


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Video character recognition method based on multi-modal feature fusion deep network
A feature fusion and deep network technology, applied in the field of video person recognition, can solve the problems of low accuracy of video person recognition and insufficient coverage of person recognition
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


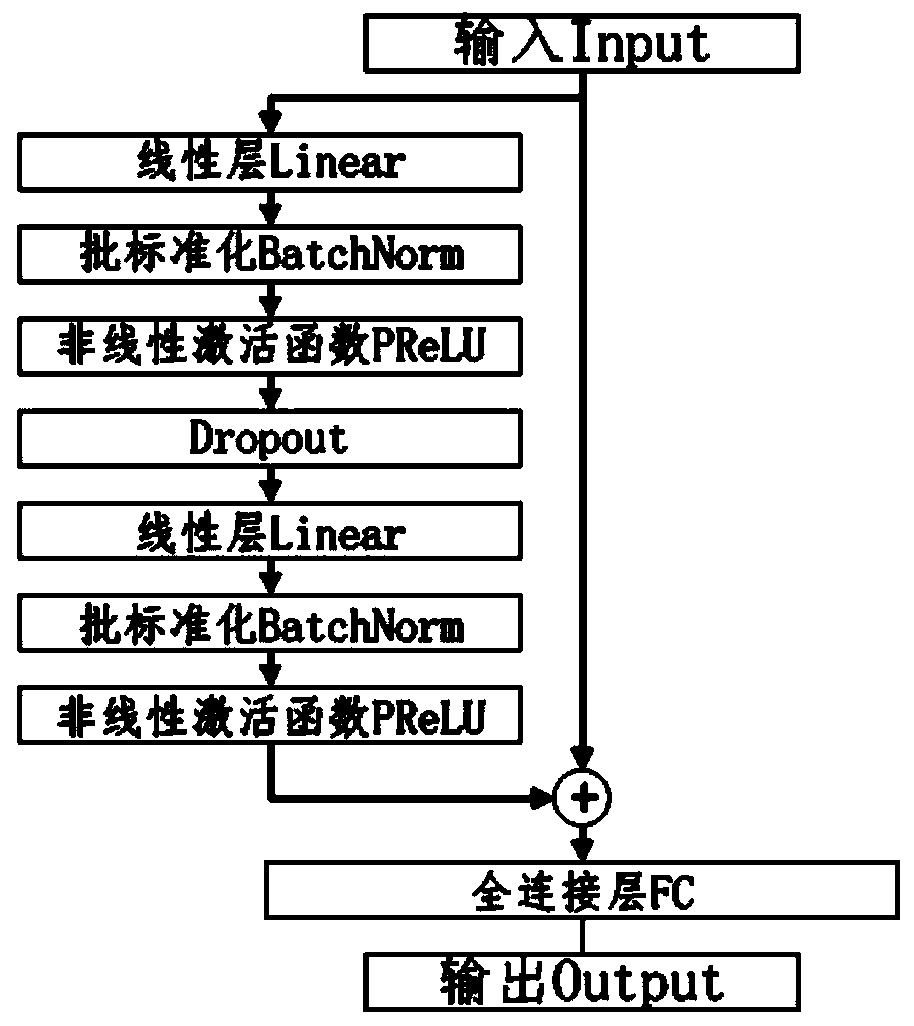

Examples
Embodiment Construction
[0023] In order to demonstrate the purpose, features and advantages of the present invention in detail, the present invention will be further described in detail below in conjunction with the accompanying drawings and specific implementation examples.
[0024] There are the following difficulties in video person recognition:
[0025] 1) The amount of video data is huge: the number of original videos is large, and the duration and resolution are uneven. The public video data set contains 10034 celebrities in complex scenes, 200 hours, 200,000 film and television dramas and short videos. The amount of data is very large. These challenges require the computing power of the environment where the model is run, and the complexity of the model will be limited.
[0026] 2) How to represent the characters in the video clips: the target of pattern recognition of single information is relatively easy to represent, while the same video in multi-modal data may contain multiple characters....
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com