Method for identifying disease content in medical record text
A text and content technology, applied in the field of electronic document processing, can solve problems such as structural redundancy and inability to meet the individual characteristics of different diseases, and achieve the effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
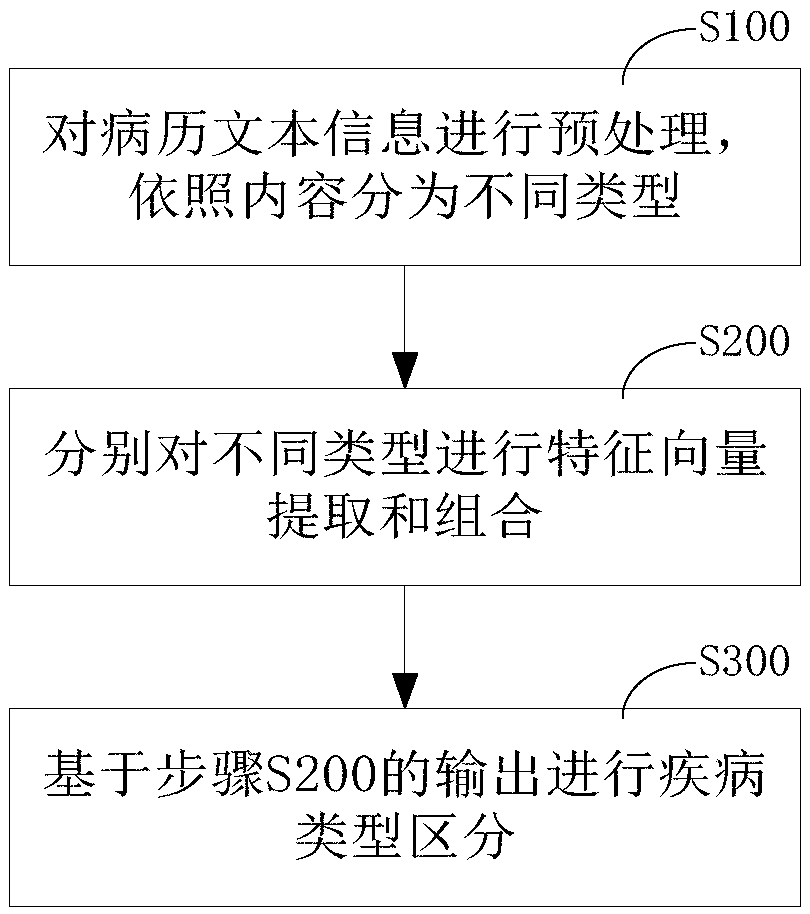
[0038] see below Figure 1 ~ Figure 3 The method for identifying disease content in medical record texts described in the present invention is described in detail.
[0039] Such as figure 1 As shown, the method includes the following steps:
[0040] S100: Preprocessing the medical record text information and splitting it into different types.
[0041] Since the medical records contain a variety of textual information, such as patient names, hospital names, etc., the above textual information is regarded as invalid information in this embodiment. Therefore, in this step, the above-mentioned invalid information needs to be cleaned to reduce the amount of subsequent word processing.
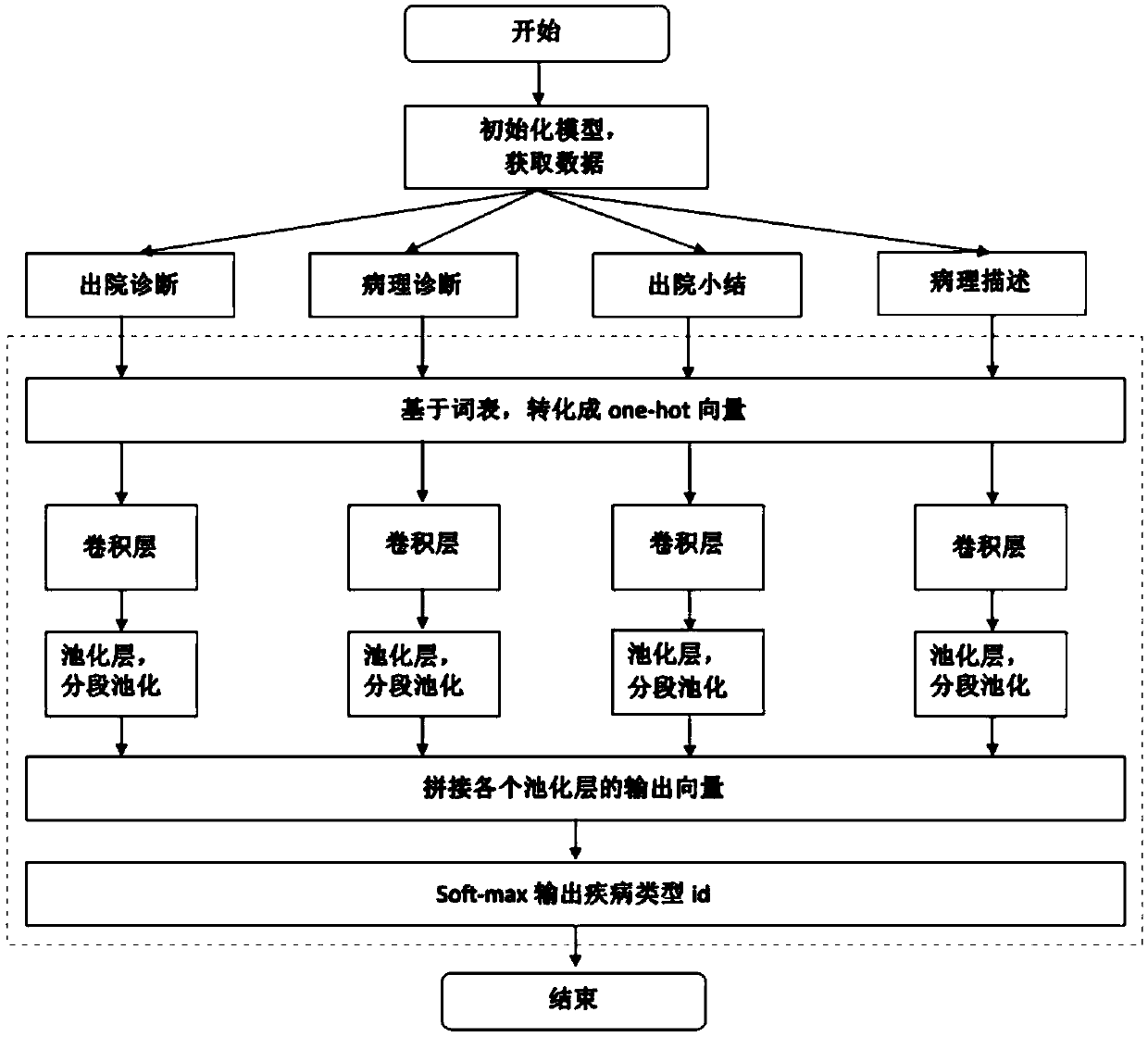
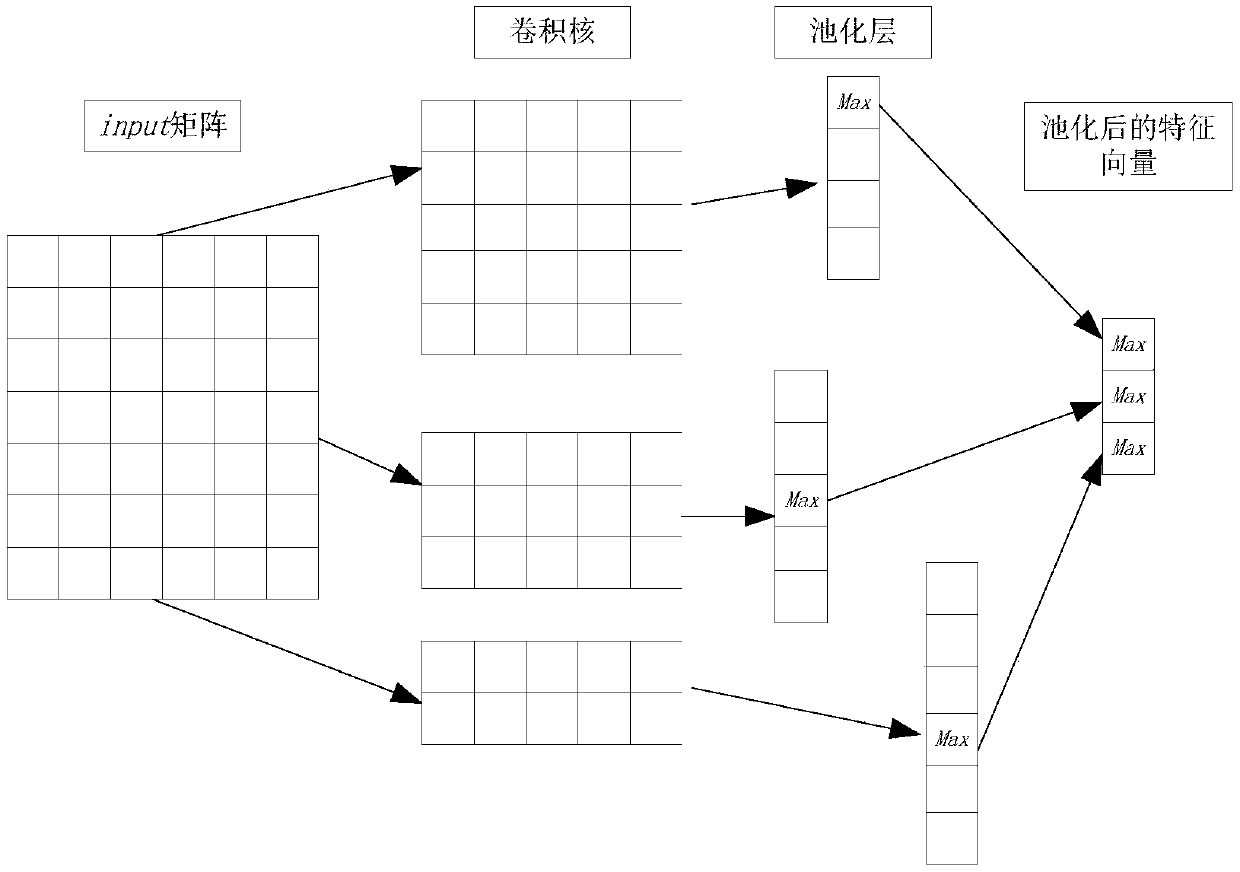
[0042] Second, combine figure 2 As shown, the preprocessing also includes dividing the remaining information of the medical records into four categories according to the four items of "discharge diagnosis", "pathological diagnosis", "discharge summary" and "pathological description". In the ac...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com