


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
A multi-modal speech separation method and system
A speech separation and multi-modal technology, applied in speech analysis, neural learning methods, character and pattern recognition, etc., can solve the problems of insufficient data effect, inability to flexibly change the number of inputs, etc., and achieve the effect of improving performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
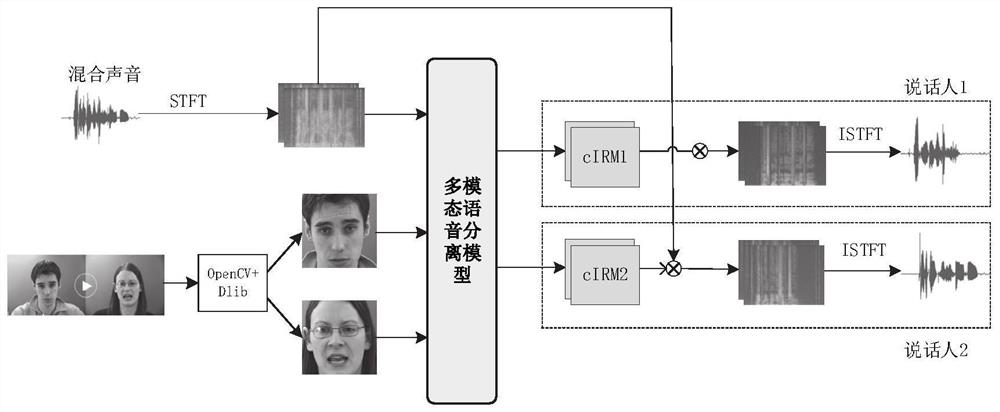
[0059] see attached figure 1 As shown, this embodiment discloses a multimodal speech separation method, including:
[0060] Receive the mixed voice of the object to be recognized and the facial visual information of the object to be recognized, and obtain the number of speakers through face detection;
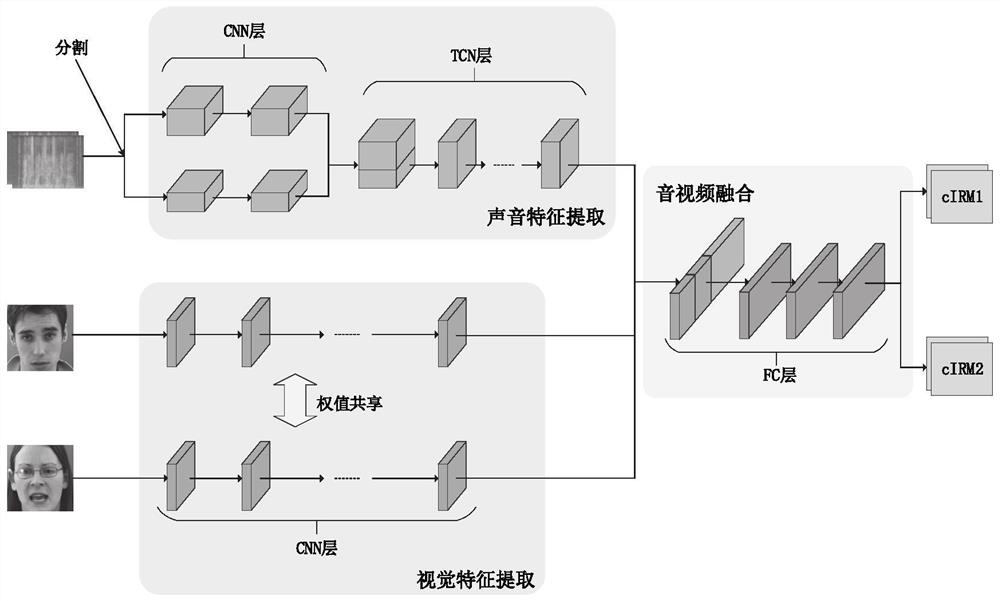
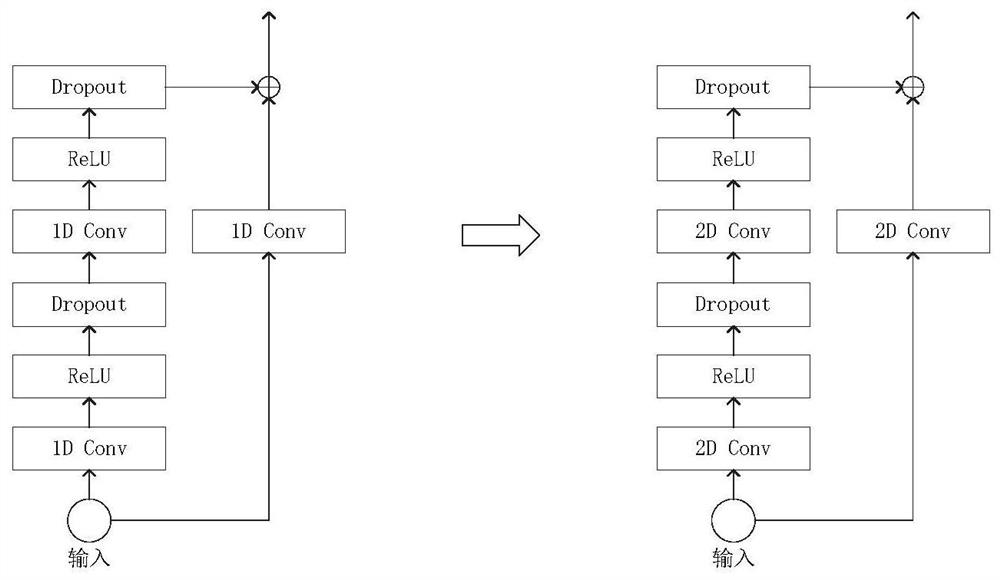
[0061] The above information is processed to obtain a polyphonic spectrogram and a face image and transmitted to a multimodal speech separation model, and the structure of the model is dynamically adjusted by the number of speakers, wherein the multimodal speech separation model is in the training process, Use complex domain ideal ratio masking cIRM as training target, cIRM is defined in complex domain as the ratio between clean voice spectrogram and mixed voice spectrogram, consisting of real and imaginary parts and including the amplitude and phase of the voice information;
[0062] The multimodal speech separation model outputs cIRM corresponding to the number of objects t...
Embodiment 2
[0077] The purpose of this embodiment is to provide a computing device, including a memory, a processor, and a computer program stored in the memory and operable on the processor, and the processor implements the steps of the above method when executing the program.
Embodiment 3
[0079] The purpose of this embodiment is to provide a computer-readable storage medium.
[0080] A computer-readable storage medium, on which a computer program is stored, and when the program is executed by a processor, the steps of the above-mentioned method are executed.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com