Method, device, equipment and medium for speech recognition
A speech recognition and to-be-recognized technology, applied in the field of speech recognition technology and deep learning, can solve the problems of low speech recognition accuracy, decreased test set recognition rate, information loss, etc., to achieve smooth graphics, increase recognition, and reduce input. The effect of feature loss
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
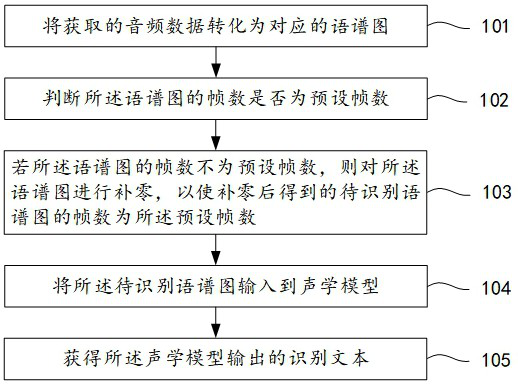
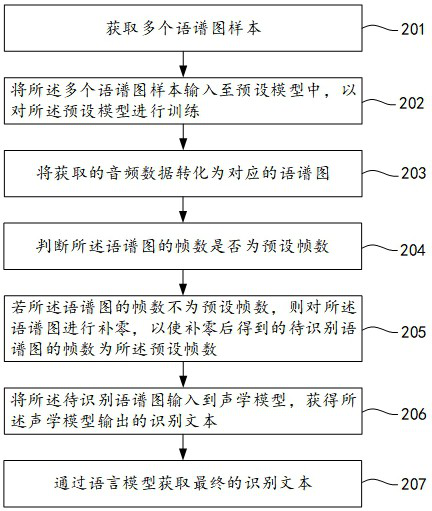
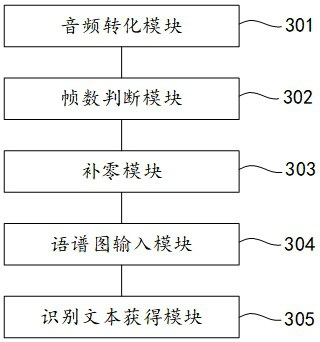
[0052] Exemplary embodiments of the present invention will be described in more detail below with reference to the accompanying drawings. Although exemplary embodiments of the present invention are shown in the drawings, it should be understood that the invention may be embodied in various forms and should not be limited to the embodiments set forth herein. Rather, these embodiments are provided for more thorough understanding of the present invention and to fully convey the scope of the present invention to those skilled in the art.
[0053] The core idea of the present invention is to determine the loss function of the preset model according to the text label of the spectrogram and the reconstructed image, directly input the spectrogram to the acoustic model obtained through training, and the acoustic model outputs the recognized text. Compared with the information loss in the frequency domain caused by calculating MFCC features in the prior art, the present invention redu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com