Scholar name disambiguation method and device, storage medium and terminal
A technology of personal names and scholars, applied in unstructured text data retrieval, instruments, calculations, etc., can solve problems such as high algorithm implementation complexity, low evaluation scores, and inability to run efficiently
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
Embodiment 1
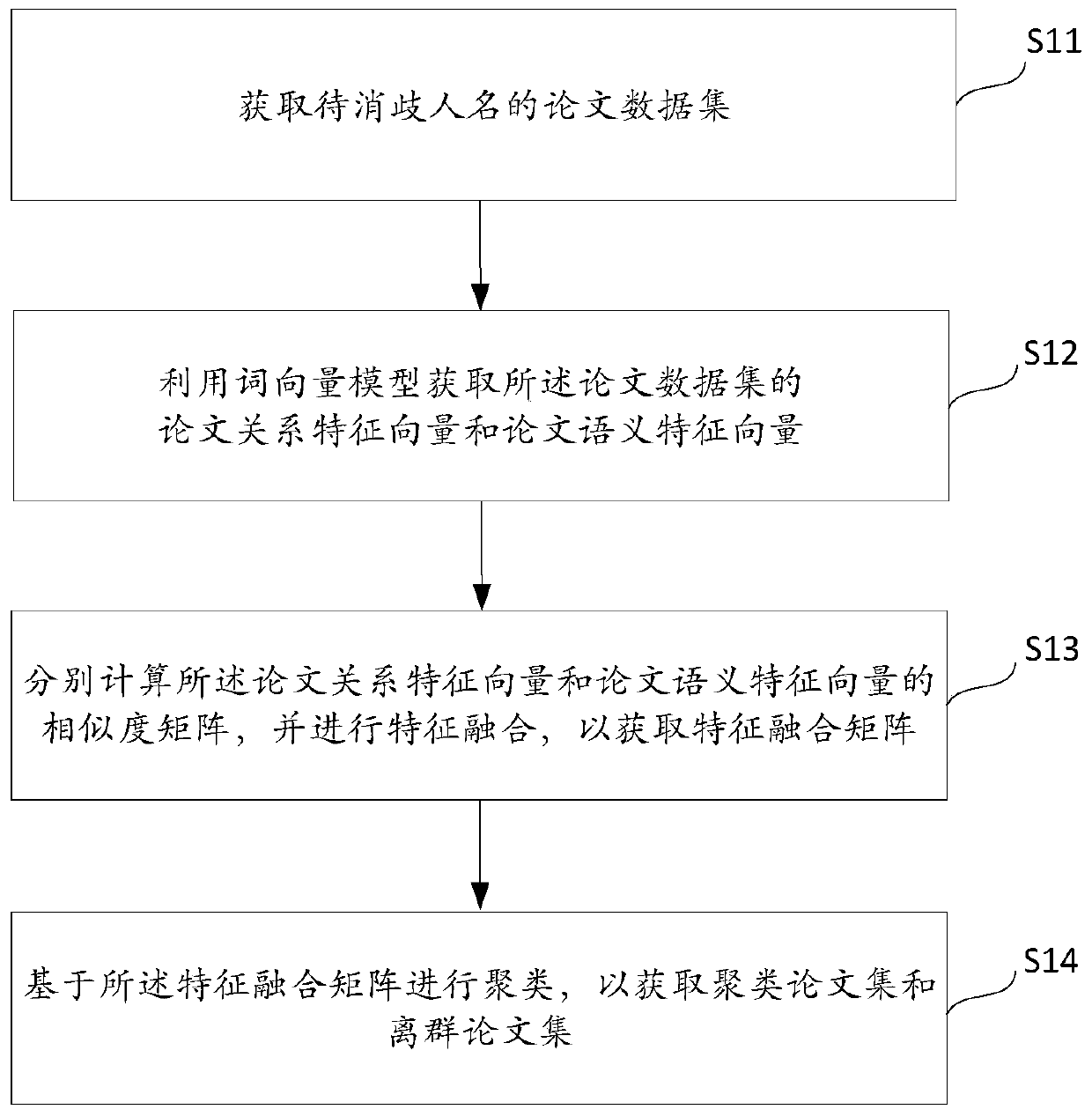
[0027] figure 1 Shown is a schematic flow chart of a disambiguation method for a scholar's name according to an embodiment of the present invention, including steps:
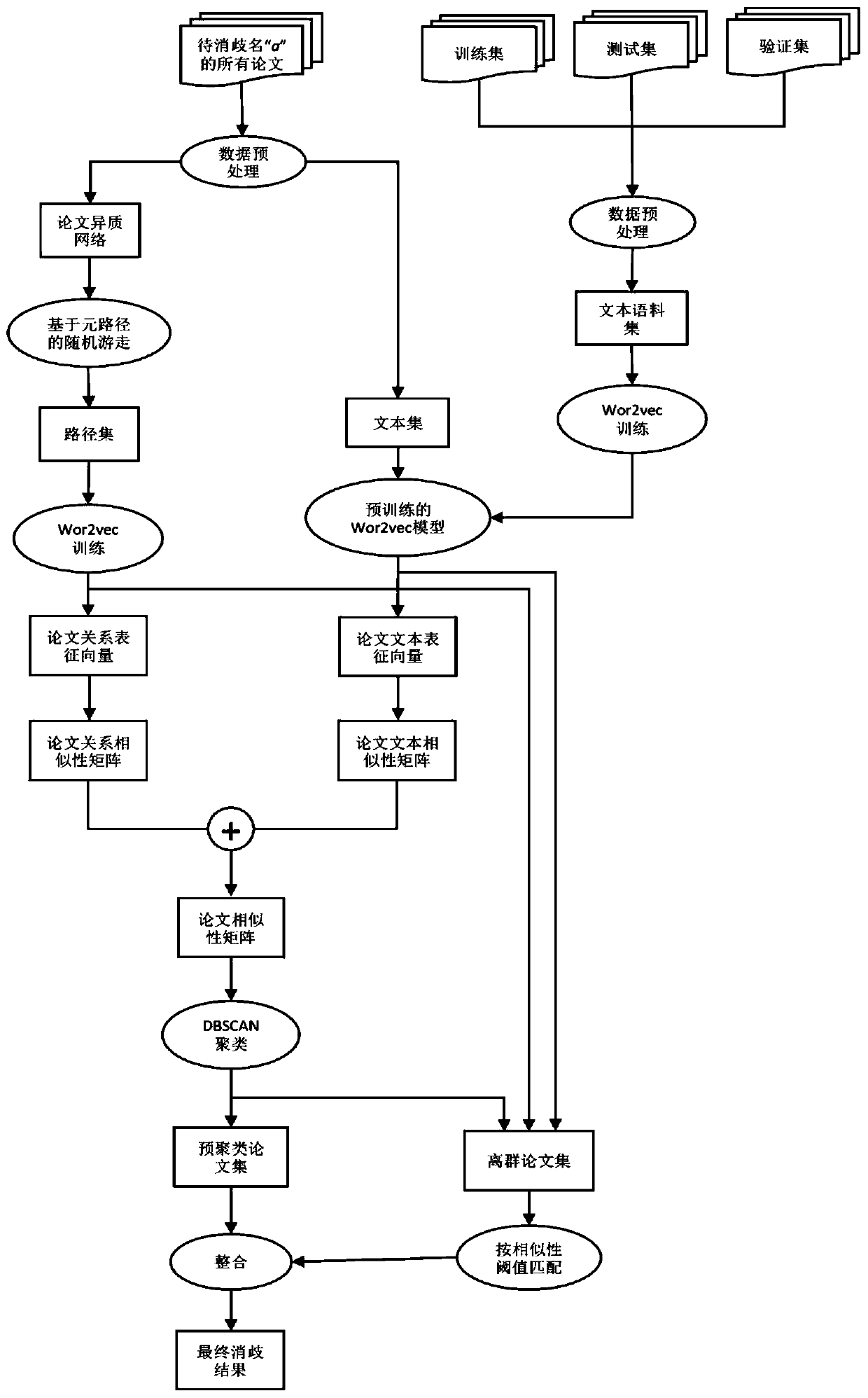
[0028] Step S11. Acquire the paper data set of the name of the person to be disambiguated. Optionally, use the method of group statistics to obtain the paper data set, and organize the papers corresponding to each name to be disambiguated into a secondary dictionary data format; use hive local mode to obtain the relationship between the paper and the name to be disambiguated Relational data; use the generator to read the paper data in blocks, convert each paper into a dictionary format, and divide some fields into lists and store them in the database. Preferably, this embodiment selects a lightweight memory-mapped database (Lightning Memory-Mapped Database, LMDB). The storage structure of the LMDB database is stored in a key-value manner, and its data structure is a byte array, which has the following advantag...
Embodiment 2
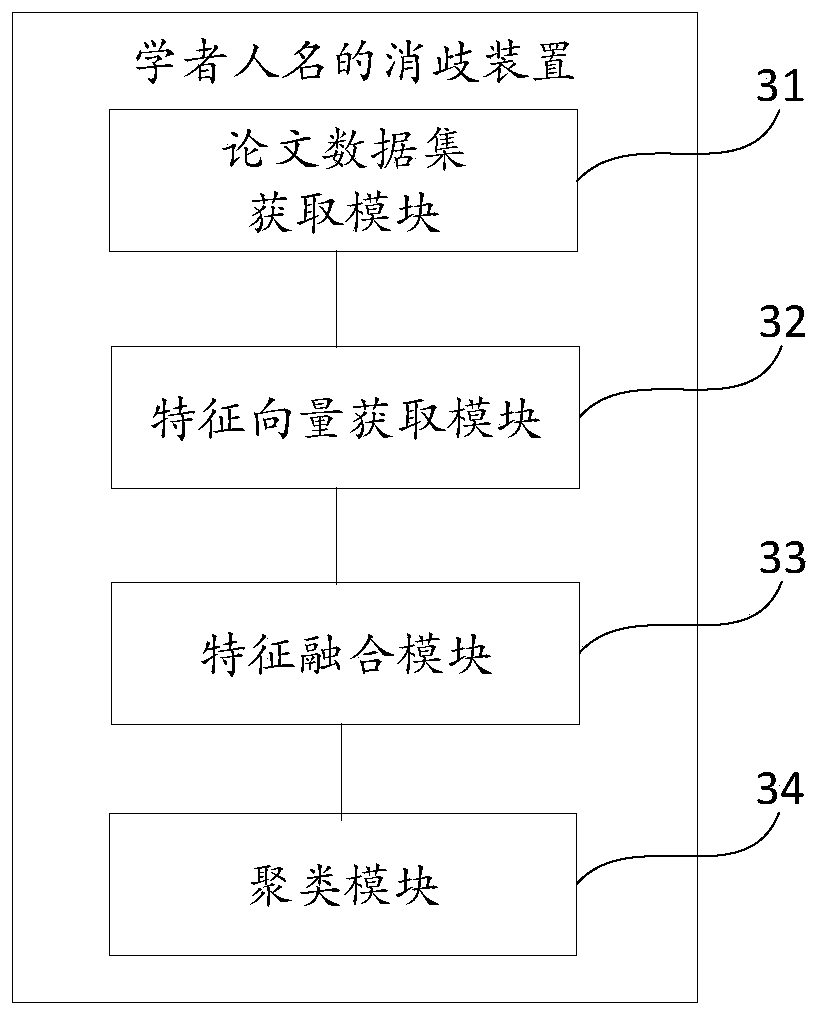
[0059] This embodiment provides a disambiguation device for scholars' names, such as image 3 Shown, comprise: paper data set acquisition module 31, obtain the paper data set of name to be disambiguated; Feature vector acquisition module 32, utilize word vector model to obtain the paper relation feature vector and paper semantic feature vector of described paper data set; Feature The fusion module 33 calculates the similarity matrix of the paper relation feature vector and the paper semantic feature vector respectively, and performs feature fusion to obtain a feature fusion matrix; the clustering module 34 performs clustering based on the feature fusion matrix to obtain Clustering papers and outlier papers.
[0060] It should be noted that the modules provided in this embodiment are similar to the methods and implementations provided above, so details are not repeated here. In addition, it should be noted that it should be understood that the division of each module of the ab...
Embodiment 3
[0063] This embodiment provides a computer-readable storage medium, on which a computer program is stored, and when the computer program is executed by a processor, the method for disambiguating the names of scholars is implemented.
[0064] Those of ordinary skill in the art can understand that all or part of the steps for implementing the above method embodiments can be completed by hardware related to computer programs. The aforementioned computer program can be stored in a computer-readable storage medium. When the program is executed, it executes the steps including the above-mentioned method embodiments; and the aforementioned storage medium includes: ROM, RAM, magnetic disk or optical disk and other various media that can store program codes.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com