Method and device for extracting webpage frame information
A technology of page information and extraction method, applied in special data processing applications, instruments, electronic digital data processing, etc., can solve the problems of inability to meet the requirements of accuracy rate and information recall rate, inability to be applied on a large scale, and high labor cost.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
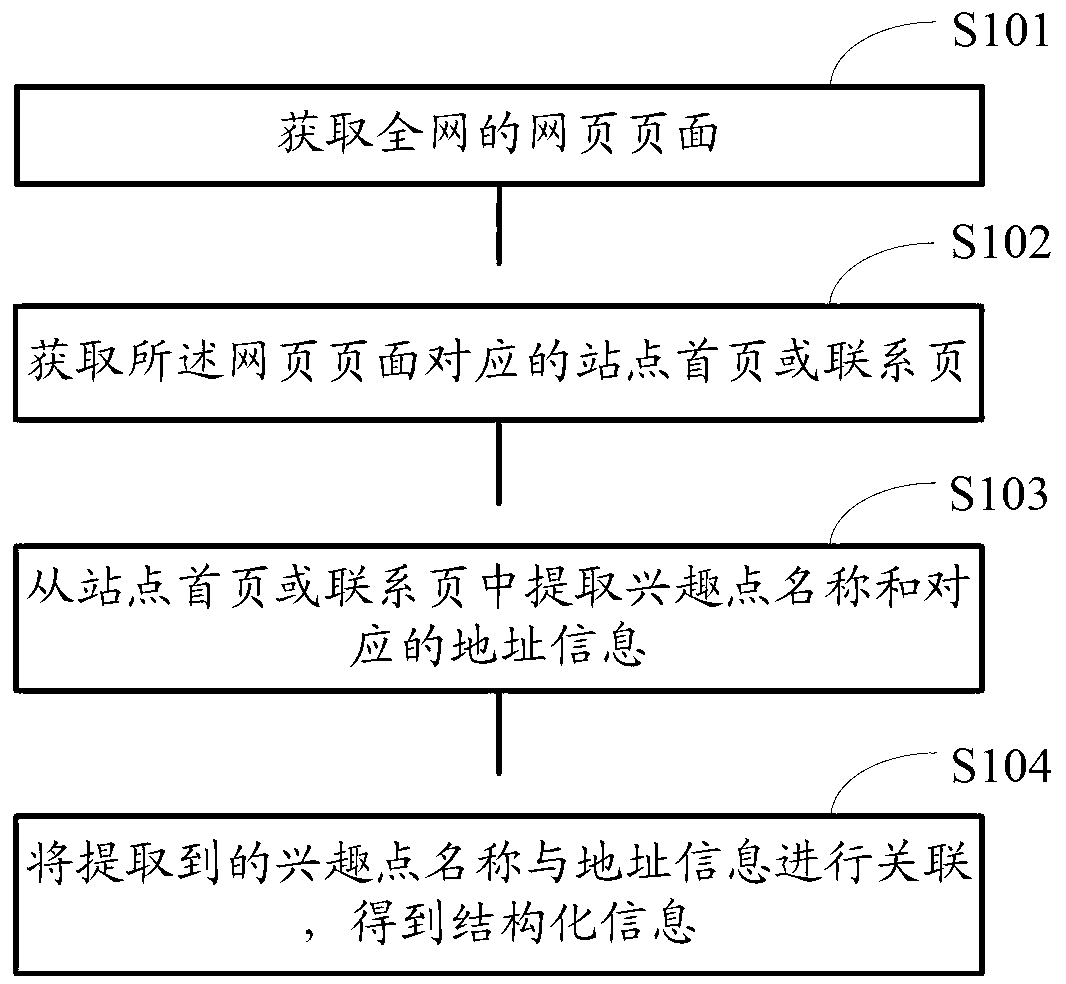
[0119] figure 1 It is a flow chart of the page information extraction method provided in this embodiment, such as figure 1 As shown, the method includes:
[0120] Step S101 , obtaining webpages of the whole network.
[0121] A web crawler is used to crawl webpages on the Internet, at least including URLs and source codes of the webpages. For example, the url address is "http: / / www.hdhospital.com / OverView.aspx", which is a page in the website of Beijing Haidian Hospital. Use a web crawler to grab the web page, record the corresponding url address, and obtain the web page The web page source code (such as HTML code) corresponding to the page.
[0122] Step S102, obtaining the home page or contact page of the website corresponding to the web page.
[0123] The method of obtaining the home page of the site can be one or any combination of the methods A~C listed below:
[0124]Method A: Take out the domain name address from the website address of the web page, perform jump pro...
Embodiment 2
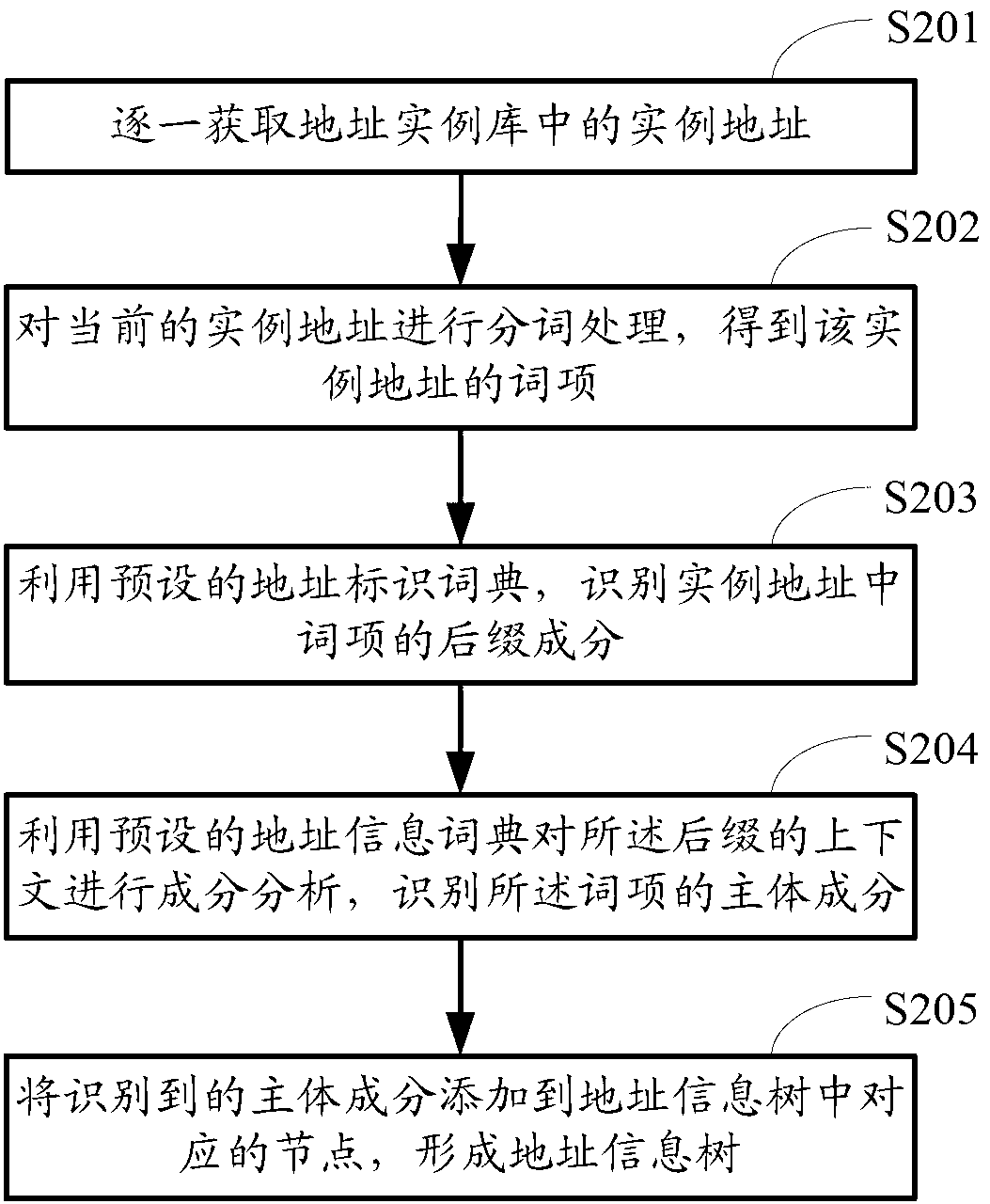
[0155] image 3 It is a flow chart of the page information extraction method provided in this embodiment, such as image 3 shown, including:
[0156] Step S301, acquiring webpages of the whole network.
[0157] This step is the same as step S101 in the first embodiment, and will not be repeated here.
[0158] Step S302, analyzing the web pages one by one.
[0159] Analyze the webpages of the whole network obtained in step S301 one by one, and enter step S307 after executing step S303, or enter step S307 after executing steps S304 to S306.
[0160] Step S303, obtaining the homepage or contact page of the website corresponding to the web page.
[0161] The process of this step is the same as that of step S102 in the first embodiment, and will not be repeated here. And add the obtained site home page or contact page to the home page or contact page library.
[0162] Step S304 , parsing the web page into a document object model tree, performing visual block processing on the...
Embodiment 3
[0217] Figure 6 is a schematic diagram of the page information extraction device provided in this embodiment. Such as Figure 6 As shown, the device includes:
[0218] The web page acquisition module 601 is configured to acquire web pages of the entire network.
[0219] A web crawler is used to crawl webpages on the Internet, at least including URLs and source codes of the webpages. For example, the url address is "http: / / www.hdhospital.com / OverView.aspx", which is a page in the website of Beijing Haidian Hospital. Use a web crawler to grab the web page, record the corresponding url address, and obtain the web page The web page source code (such as HTML code) corresponding to the page.
[0220] The site structure analysis module 602 is used to obtain the site home page or contact page corresponding to the web page, including:
[0221] The website home page obtaining sub-module 6021 is used to obtain the website home page corresponding to the web page.
[0222] The conta...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com