Method for calculating similarity connection of mass time series data
A time series and calculation method technology, applied in the database field, can solve problems such as calculation efficiency in the actuarial stage after partitioning is not considered, and achieve the effect of balanced calculation and uniform data volume
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
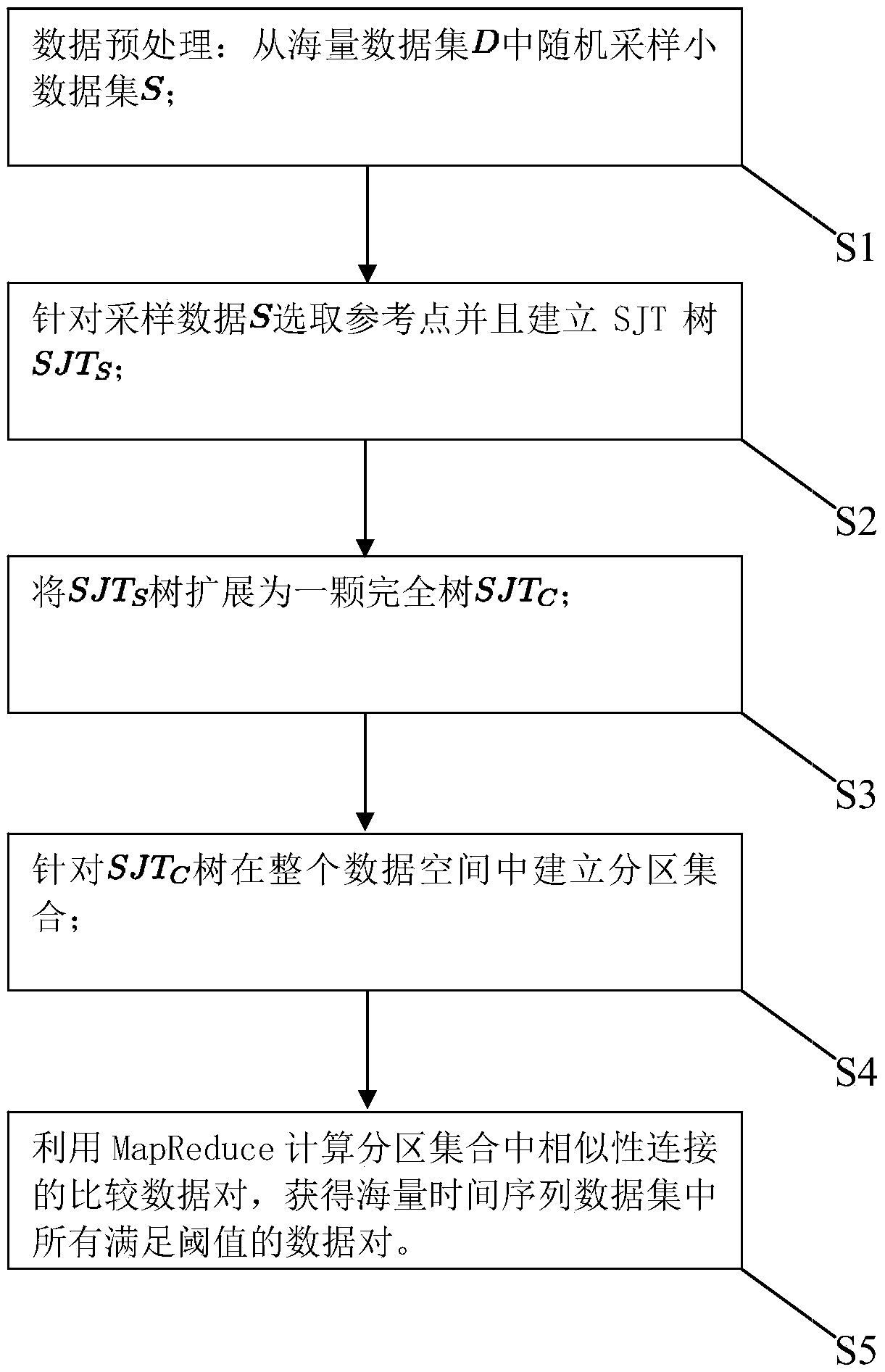
[0053] Attached below Figure 1-7 , a specific embodiment of the present invention will be described in detail, but it should be understood that the protection scope of the present invention is not limited by the specific embodiment.
[0054] The invention provides a massive time series data similarity connection calculation method, comprising the following steps:
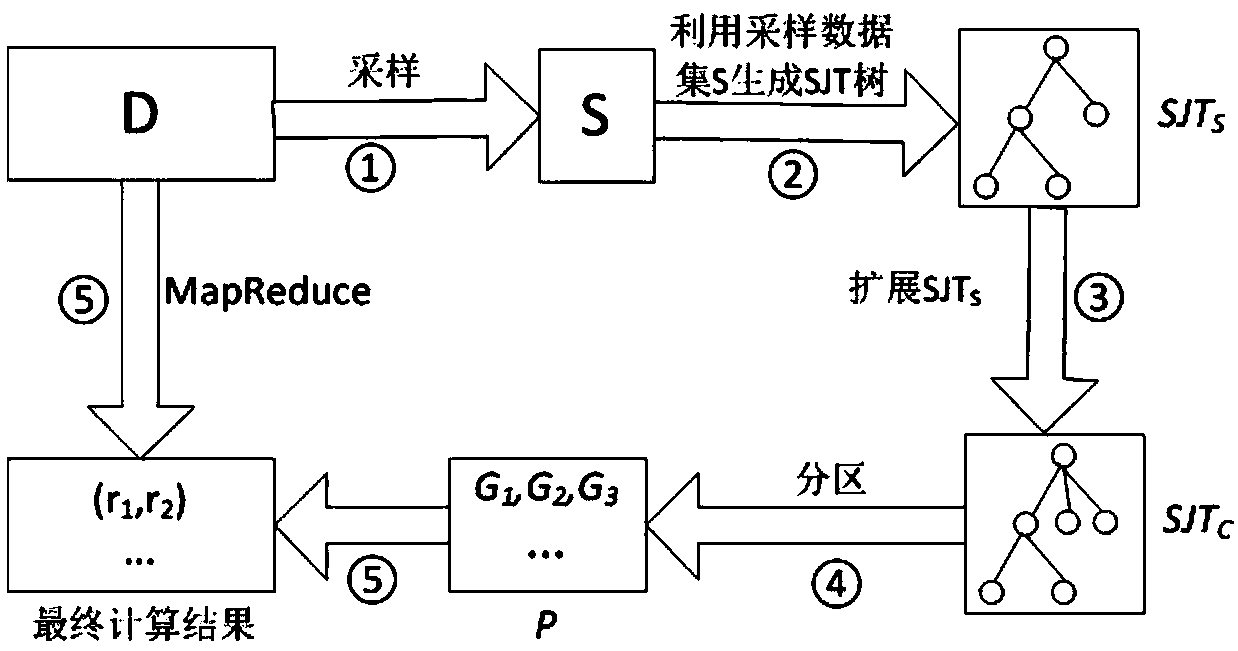
[0055] S1. Data preprocessing. Since it is too difficult to directly process massive data, first randomly sample a small data set S from the massive data set D (such as figure 2 step 1);
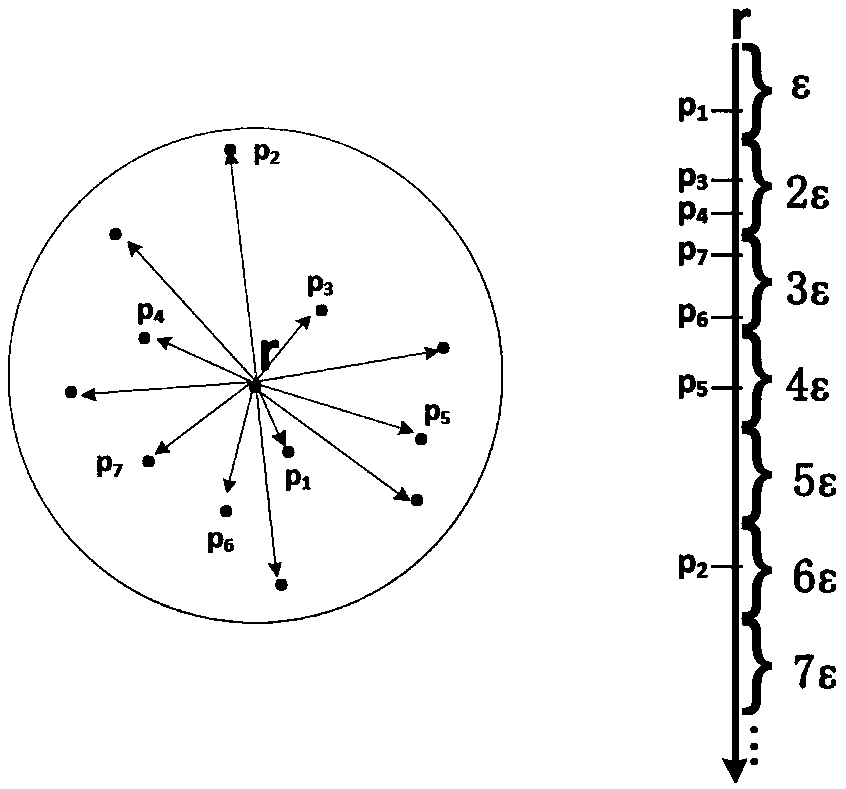
[0056] S2. Select a reference point for the sampling data S and build an SJT tree, denoted as SJT S ; In the process of calculating the similarity connection of massive time series data, the SJT tree can be used to prune unnecessary data comparisons, which can improve processing efficiency. Based on the SJT tree, the data pair comparison of the similarity connection is divided into two types, the first type is the internal da...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com