


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Edge device-oriented voice recognition-synthesis joint modeling method
A speech recognition and edge device technology, applied in the field of speech recognition-synthesis combined modeling, can solve the problems of lack of model performance, operational process loopholes, poor input data characteristics, etc., to achieve rich processing capabilities, robust performance, model Robustness guaranteed effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0029] Below in conjunction with accompanying drawing and embodiment the present invention is further described, but the present invention is not limited to following embodiment:
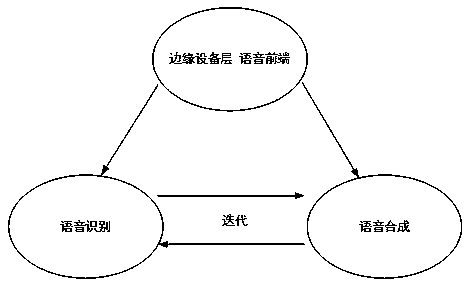
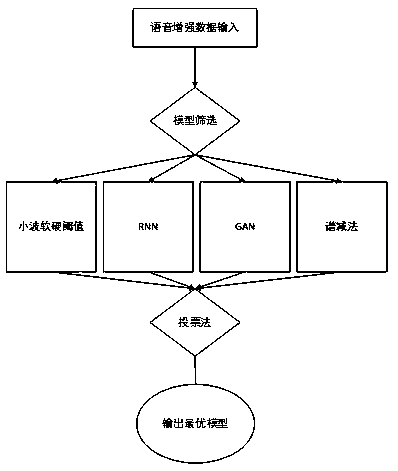
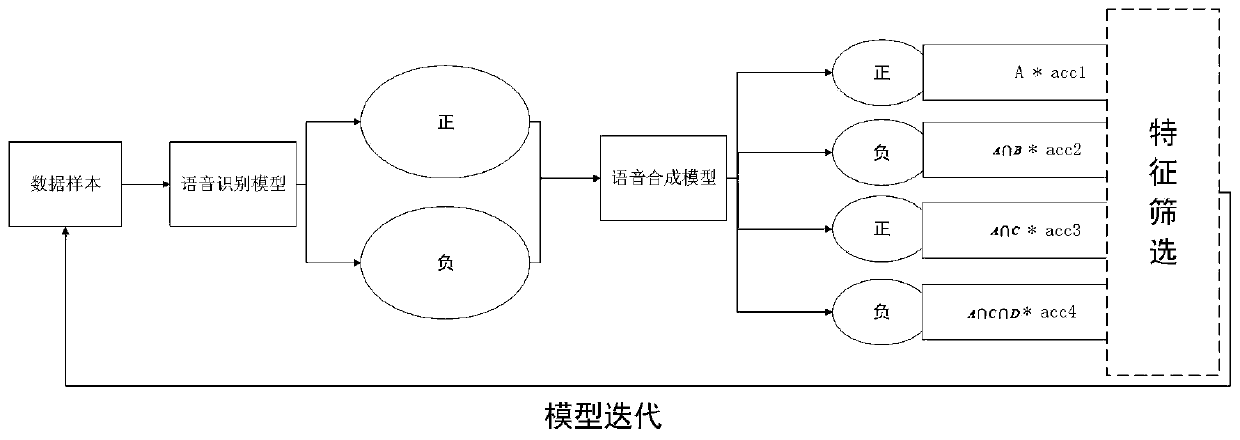
[0030] Such as figure 1 , 2 , 3, an edge device-oriented speech recognition-synthesis joint modeling method, including the following steps:
[0031] 1) Collect a dataset sample. Divided into a. Clean audio in a quiet environment b. Different types of noise audio (specifically involved: white noise, pink noise, speech babble, etc., refer to the noise noise library for classification) All audio data are sampling rate 16k, storage format pcm ( Shaanxi, Minnan, Changsha, Sichuan, Hebei, Shanghai dialects);
[0032] 2) Perform data processing. First do noise fusion processing, add noise to clean audio, package and assemble into clean audio and corresponding noise-added audio;
[0033] 3) Build an edge server, do audio front-end processing on this layer of equipment to perform reverberation, noise re...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com