


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Combination drug recognition and ranking method based on medical literature database
A technology of medical literature and sorting method, applied in computer technology in the field of medical clinic, can solve the problem of result error and so on
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
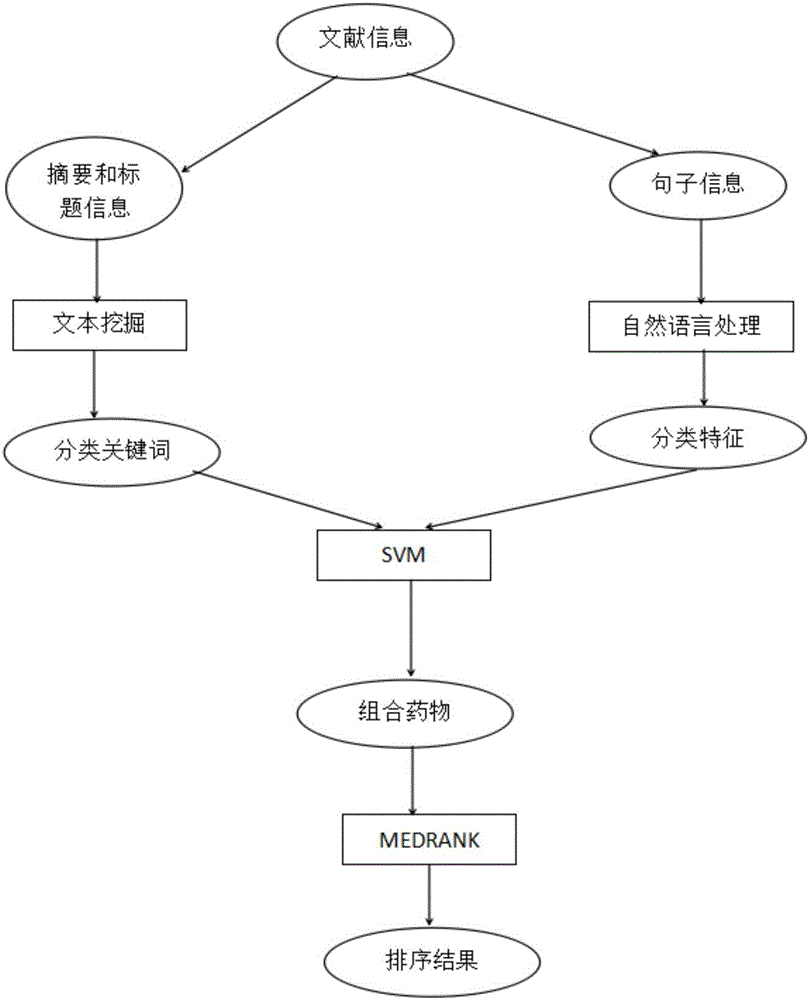
[0056] Such as figure 1 as shown, figure 1 It is a schematic diagram; a method for identifying and sorting combined drugs based on a medical literature database provided in this embodiment, first uses text mining to extract classification features from abstracts that meet the requirements, and secondly uses the support vector machine model in machine learning to perform Classify, and use genetic algorithm to optimize the parameters of the support vector machine model; since then, the literature containing multiple drugs and the combination relationship between drugs can be identified, and finally the medrank algorithm is used to sort these literatures, and the results for a certain disease are obtained. Recommendation results for combination drugs.
[0057] Among them, the extraction of classification features can be implemented simply by using the JAVA language, and the classification by using the support vector machine model can use a simple, easy-to-use, fast and effective...
Embodiment 2
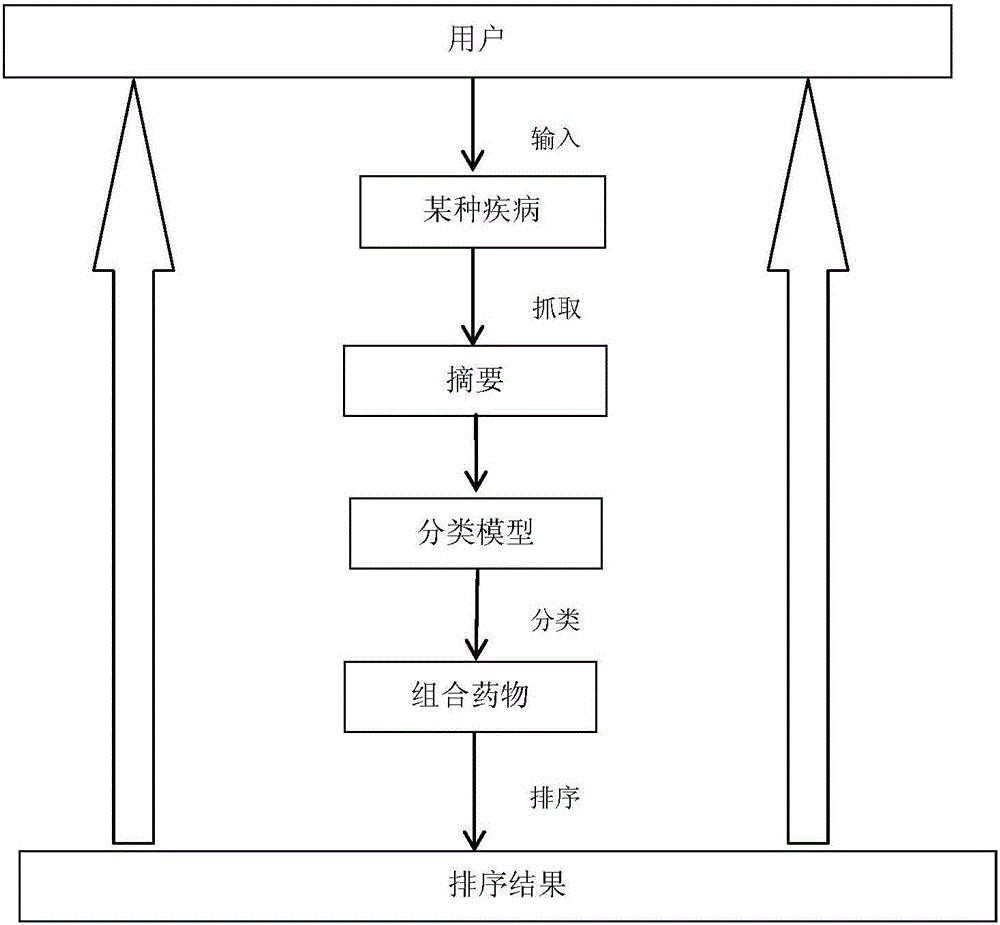
[0059] The method provided in this embodiment is as follows:
[0060] First, grab the article information containing the specified disease in the MEDLINE literature database, and use the drug entity to identify the literature information containing multiple drugs; use the abstract information and title information in the article as a data set, and then use part of these data sets as The training set and the test set were manually marked, and the documents marked as the combination relationship and the non-combination relationship of the drug were marked; then, the feature selection method CHI chi-square statistical method in text mining was used to extract the classification keywords, and TF / IDF was used to classify each A keyword is weighted as a feature, and the selected classification features include classification keywords, whether the drug appears in the same sentence, word features, part-of-speech features, logical features, and dependent syntactic features of this sente...
Embodiment 3
[0097] This implementation example uses data from the medline medical literature dataset from 1966 to 2015. Use the xml dataset provided by medline. The format of the dataset is as follows:
[0098] Each of the bibliographic information starts with start with Finish. The key fields included are described below:
[0099]
[0100] The disease studied in this example is hypertension.
[0101] 2. Specific steps:
[0102] Grab the document information containing the keywords "humans" and "hypertension" in the mesh word;
[0103] Grab the literature containing multiple drug entities in the abstract, and obtain 7911 abstracts as the original corpus;
[0104] Manually annotate some of the summaries. Mark as summaries with combined relationship and abstracts without combined relationship;
[0105] Use the text representation method and text feature selection method in text mining to extract classification keywords. Finally, 20 classification keywords are selected, and thei...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com