Spark-based Cassandra data import method and device, equipment and medium
A technology of data import and data, applied in the field of data processing, to achieve uniform data, reduce the number of small files, and prevent imbalance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0050] Embodiment 1 provides a Spark-based Cassandra data import method, which aims to prevent data imbalance and data skew by evenly dividing the data to be imported into each partition, and reduce the occurrence probability of memory overflow.
[0051] Spark is a unified analysis engine for large-scale data processing. Its Spark provides a comprehensive and unified framework for managing various data sets and data sources (batch data or real-time data) with different properties (text data, graph data, etc.). streaming data) big data processing needs.
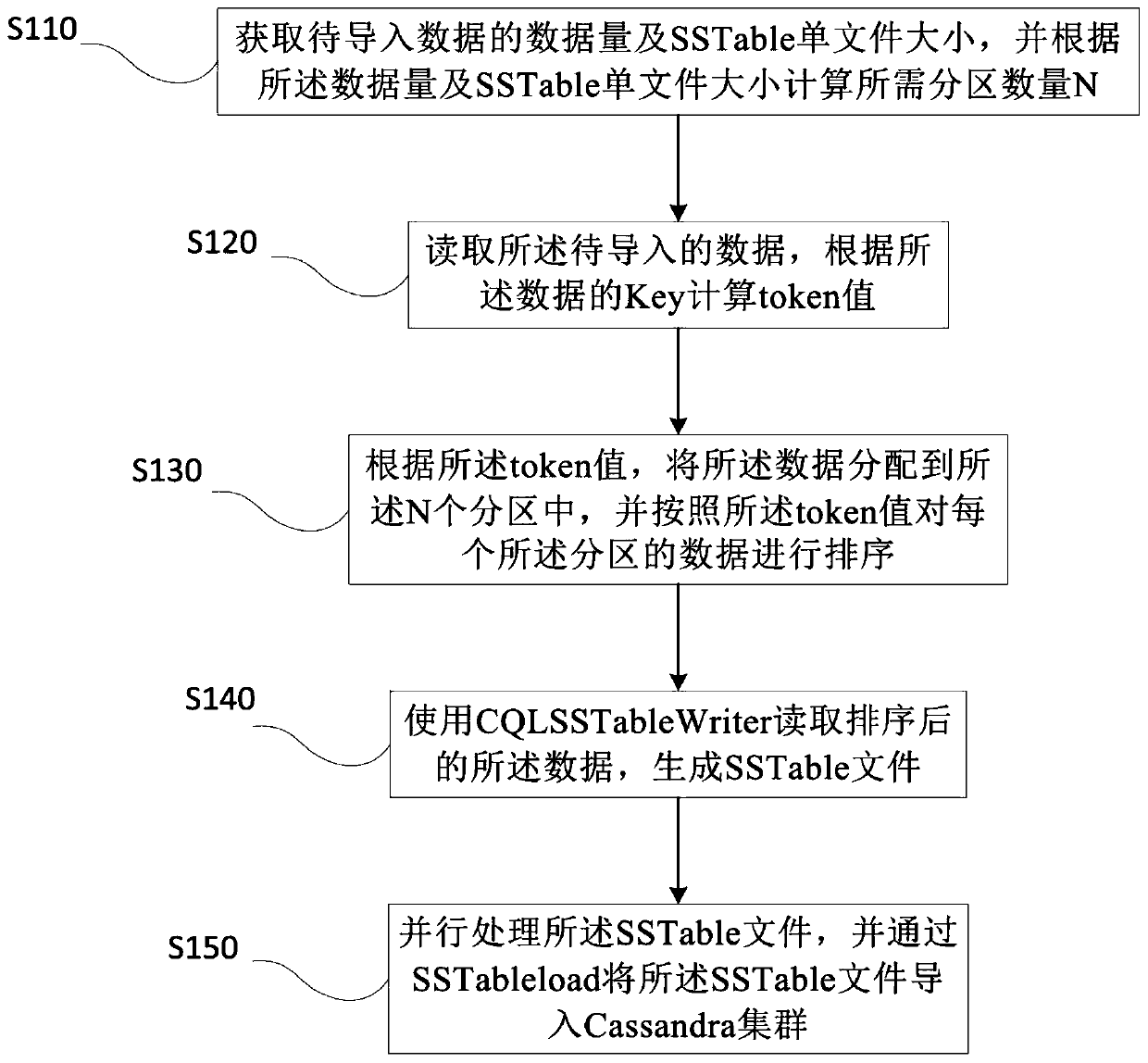
[0052] Please refer to figure 1 As shown, a Spark-based Cassandra data import method includes the following steps:
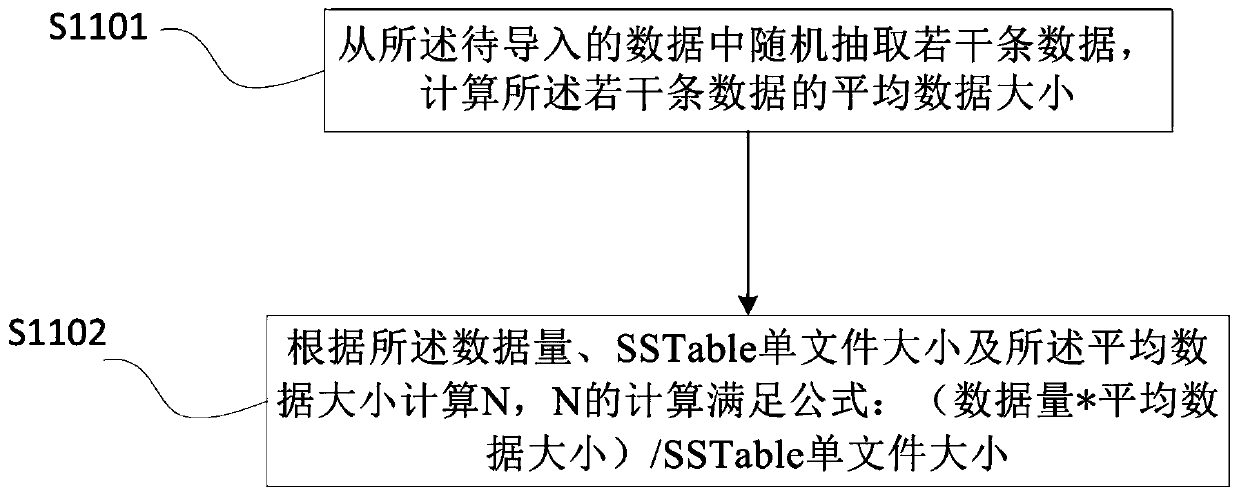
[0053] S110. Obtain the data volume of the data to be imported and the size of the SSTable single file, and calculate the required number of partitions N according to the data volume and the size of the SSTable single file;
[0054] The SSTable in S110 is the basic storage unit of Cassandra. The size of a sing...
Embodiment 2
[0081] The second embodiment is carried out on the basis of the first embodiment, and it mainly improves the parallel processing process.
[0082] After Spark completes partition (partition) interval calculation and shuffle partition sorting, that is, after completing steps S110-S130, when directly using CQLSSTableWriter+SSTableLoader to import data to Cassandra, the degree of parallelism and traffic are difficult to control, which affects the performance of the Cassandra cluster.
[0083] Therefore, in this embodiment, after the SSTable file is generated in step S140 of the first embodiment, a step of copying the SSTable file to the distributed file system is added, and the copy path is recorded, so as to control the parallel number.
[0084] The distributed file system in this embodiment selects hdfs.
[0085] Please refer to Figure 4 As shown, it specifically includes the following steps:
[0086] S210. Calculate the parallel number M according to the number of Cassandra...
Embodiment 3
[0096] Embodiment three discloses a device corresponding to the Spark-based Cassandra data import method corresponding to the above embodiment, which is the virtual device structure of the above embodiment, please refer to Figure 5 shown, including:
[0097]The partition calculation module 310 is used to obtain the amount of data and the size of the SSTable single file, and calculate the required number of partitions N according to the amount of data and the size of the SSTable single file;
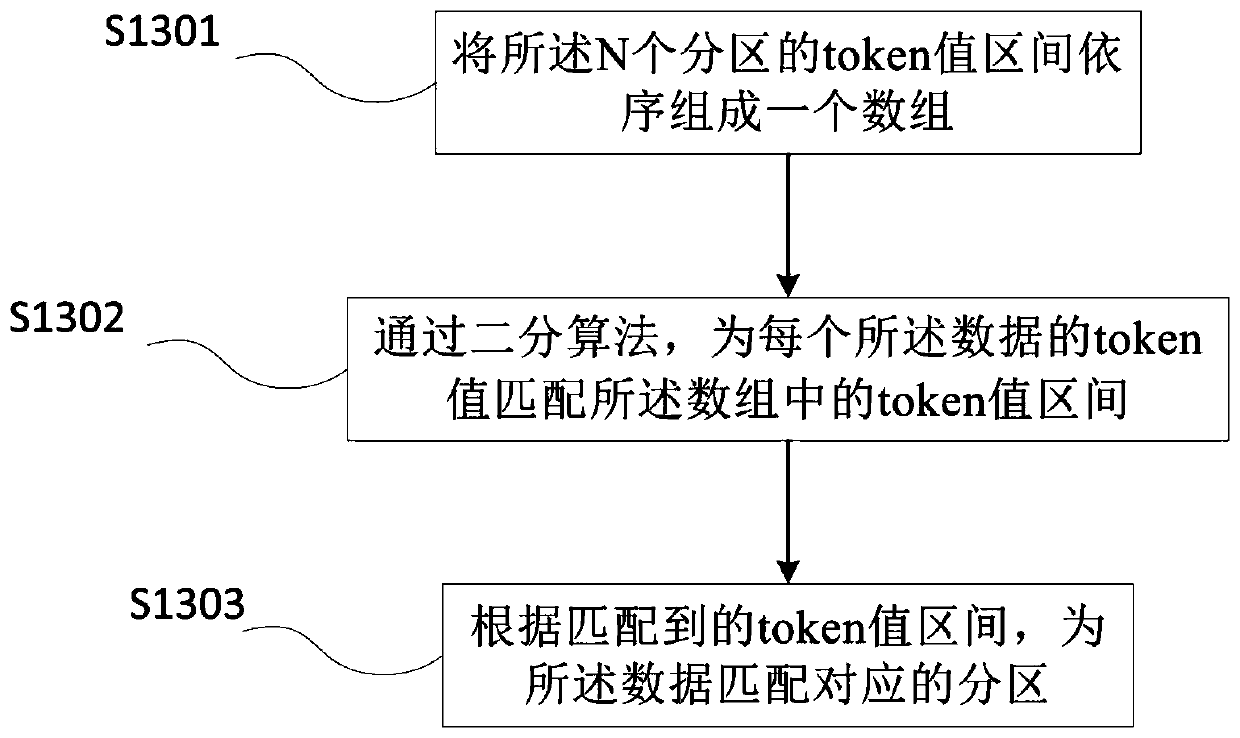
[0098] The partition allocation module 320 is used to read data, and calculate a token value according to the Key of the data; according to the token value, distribute the data to the N partitions, and assign each partition according to the token value Sort the data of the above partitions;
[0099] File generation module 330, for using CQLSSTableWriter to read the data after sorting, generate SSTable file;
[0100] The file import module 340 is configured to import the SSTable file in...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com