Chinese text data word vector representation method based on BIE position word list
A technology of text data and word vectors, applied in digital data processing, natural language data processing, instruments, etc., can solve the problems of lexical information loss and difficulty in wide application, achieve high accuracy, and improve the ability to solve entity nesting problems effect of ability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
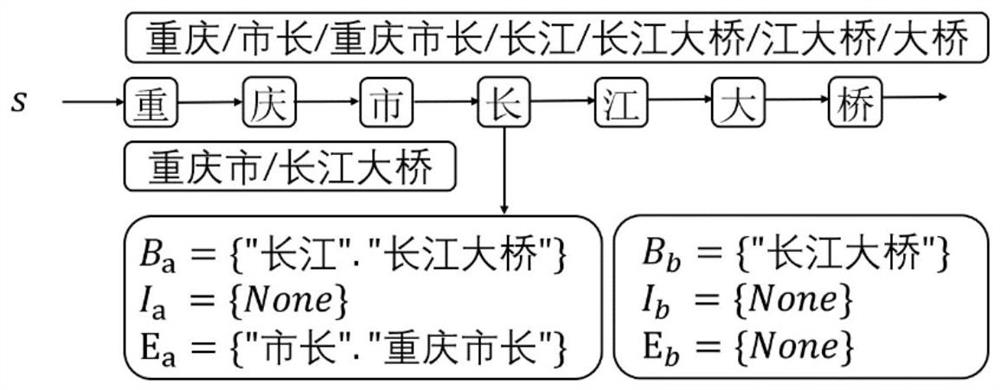
[0046] refer to figure 1 , figure 1 A flow chart of a method for characterizing Chinese text data word vectors based on a BIE position word list provided by an embodiment of the present invention, specifically including:
[0047] It is difficult for Chinese text word vectors to express the position and boundary information of Chinese words, which brings great challenges to Chinese named entity recognition. Therefore, in this embodiment, the discussion mainly focuses on the Chinese text data set.
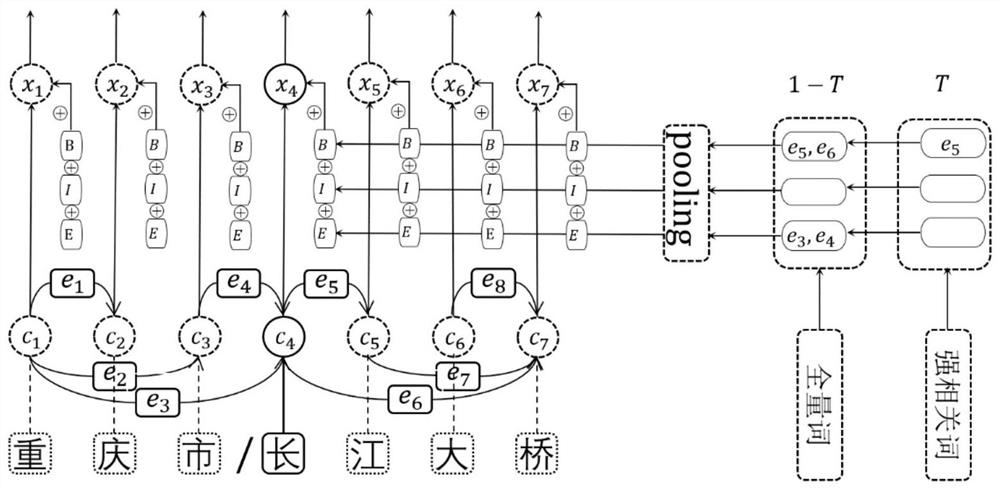
[0048] How to express the position information of the word in the corresponding word in the word vector is the key of the present invention. In the Chinese entity recognition task, learning lexical boundaries can help the model distinguish entity boundaries, so the three position dimensions of BIE are used to express the position information of words in words. At the same time, in order to take into account the full quantifier set and the strong related word set, the weight T is u...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com