Method and system for optimizing speech recognition acoustic model, equipment and storage media
An acoustic model and speech recognition technology, applied in the computer field, can solve the problems that affect the quality of the annotation, and the optimization of the acoustic model has not yet been found, and achieve the effect of improving the quality of the annotation, optimizing the acoustic model, and improving the accuracy.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
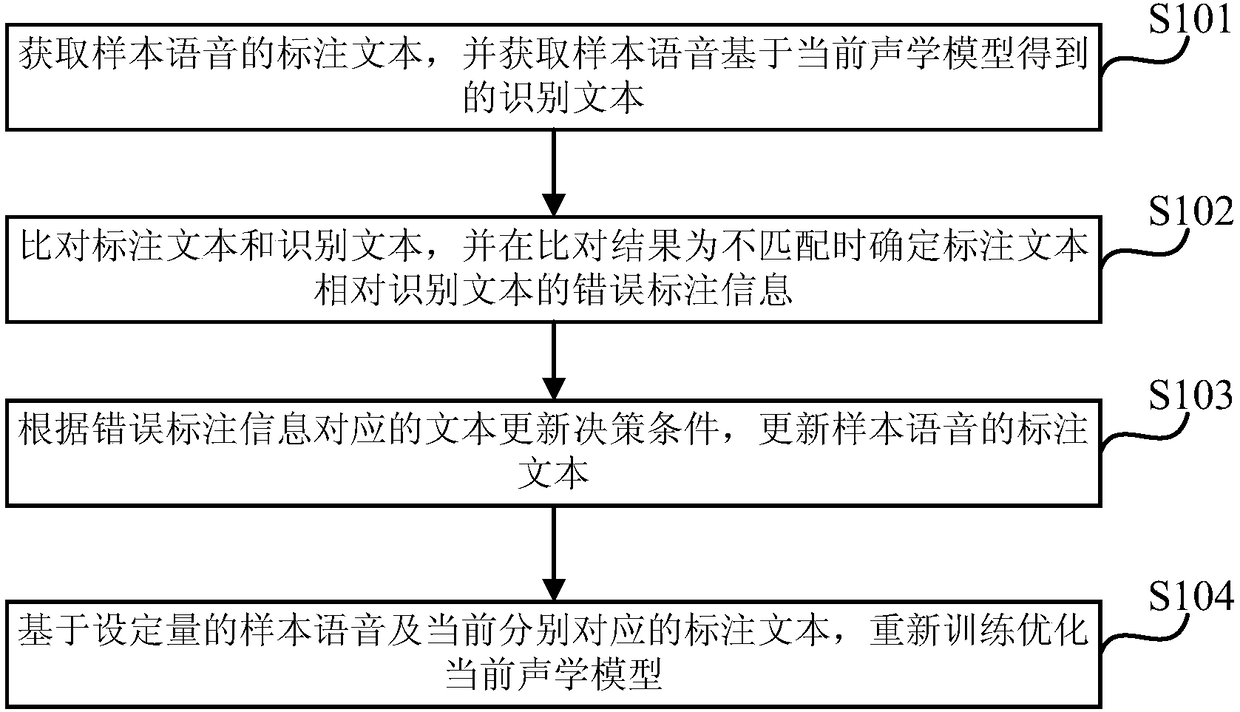
[0028] figure 1 It is a schematic flowchart of a method for optimizing an acoustic model for speech recognition provided by Embodiment 1 of the present invention. The method is applicable to the situation of optimizing and upgrading the acoustic model for speech recognition, and the method can be executed by a device for optimizing the acoustic model for speech recognition, which can be implemented by hardware and / or software, and is generally integrated in a device with a speech recognition function in computer equipment.
[0029] Such as figure 1 As shown, a method for optimizing an acoustic model for speech recognition provided by Embodiment 1 of the present invention includes the following operations:
[0030] S101. Obtain the labeled text of the sample speech, and obtain the recognition text of the sample speech based on the current acoustic model.
[0031] It can be understood that the sample speech is equivalent to a piece of speech data in the speech data set requir...
Embodiment 2
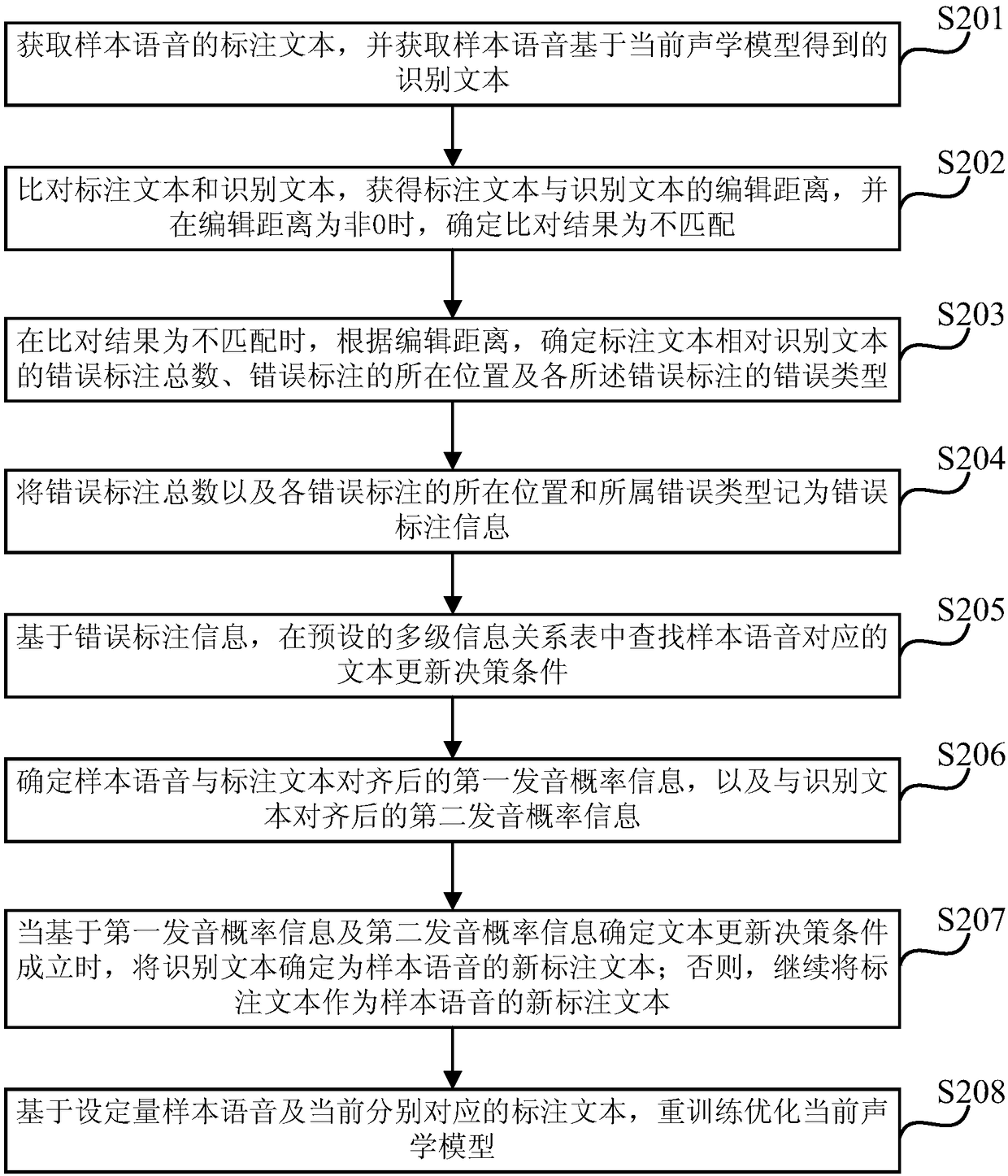
[0043] figure 2 It is a schematic flowchart of a method for optimizing an acoustic model for speech recognition provided by Embodiment 2 of the present invention. The embodiment of the present invention is optimized on the basis of the above-mentioned embodiments. In this embodiment, the marked text and the recognized text are further compared, and when the comparison result is a mismatch, it is determined that the marked text is relatively The wrong annotation information of the recognized text is embodied as: comparing the marked text and the recognized text, obtaining the edit distance between the marked text and the recognized text, and determining the comparison result when the edit distance is non-zero No match; when the comparison result is no match, according to the edit distance, determine the total number of wrong labels of the labeled text relative to the recognized text, the location of the wrong labels and the error type of each wrong label ; Record the total nu...
Embodiment 3
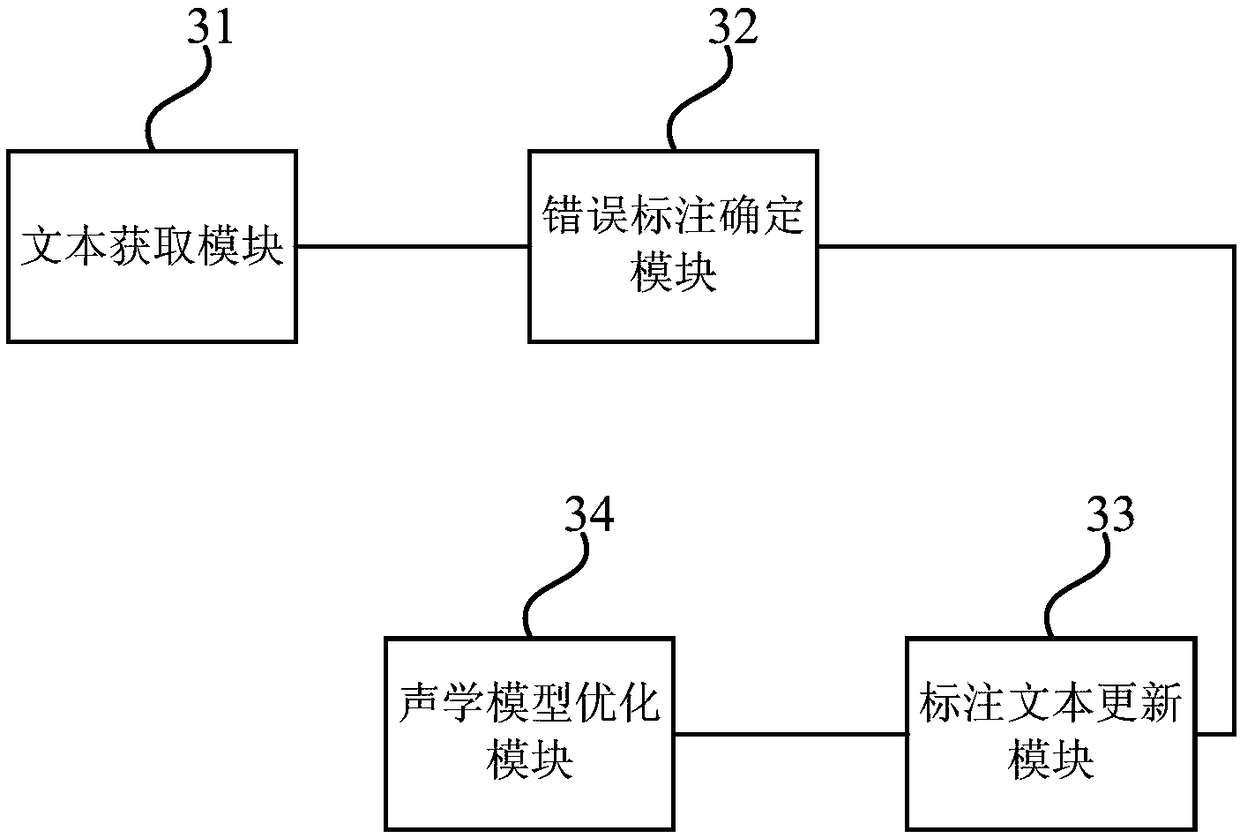
[0098] image 3 A structural block diagram of a device for optimizing an acoustic model for speech recognition provided in Embodiment 3 of the present invention, the device is suitable for optimizing and upgrading the acoustic model for speech recognition, and the device can be implemented by hardware and / or software, And generally integrated in the computer equipment with speech recognition function. Such as image 3 As shown, the device includes: a text acquisition module 31 , a wrong label determination module 32 , a label text update module 33 and an acoustic model optimization module 34 .
[0099] Wherein, the text obtaining module 31 is used to obtain the marked text of the sample speech, and obtain the recognition text obtained based on the current acoustic model of the sample speech;
[0100] An incorrect label determination module 32, configured to compare the labeled text with the recognized text, and determine the wrong labeled information of the labeled text rela...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com