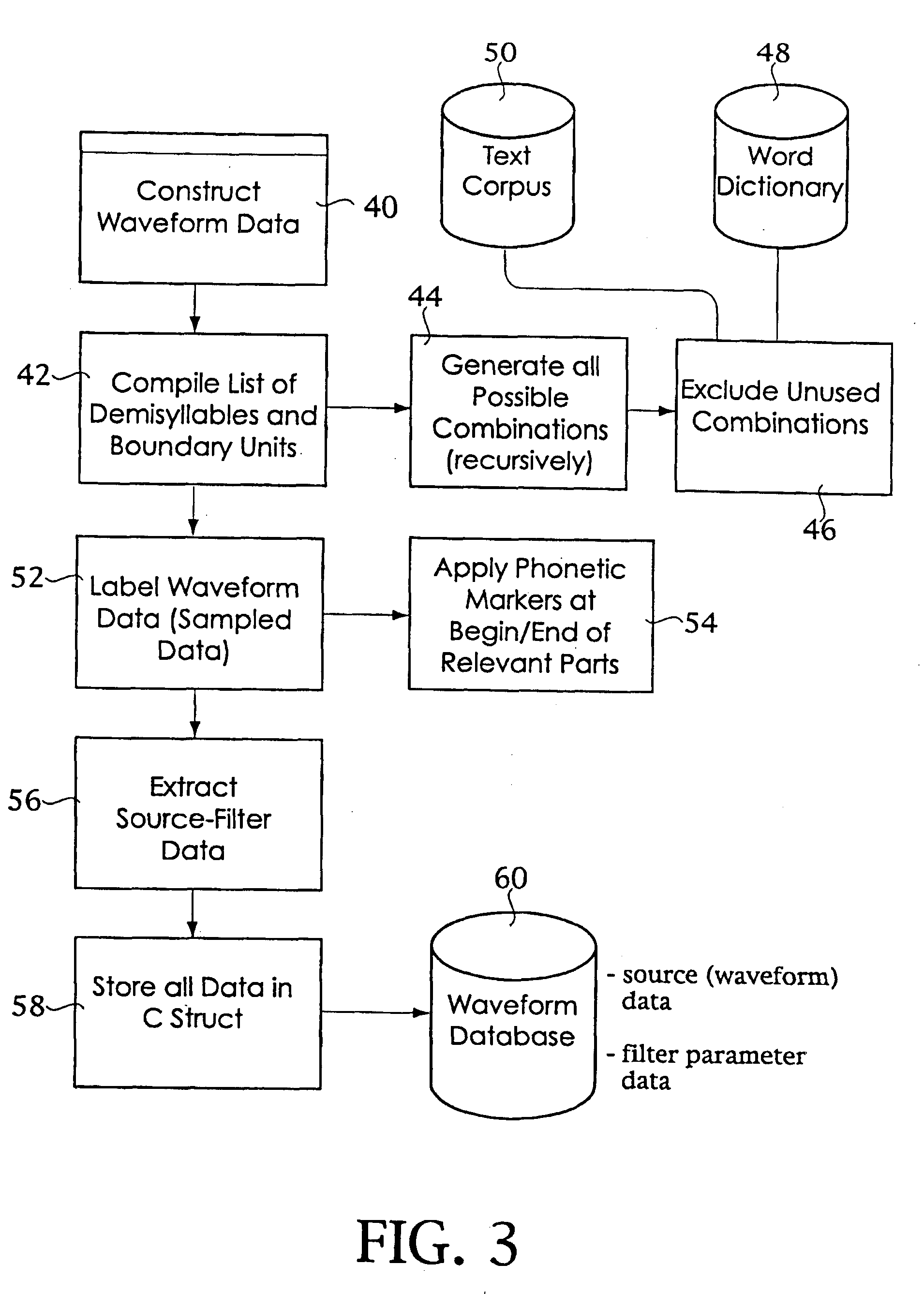
Embodiment Construction
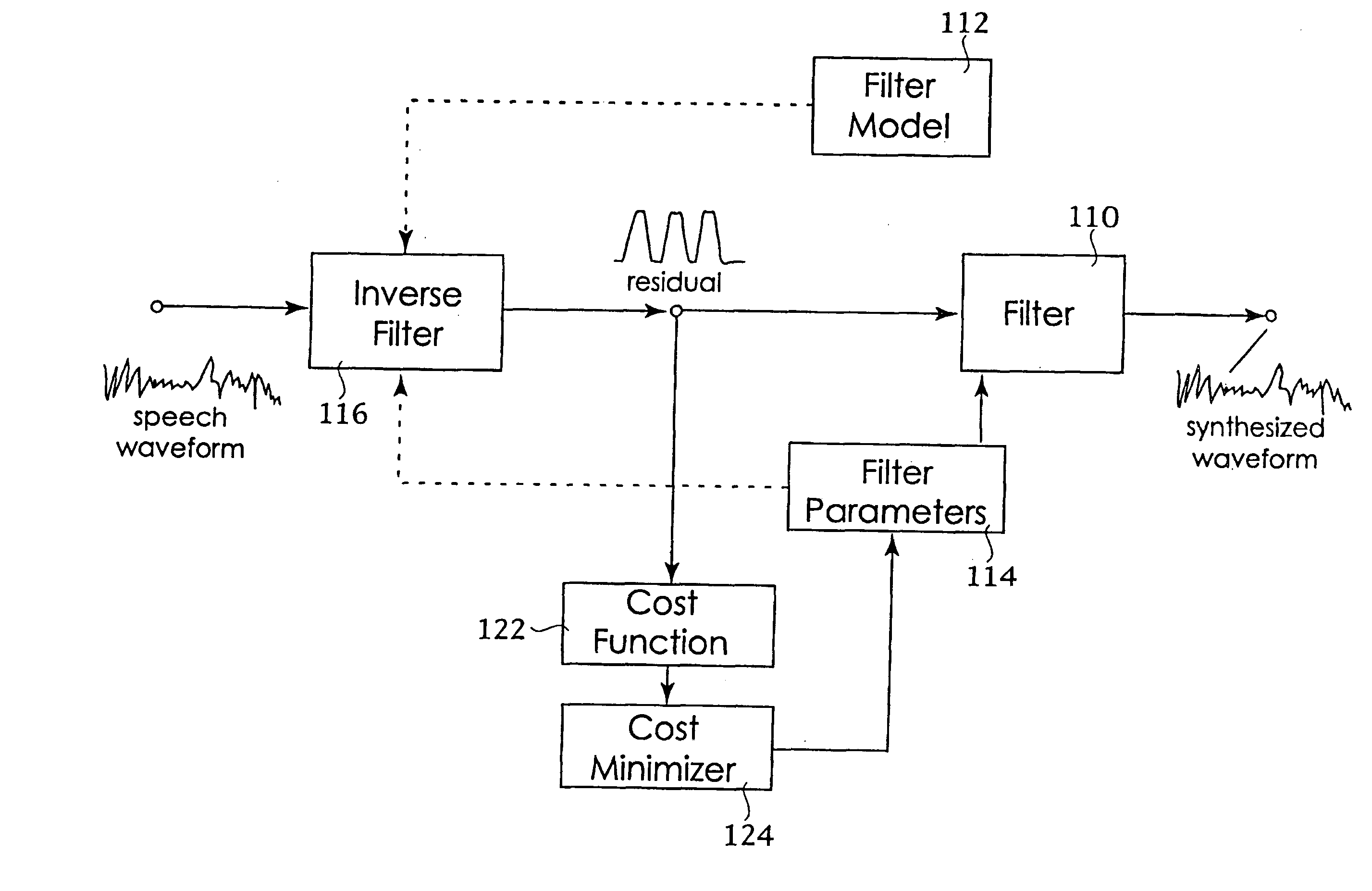
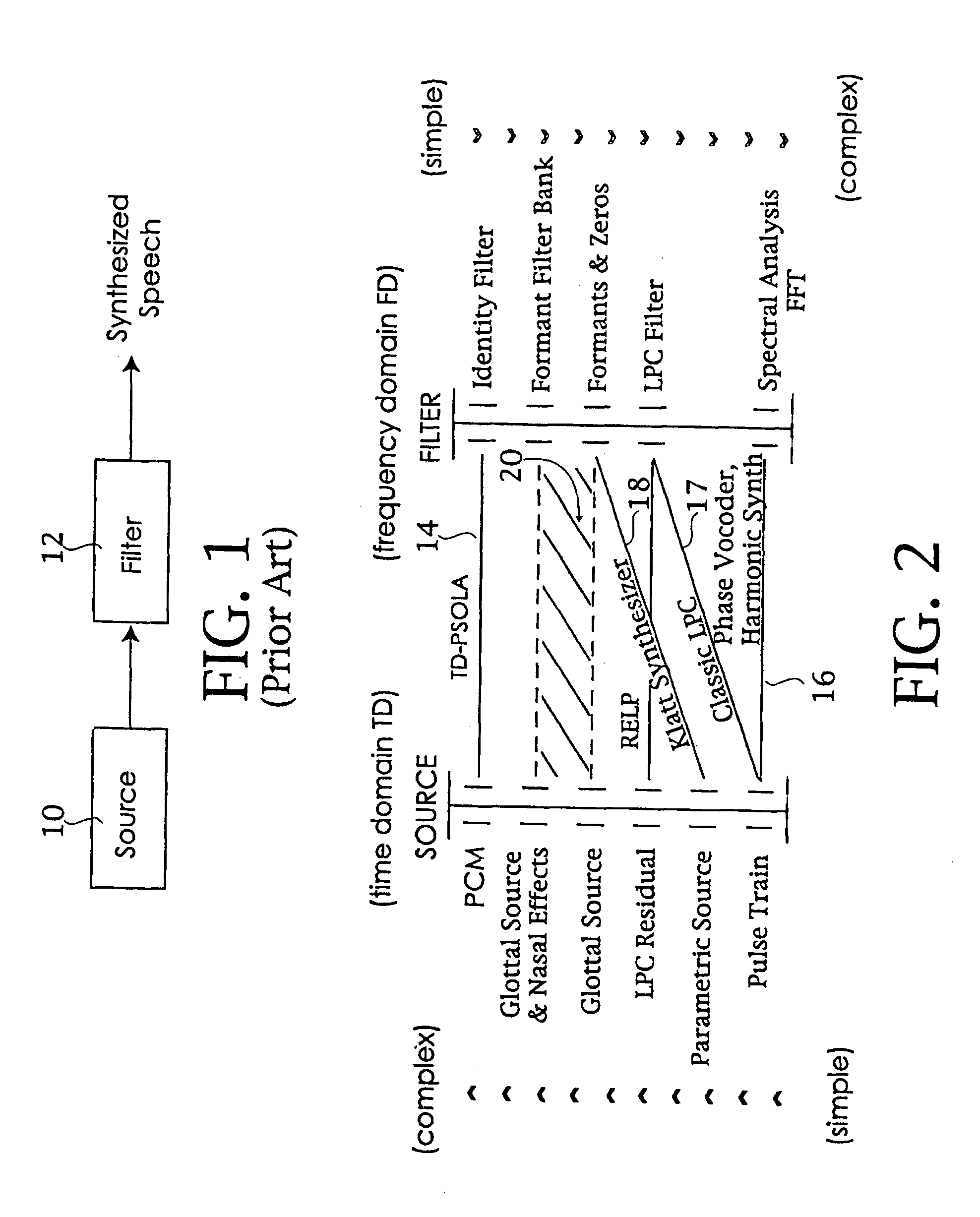
[0017]While there have been many speech synthesis models proposed in the past, most have in common the following two component signal processing structure. Shown in FIG. 1, speech can be modeled as an initial source component 10, processed through a subsequent filter component 12.
[0018]Depending on the model, either source or filter, or both can be very simple or very complex. For example, one earlier form of speech synthesis concatenated highly complex PCM (Phase Code Modulated) waveforms as the source, and a very simple (unity gain) filter. In the PCM synthesizer all a prior knowledge was imbedded in the source and none in the filter. By comparison, another synthesis method used a simple repeating pulse train as the source and a comparatively complex filter based on LPC (Linear Predictive Coding). Note that neither of these conventional synthesis techniques attempted to model the physical structures within the human vocal tract that are responsible for producing human speech.
[0019...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com