Extreme learning machine method for improving artificial bee colony optimization
An artificial bee colony optimization and extreme learning machine technology, applied in the field of artificial intelligence, can solve the problems of many parameters, poor effect, long use time, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

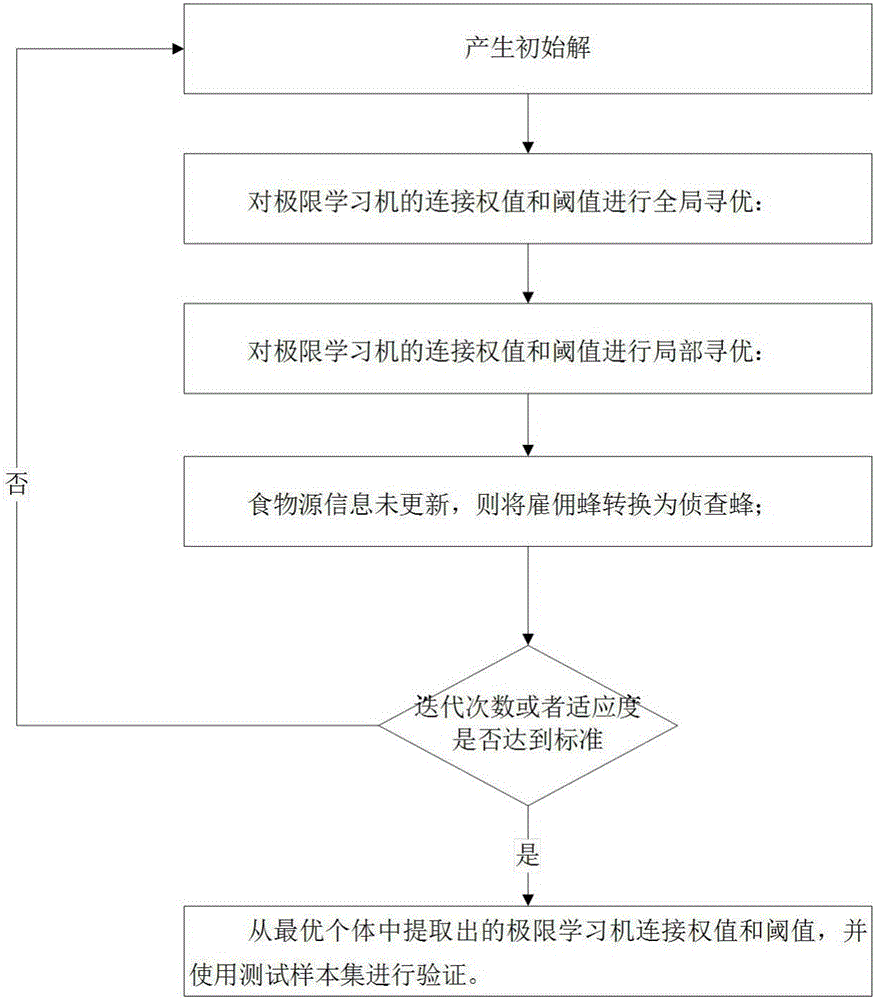
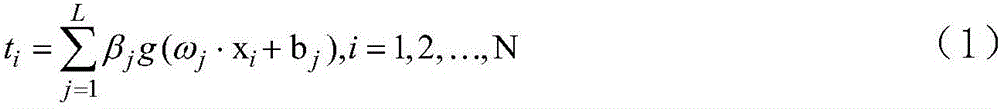

Examples
Embodiment 1
[0085] Embodiment 1: SinC function simulation experiment.
[0086] The "SinC" function expression is as follows:
[0087] y ( x ) = sin x / x , x ≠ 0 1 , x = 0
[0088] Data generation method: generate 5000 [-10,10] evenly distributed data x, and calculate 5000 data sets {x i ,f(x i )}, i=1,...,5000, and then generate 5000 [-0.2,0.2] uniformly distributed noise ε; let the training sample set be {x i ,...
Embodiment 2
[0118] Embodiment 2: Simulation experiment of regression data set.
[0119] The performance of the 4 algorithms was compared using 4 real regression datasets from the Machine Learning Repository at UC Irvine. The dataset names are: Auto MPG (MPG), Computer Hardware (CPU), Housing and Servo. The data in the data set in the experiment is randomly divided into a training sample set and a test sample set, 70% of which are used as a training sample set, and the remaining 30% are used as a test sample set. In order to reduce the impact of large differences in various variables, we normalize the data before the algorithm runs, that is, the input variables are normalized to [-1,1], and the output variables are normalized to [0,1]. In all experiments, the hidden layer nodes gradually increase from small to large, and the experimental results with the average optimal RMSE are recorded in Table 2-Table 5.
[0120] Table 2 Comparison of Auto MPG fitting results
[0121]
[0122] Tab...
Embodiment 3
[0131] Embodiment 3: Simulation experiment of classification data set.
[0132] The machine learning library from UC Irvine was used. The names of the 4 real classification datasets are: BloodTransfusion Service Center (Blood), Ecoli, Iris and Wine. Same as the classification data set, 70% of the experimental data is used as a training sample set, 30% is used as a test sample set, and the input variables of the data set are normalized to [-1,1]. In the experiment, the hidden layer nodes are gradually increased, and the experimental results with the optimal classification rate are recorded in Table 6-Table 9.
[0133] Table 6 Comparison of Blood classification results
[0134]
[0135]
[0136] Table 7 Comparison of Ecoli classification results
[0137]
[0138] Table 8 Comparison of Iris classification results
[0139]
[0140] Table 9 Comparison of Wine classification results
[0141]
[0142] The table shows that DECABC-ELM has achieved the highest classi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com