Image retrieval method based on depth feature consistent Hash algorithm
A hash algorithm and image retrieval technology, applied in the field of deep learning, can solve problems such as the image similarity ranking that cannot be well reflected, achieve retrieval accuracy and time advantages, improve retrieval performance, and improve the effect of loss function
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
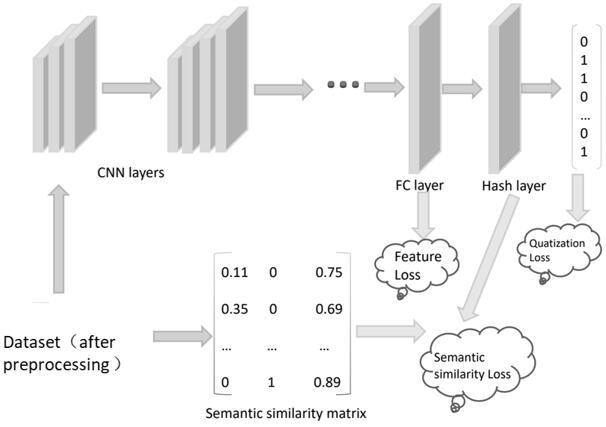
[0059] A kind of image retrieval method based on depth feature consistent hashing algorithm, comprises the following steps (such as figure 1 shown):
[0060] S1: First, get the semantic similarity matrix according to the label of the image data (such as figure 1 Semanticsimilarity matrix (semantic similarity matrix) part);
[0061] Given n training set images I={I 1 , I 2 , … , I n}, the value of n is a positive integer; first, the similarity matrix is calculated using the labels. The traditional calculation method is, if I i and I j have any same label, then s ij =1, otherwise s ij =0. Follow the method of the predecessors, use the percentage to calculate s; the formula is as follows:
[0062] (1)
[0063] Among them, li and lj represent the label vectors of images Ii and Ij; represents the inner product of images Ii and Ij; according to formula (1), images are divided into two categories: strong similarity and weak similarity. Strong similarity is divided ...
Embodiment 2
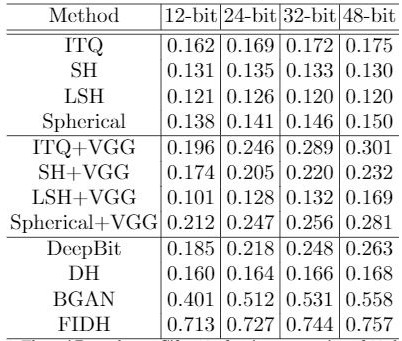
[0095] In order to verify the effectiveness of the method, experiments were carried out on the widely used datasets Flickr and Cifar-10, and compared with other state-of-the-art methods. Flickr is a dataset containing 25,000 images, each image has at least a label. Resize the image to 227×227, an image may contain multiple labels. Cifar-10 is a color image dataset that is closer to general objects. Cifar-10 is a small dataset compiled by Hinton's students Alexkrizhevsky and Ilyasutskever to identify cosmic objects. There are 10 categories: Airplane, Car, Bird, Cat, Deer, Dog, Frog, Horse, Boat and Truck. The size of each image is 32×32, and each category has 6000 images. There are 50000 training images and 10000 testing images in the dataset.
[0096]For Flickr, 4000 images are randomly selected as the training set and 1000 images as the test set. Set λ=0.1, because λ will lead to more discretization, and too small value of λ will reduce the impact of the quantization los...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com