An adaptive aggregation method, system and electronic device for massive structured data
A structured data and self-adaptive aggregation technology, applied in special data processing applications, electronic digital data processing, digital data information retrieval, etc., can solve problems such as low reliability of aggregation results, unstable aggregation accuracy, and large amount of processed data , to achieve the effect of improving aggregation reliability, ensuring aggregation accuracy, and ensuring reasonable reduction
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0033] Please see attached figure 1 The present invention provides an adaptive aggregation method for massive structured data, wherein the method is applied to an adaptive aggregation system for massive structured data, and the method specifically includes the following steps:
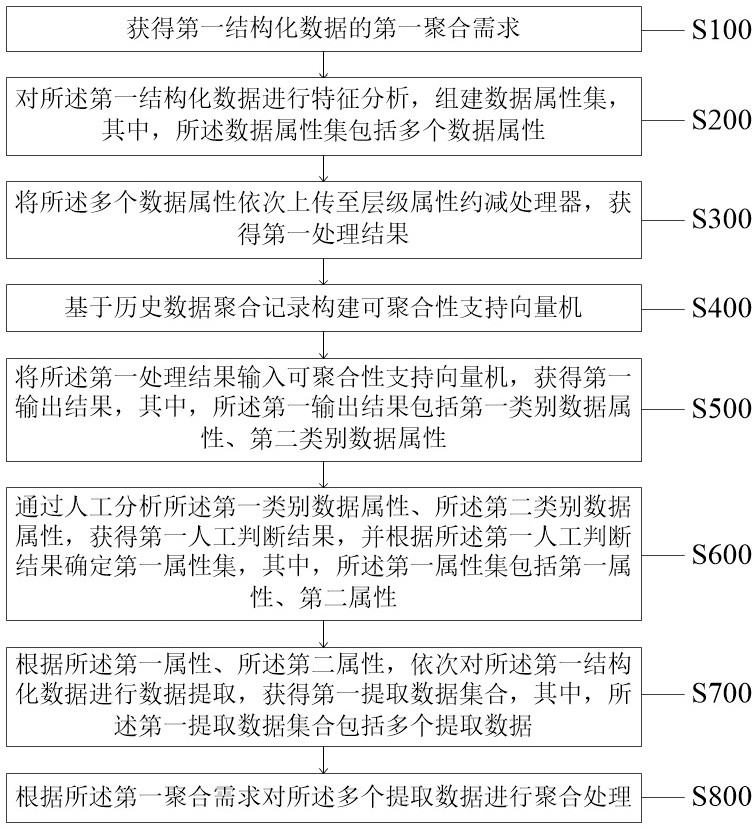
[0034] Step S100: obtaining a first aggregation requirement of the first structured data;
[0035] Specifically, the method for adaptive aggregation of massive structured data is applied to the adaptive aggregation system for massive structured data, which can use hierarchical attributes to reduce the amount of structured data processed by the processor before data aggregation. Make reasonable and effective reductions. Structured data refers to data that can be logically expressed and implemented through a two-dimensional table structure. The first row of the table in the two-dimensional table structure is generally the data attribute name, and all data elements in the table and the attribute name of ...
Embodiment 2
[0098] Based on the same inventive concept as an adaptive aggregation method for massive structured data in the foregoing embodiment, the present invention also provides an adaptive aggregation system for massive structured data, please refer to the appendix Figure 5 , the system includes:
[0099] a first obtaining unit 11, the first obtaining unit 11 is used to obtain the first aggregation requirement of the first structured data;
[0100] a first building unit 12, the first building unit 12 is configured to perform feature analysis on the first structured data, and build a data attribute set, wherein the data attribute set includes a plurality of data attributes;
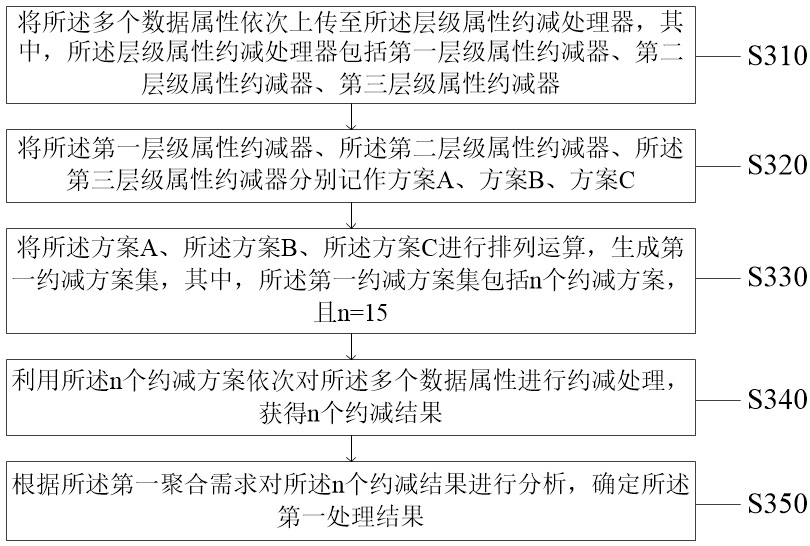
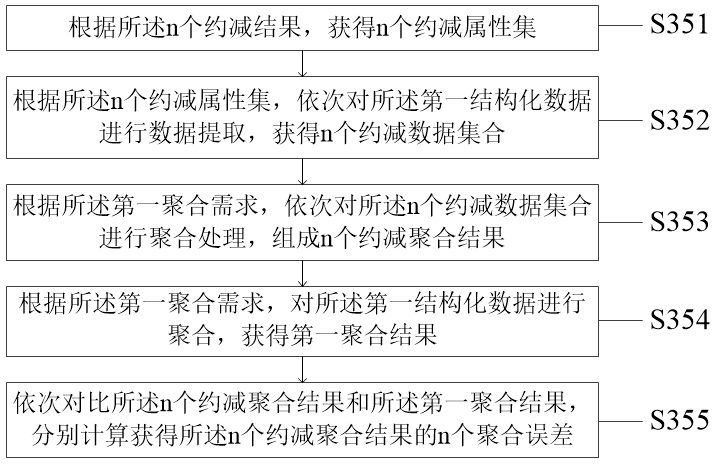
[0101] The second obtaining unit 13, the second obtaining unit 13 is configured to sequentially upload the plurality of data attributes to the hierarchical attribute reduction processor to obtain the first processing result;
[0102] a first construction unit 14, the first construction unit 14 is configured to ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com