Variable-length input super-resolution video reconstruction method based on deep learning
A technology of super-resolution and deep learning, which is applied in the field of variable-length input super-resolution video reconstruction based on deep learning, and can solve problems such as inaccurate alignment of long input image sequences
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


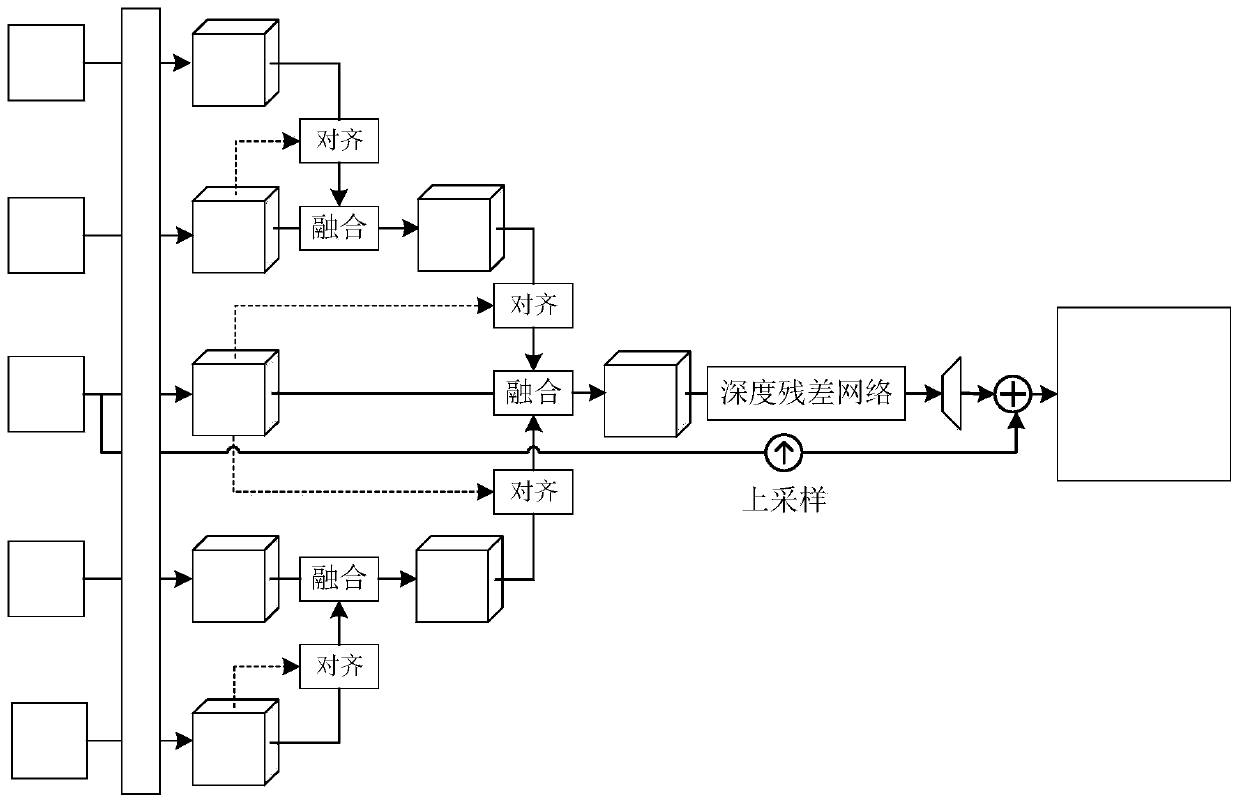
Examples
Embodiment Construction
[0073] In order to describe in detail the technical content, operation flow, achieved purpose and effect of the present invention, the following embodiments are given.
[0074] A variable-length input super-resolution video reconstruction method based on deep learning includes the following steps:
[0075] Step 1. Construct training samples of random length and obtain training set;
[0076] Exemplarily, the process of obtaining training samples of random length:
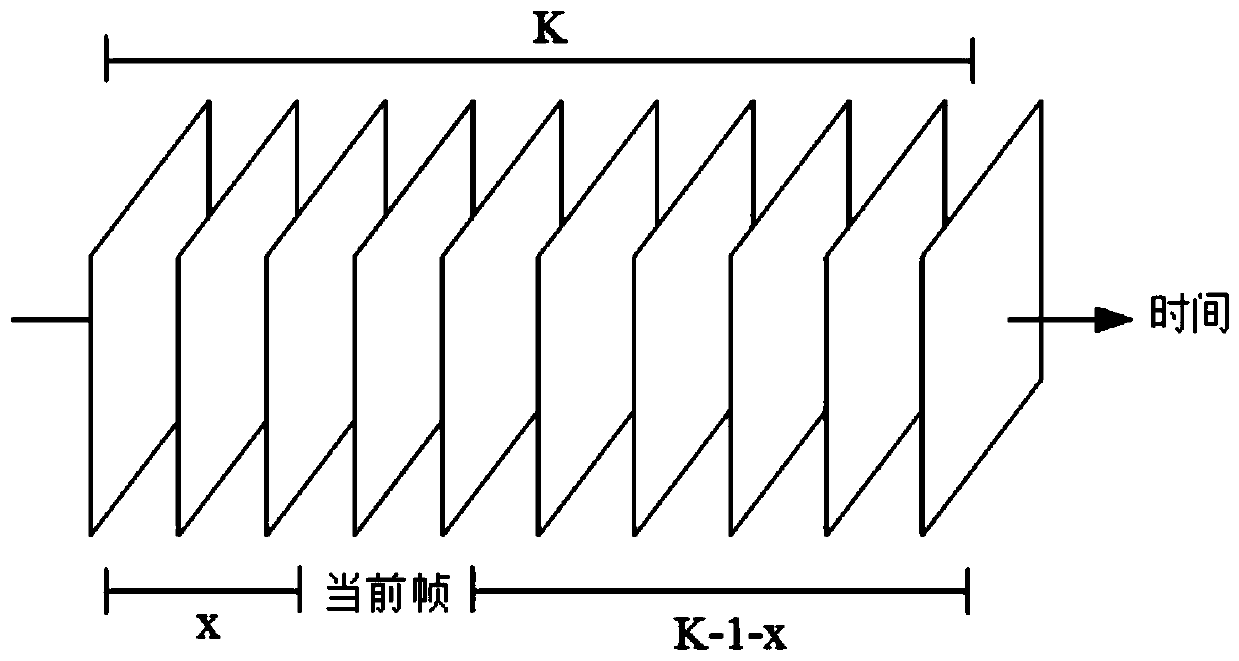
[0077] First, given the input sequence length K, K>0; select the data set;
[0078] Secondly, given the target frame to be reconstructed;
[0079] Finally, select the x frame image on the left side of the target frame and the K-1-x frame image on the right side of the target frame, and arrange the K frame images in order from left to right to obtain the input image sequence;
[0080] Among them, x is an integer randomly obtained by uniform distribution, and x=0, 1,..., K-1.
[0081] The length of the input sequence in the present...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com