Graphics processing unit (GPU) program optimization method based on compute unified device architecture (CUDA) parallel environment
A program optimization and program technology, applied in the field of high-performance computing, can solve the problems of unclear explanation of the use occasions and conditions of optimization technology, difficult to achieve practical and operational standards, insufficient to give full play to the computing power of GPU devices, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
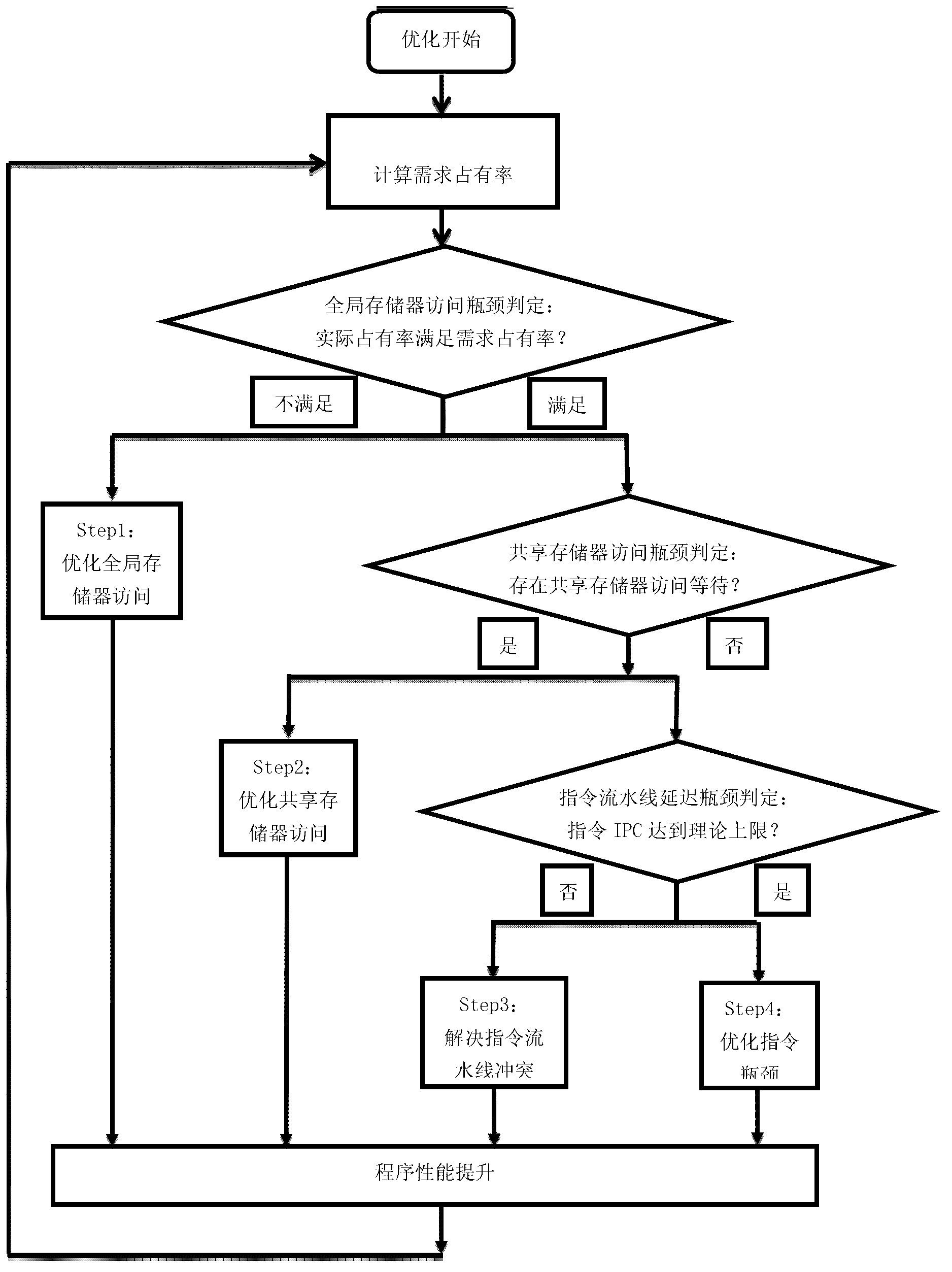
[0033] Principle of invention
[0034] The performance of a CUDA parallel program depends on many factors, each of which will cause a specific lower limit on the execution time of the program, and the final execution time of the program depends on the lowest one of the lower limits. The performance bottlenecks or performance optimization points of CUDA programs are mostly mentioned in the published literature. The present invention still adopts the optimization mode of performance bottlenecks. In order to achieve the purpose of optimizing program performance, it is first necessary to provide definitions for a wide range of program performance bottlenecks (the present invention may involve the same or similar performance bottlenecks as those in the existing literature, but the definition is the same as the existing ones) The definitions given in the literature are not exactly the same).
[0035] The processor of a GPU device will only be in two states during operation: executi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com