Monophonic speaker separation model, training method and separation method
A speaker separation, monophonic technology, applied in the field of deep learning, can solve problems such as customer emotional fluctuations, clustering algorithm interference, etc., to achieve the effect of low production cost, high accuracy, and strong robustness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

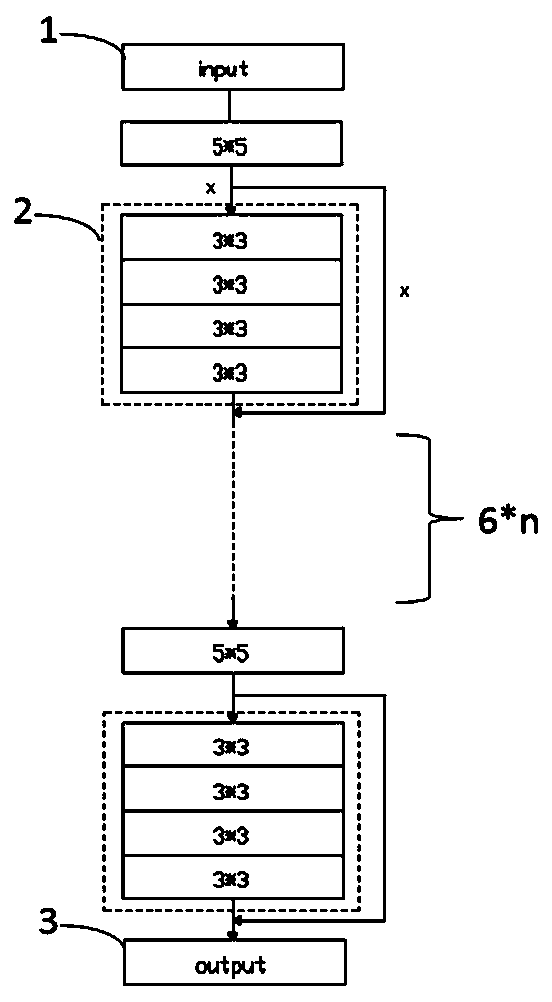
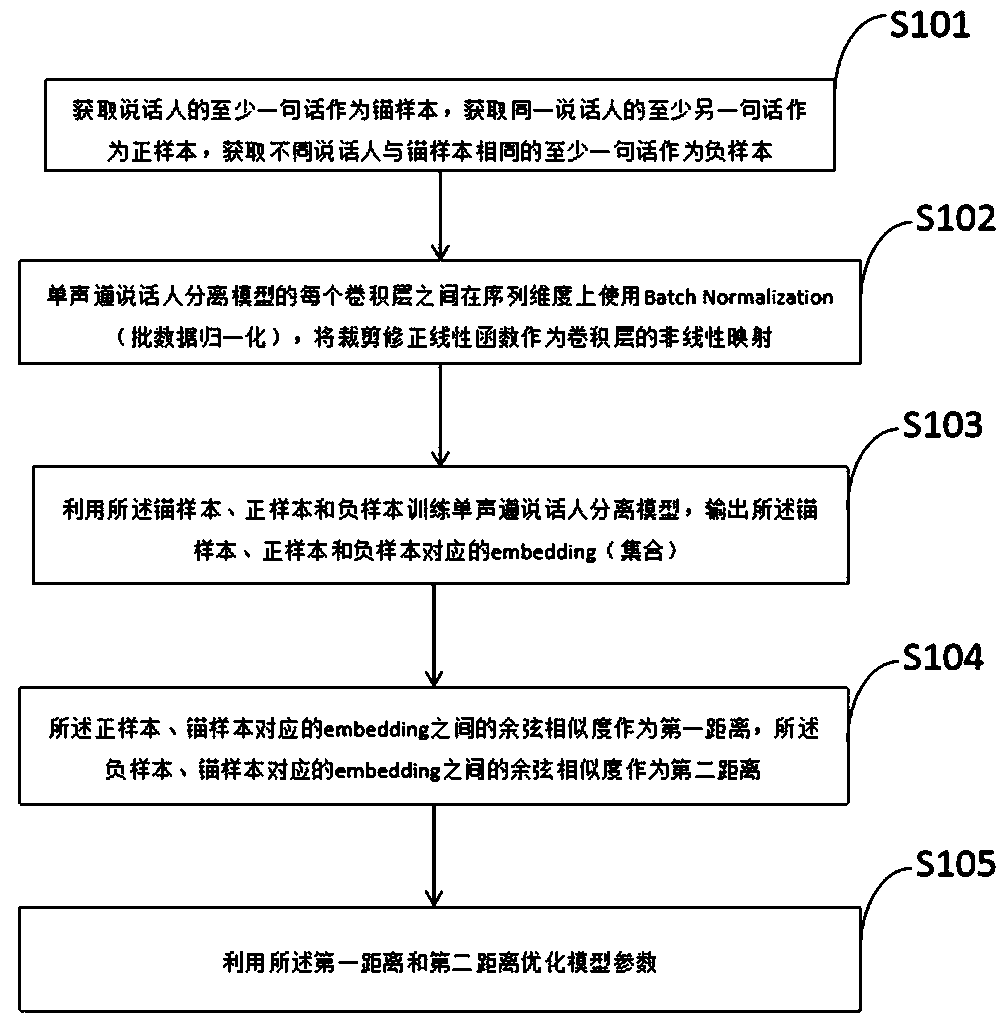
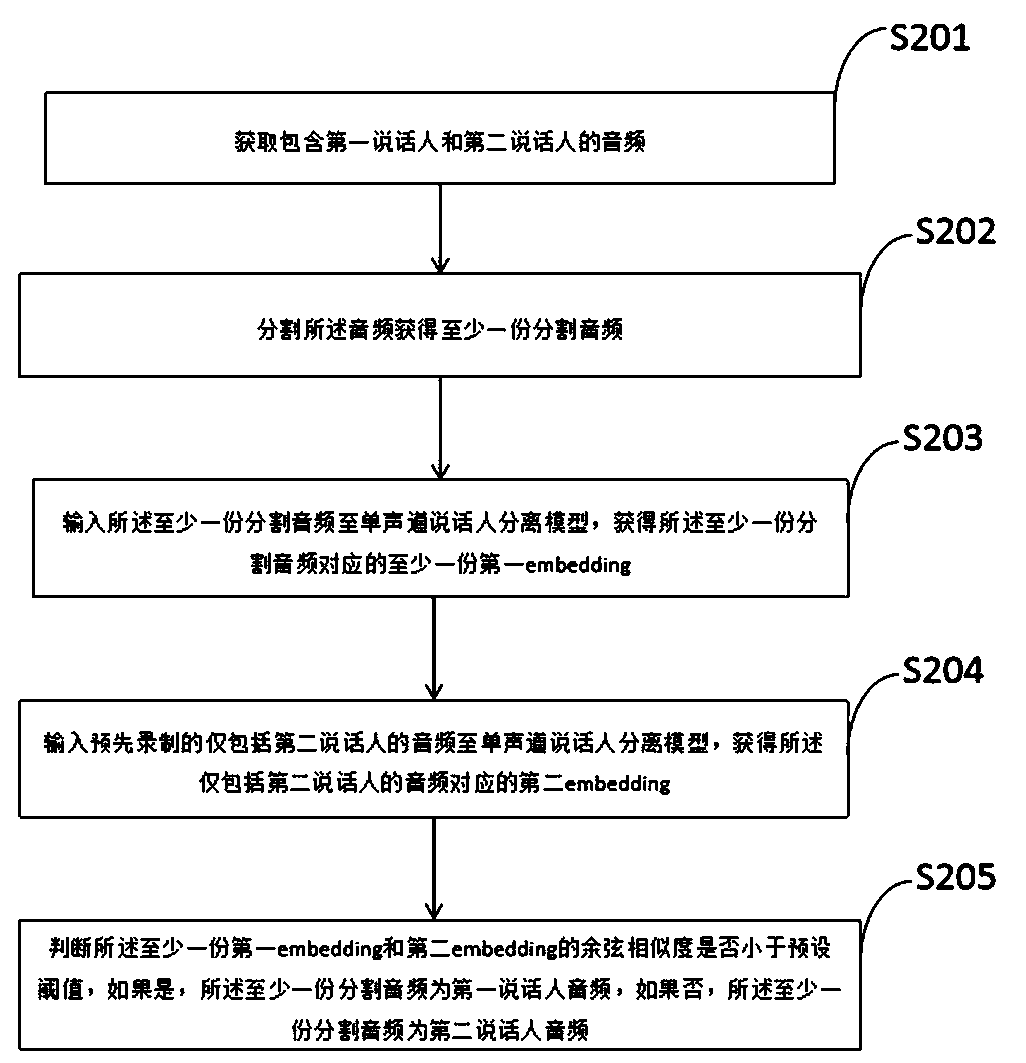
Examples
Embodiment Construction
[0035] The technical solutions of the present invention will be further described in detail below through specific embodiments in combination with the accompanying drawings. Obviously, the described embodiments are only some of the embodiments of the present application, not all of them. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
[0036] At present, part of the speaker separation still uses manual listening and manual separation, while another part of the speaker separation technology solution uses the unsupervised learning mode, which divides the recording into small audio segments, and then extracts the features of each audio segment. for clustering. However, in scenarios such as sales, return visits, and collections, there are often a large number of scene sounds, and the clustering algorithm is easily distu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com