A Model Distillation Method Combined with Dynamic Vocabulary Augmentation
A technology of vocabulary enhancement and distillation, which is applied in computing models, machine learning, instruments, etc., can solve the problems of model inference relying on high-configuration equipment, model accuracy decline, and model size being too large, so as to improve semantic understanding and inference The effect of fast speed and low resource consumption
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0019] The present invention will be further described below in conjunction with the accompanying drawings.
[0020] In order to make the technical solution given in this embodiment clear, the technical terms mentioned in this embodiment are explained below:
[0021] Encode: Indicates encoding.
[0022] Token: Indicates a token.
[0023] CRF: stands for Conditional Random Field.
[0024] GPU: Indicates the graphics card.
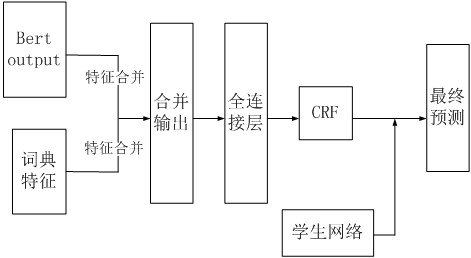
[0025] This embodiment provides a model distillation method combined with dynamic vocabulary enhancement. This method adopts model distillation and adds dictionary information in the fine-tuning process to reduce the size of the student model and improve the accuracy of the student model. The overall workflow is as follows figure 1 As shown, the specific steps are as follows:
[0026] First of all, fine-tuning the ALbert language model is different from the conventional fine-tuning logic. In the process of fine-tuning the ALbert language model, the fine-...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com