Two-stage self-adaptive scheduling method suitable for large-scale parallel data processing tasks
A technology of data processing and scheduling methods, applied in the direction of electrical digital data processing, program start/switch, program control design, etc., to achieve the effect of realizing system resources, high flexibility, and improving task processing efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
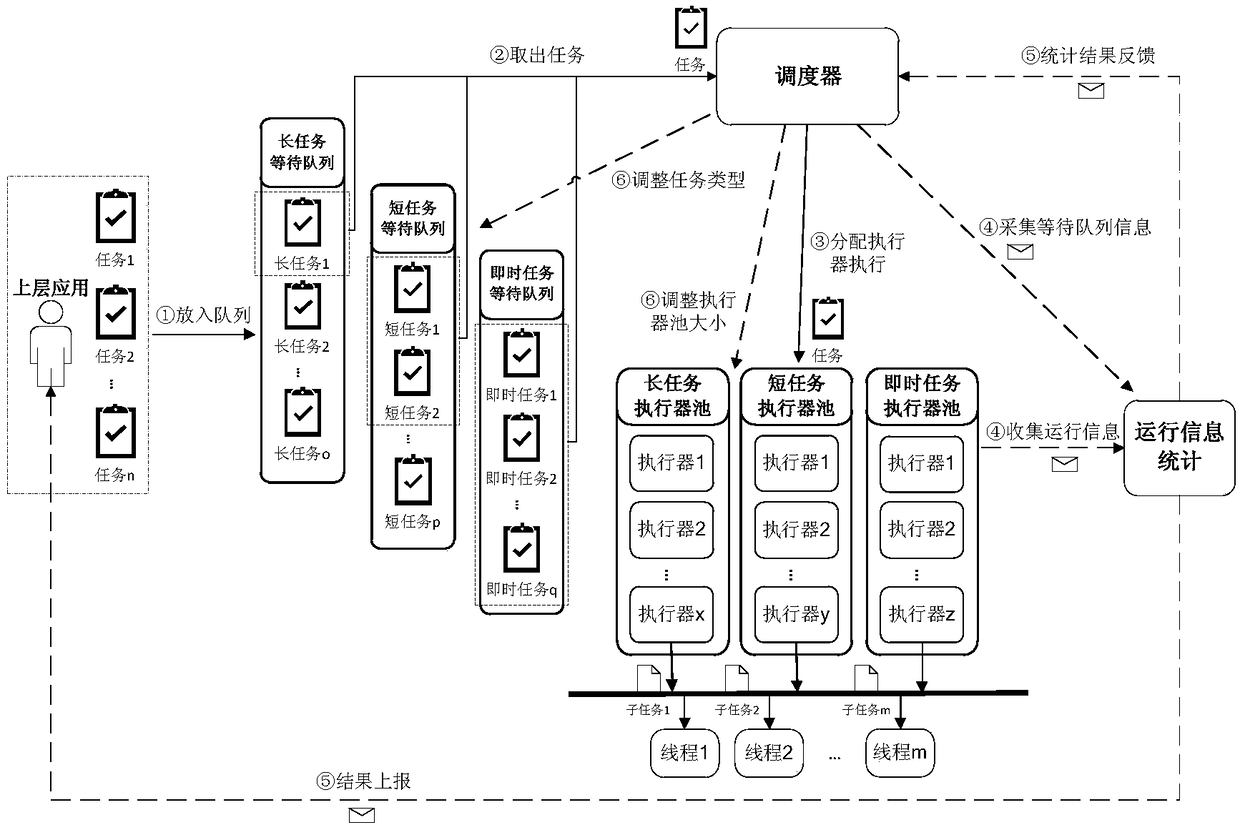
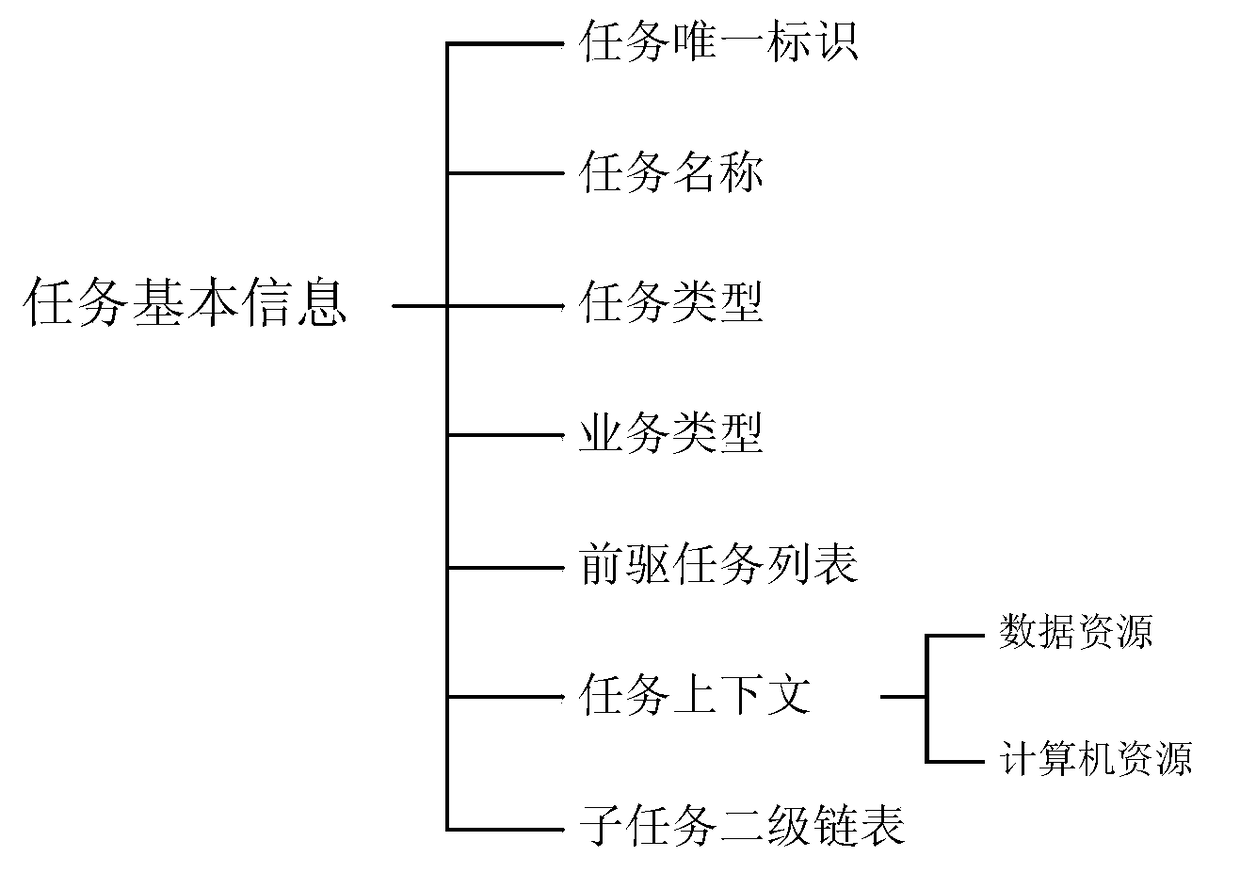
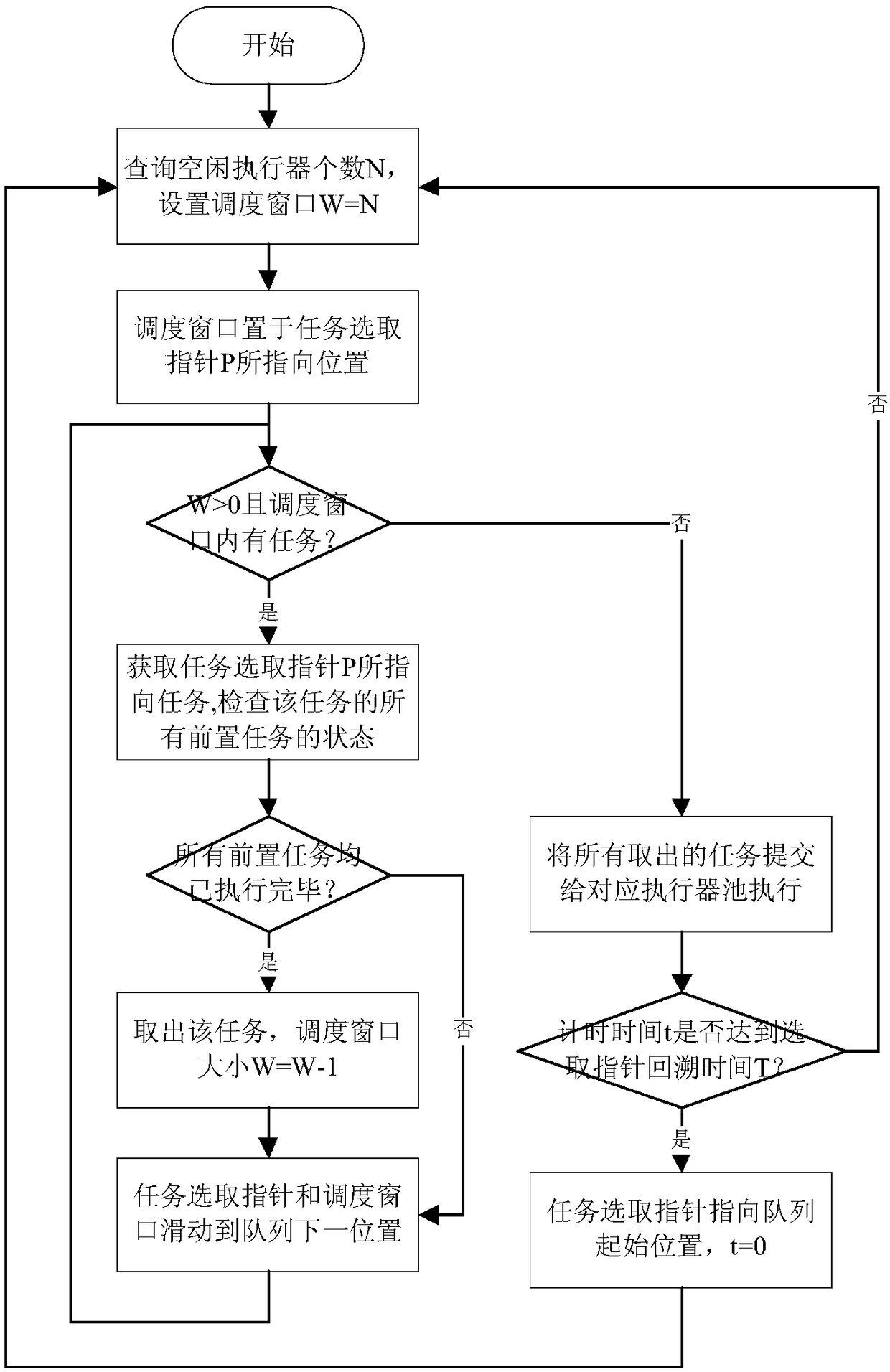
[0053] In order to execute large-scale data processing tasks in an orderly and efficient manner, the method of the present invention processes tasks from two levels, aiming at maximizing the amount of parallelism and reducing task waiting or execution time: the first level, the task level, each Each task declares its dependent predecessor tasks, and the scheduler builds a topology based on this to ensure that tasks are executed in the order of dependencies, and tasks without dependencies can be executed in parallel; the second level, the subtask level, divides tasks into a series of actions or functions The data and resources required by each subtask have been loaded by the first-level task layer. The purpose of dividing subtasks is to further improve the degree of parallelism, and assign subtasks without resource conflicts and execution order associations to multiple threads at the same time. implement.
[0054] Data processing tasks refer to tasks such as data collection, da...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com