


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Game strategy optimization method and system and storage medium
An optimization method and strategy technology, applied in the field of artificial intelligence, can solve problems such as credit allocation, Markov failure, inaccurate optimal response strategy and average strategy, and achieve the effect of improving accuracy and balancing exploration and utilization
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
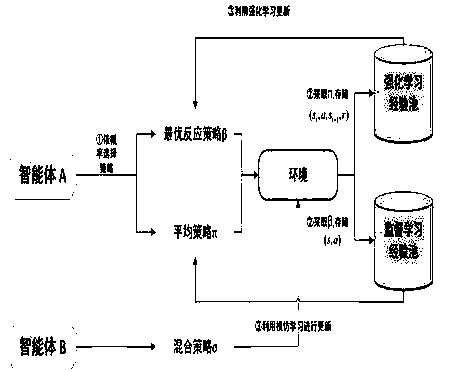
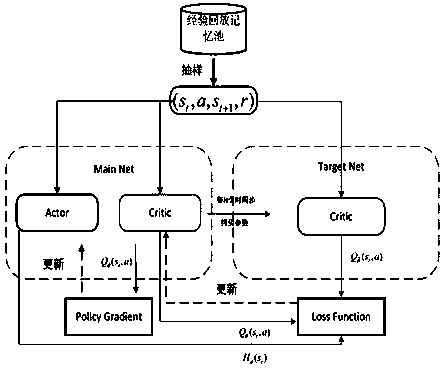
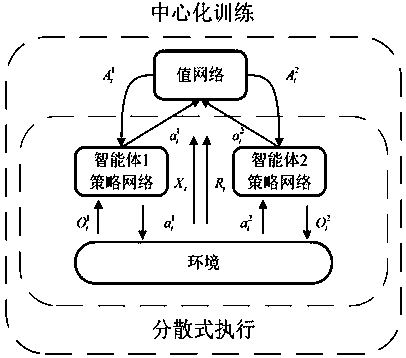
[0028] Aiming at the problem that the virtual self-play algorithm (NFSP) cannot be effectively extended to multi-player complex games, the present invention discloses a game strategy optimization method, which is realized based on multi-agent reinforcement learning and virtual self-play , using centralized training and decentralized execution to improve the accuracy of the action evaluation network, and at the same time introducing a global baseline reward to more accurately measure the action income of the agent, so as to solve the credit allocation problem in the human game. At the same time, the maximum entropy method is introduced to evaluate the policy, which balances the exploration and utilization in the process of policy optimization.
[0029] Assumptions and Definitions:
[0030] Reinforcement learning is defined as learning how to map from a state to an action in order to maximize a numerical reward signal. The process of reinforcement learning can be regarded as th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com