Webpage text extraction method based on maximum text density
A web page text extraction and text technology, applied in the field of information processing, can solve the problems of inapplicability, lack of generality, time-consuming and labor-intensive information pattern recognition knowledge, and achieve the effect of improving the accuracy rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

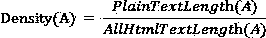

Examples
Embodiment Construction
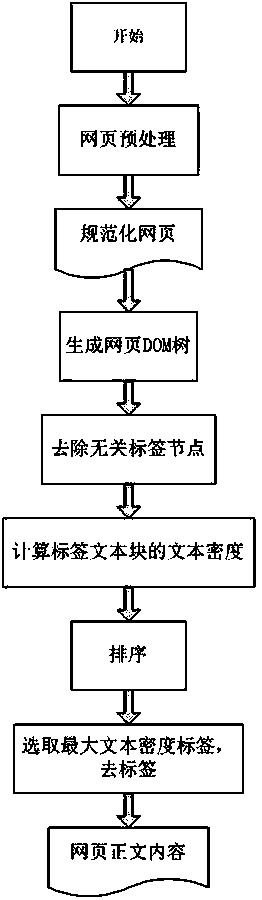
[0040] like figure 1 As shown, the specific steps of the web page text extraction method based on the maximum text density are as follows:
[0041] 1. Web page preprocessing
[0042] (1) Character encoding problem
[0043] Common encoding methods include GBK (including Simplified Chinese and Traditional Chinese), BG2312 (Simplified Chinese), BIG-5 (Traditional Chinese), UTF-8, UTF-16, and UNICODE. In the HTML document, the encoding method is defined as follows:
[0044]
[0045]
[0046]
[0047] The charset attribute defines how the web page is encoded. In order to prevent garbled characters on the webpage, in the preprocessing stage of the webpage, the default encoding of the acquired webpage file is converted to UTF-8 character encoding. If the relevant encoding information cannot be obtained from the webpage, try to convert it to UTF-8 character encoding coding.
[0048] (2) Web page standardization
[0049] Now the HTML code format on som...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com